Entries tagged as freesoftware
23c3 berlin ccc compiz drm dvb jugendumweltbewegung jukss königswusterhausen ökologie science theory tpm wiki 27c3 cellular frequency fsfe gsm lessig mobilephones openbsc openbts osmocombb privacy security wiretapping 3d aiglx blob driver gentoo graphics hardware linux metacity nouveau nvidia opengl xgl xorg 3ddrucker freiegesellschaft rapidprototyping reprap sciencefiction society adobe botnetz bsi evince flash kpdf leak marketing okular password passwort pdf poppler schlangenöl sicherheit snakeoil sumatrapdf zugangsdaten amusementpark asia beijing china cinderella copyright disney disneyland fake shijingshan stepmania travel trip2011 almaty asia2013 aviation azerbaijan baikal belarus border bus capsulehotel caspian ccp censorship childrensday chinghai climatechange coach dam dunhuang ecology erenhot erlian ferry flying greatfirewall guangzhou haikou hainan hohhot hongkong hostel hotel irkutsk journey kazakhstan khorgas kualalumpur language laos lenin listwjanka malaysia metro miradormansion mongolia moscow petropavl poland portbaikal publictransport pyramid qwerty rain rainforest russia sanya seat61 suprememaster terracottawarriors thailand tiananmen ticket train tram transport transsib transsiberian travelling typhoon ulaanbaatar ulan-ude ulanude urumqi vegan vegetarian visa warsaw waterpower weather windenergy xian xinjiang yanoda yekaterinburg yining zamyn-uud zensur ati ffmpeg gatos laptop presse r300 radeon randr12 tv tvout backnang ccwn film installparty kino kubuntu lug macos murrhardt softwarefreedomday ubuntu vista waiblingen windows base64 bash css script web altushost heartbleed ircbot malware openssl shellbot shellshock vulnerability 129a 1mai 24c3 a100 abgeordnetenhaus akongress akw allianz anarchiekongress antiatom atheismus atomkraft autobahn bahnhof belene bild brandenburg bundestagunited buskampagne bz creativecommons dataretention datenschutz demonstration dose elephantsdream energie energietisch energiewende freeculture freedomnotfear freifunk freiheitstattangst frequencies gott informationsfreiheit itu kamera kameraüberwachung kernkraft klima klimaschutz klimawandel kohle kohlekraft kongress kyoto mcplanet moleculeman musik ökostrom openstreetmap osm papst peterschaar piratenpartei polizeigewalt preise privatsphäre ratzinger re-publica re-publica09 religion rp09 rwe sony springer strom stromnetz tagebaue taz thermen topberlin treptow tuberlin überwachung umwelt umweltschutz unserwasser urgewald verkehr videoüberwachung volksbegehren vorratsdatenspeicherung wahl wasser wg windowsxp wirklimaretter wos wos4 youtube zimmer beryl compizfusion composite bios 1und1 benchmark cd dmidecode dvd eltorito grub harddisk iso lenovo memdisk mod motherboard optiarc pciids performance sata ssd syslinux t61 thinkpad bonn froscon froscon2007 siegburg talk bufferoverflow addresssanitizer afl americanfuzzylop asan c clang fuzzing gcc gimp memorysafety sunras useafterfree camera canon chdk digitalcamera english gadgets gammu gnokii gphoto ixus mobile nokia ptp time saturn 4k assembler bewußtsein braunschweig bsideshn c4 ca cctv certificate cryptography darmstadt easterhegg encryption entropia gpn gpn5 gpn6 gpn7 hacker hannover hash https karlsruhe licenses md5 mrmcd mrmcd100b mrmcd101b mysmartgrid papierlos passwörter pgp philosophie programmieren programming publicdomain querfunk radio rsa rsaoaep rsapss server sha1 slides ssl stuttgart surveillance tls transvalid überwachungskameras unicode utf-8 vortrag wahlcomputer wahlmaschinen wiesbaden x509 chemnitz clt lpi messe babelfish boluo boten casino chinese coffee copycat freizeitpark ghosttown googletranslate hallstatt huizhou journalismus luoyang mandarin northwestchina pressefreiheit russian tagesschau translation universaltranslator chromium chrome crash cve debian diffiehellman firefox forwardsecrecy ghost glibc keyexchange php redhat cinelerra gkm kohlekraftwerk mannheim thesource video videoediting code csrf freewvs sizeof xss codecs realmedia realvideo rv30 rv40 augsburg cacert come2linux essen games inkscape kde lit07 luga wine compression rar theunarchiver unar console homebrew wii wiibrew 68 aacs abmahnung alecempire aliens art banksy barrierefrei berneconvention bittorrent bitv blueray brigittezypries buch bücher bundestag cedric chaosradio corruptibles cpdl culturalflatrate culture di ebook epetition eu eucopyrightdirective evrimsen fanart fanfiction filesharing funkerspuk gema gemavermutung geodaten graffiti gutenberg gvl hddvd hiddenfrontier html ifpi illegalart iromance jankroemer justizministerium kinderlieder kopierschutz kriegderwelten kts kultur laterne laternenumzug markenrecht metis movies mpaa musikindustrie musikpiraten negativland netradio nocopy patent patente penguinbooks petition piratbyrån piratebay politik radiopolitik raubdruck raubkopie remix sanktmartin savenetradio spiritlevel startrek thepiratebay tomcruise trips tuxmas tuxmas07 usa usbstick verwertungsgesellschaft vgmusikeditionen vgwort vlc w3c warez webradio wipo wizo aavepyörä br breakcore copycan developingworld fdl freemusic fruechtedeszorns goa internet jamendo license microsoft movie nerosdaysatdisneyland ogg paniq pioneerone planet presserat python series vorbis breach cookies crime heist moodle s9y samesite serendipity websecurity accessibility heise internetexplorer max_width webdesign gobi helma javascript ddwrt firmware gargoyle router apt deb distributions fedora fma86t gnupg gpg notebook openpgp packagemanagement rpm signatures wlan desktop gnome mandriva metisse cardreader memorystick pcmcia ricoh samsung sd sdricohcs exe ico icons icoutils wrestool ape audacious fileformats flv gstreamer imagemagick konqueror legacy libav monkeysaudio mplayer multimedia realaudio retro retrocomputing shn shorten totem vc-1 voc vqf win32codecs wmv xine comic deathproof dvdr emilyrose enigma esoterik exorzismus filmkritik fluchderkaribik grindhouse homosexualität jacksparrow johnnydepp keiraknightley kirche marvel mond mondverschwörung orlandobloom piraten piratesofthecaribbean planetterror rodriguez spiderman superman tarantino turing verschwörungstheorie werbung berserk bleichenbacher browser clickjacking ftp mozilla nss poodle xsa zzuf france nancy rmll geo gps afra spam webapps wordpress bahn gedelitz modding p30 wendland wendlandcamp fsf lightwerk patents softwarepatents stallman gaia google googleearth reverseengineering arcade computergames computerspiele donkeykong escapa gajim gameandwatch gameboy instantmessaging jabber konsole konsolen lemmings lucasarts luigi mario monkeyisland nes nintendo nintendo64 olpc retrogames retrogaming scumm simcity spiele supermario supermariogalaxy tictactoe videogames xmpp zkm ac100 android developer freedomofspeech gebabbel gpsbabel idn iputils josm libressl merkaartor mobiletrailexplorer openbsd ping politics smartbook subnotebook toshiba x1carbon freedesktop gtk kgtk qt standards usability bypass geographie googlemaps passwordalert atm display dsl energiesparen garmin hddtemp lm_sensors lspci lsusb mapsource ntbba p35 quest routing support usbids ibm windowsrefund ngm scientology sekten universellesleben vogelgrippe grenzendeswachstums peakoil wachstum wachstumskritik agenda21 apache barcamp blog bnn bodensee bundesverfassungsgericht co2 datensparsamkeit ejc enbw fricard gamer geocaching informationdisclosure jonglieren killerspiele kubik mysql openexpo opensourceexpo press rfid rhein simplesharingextensions stadtmitte steinkohle uni web20 webmontag akademy ct esslingen ludwigsburg ice modem steckdose winmodem artikel augsburgerallgemeine core coredump cpu cpufreq delilinux demoscene distribution frankreich grsecurity howto hp http iptables lpic lugbk network omnibook overheatd overheating pcmagazin proxy schokokeks segfault smart smartmontools sncf squid symlink usb webhosting webinale webroot webserver zeitung webinale07 etymologie schäuble wga argentinia cinema cubacrisis magneto nazi prequel xmen xmenfirstclass echoes nessus openvas anarchismus auto benken benzin biblis bookchin brunsbüttel castor deutschewelle endlager energiesparlampe flughafen gentechnik gorleben grüne hamburg hitzacker kapitalismus klimacamp kompaktleuchtstoffröhre led loremo mainz marslight mon810 monsanto moorburg nürtingen oberboihingen pkw schlemm schweiz stromsparen stromverbrauch tiefenökologie umweltbewegung verkehrspolitik weinland xq certificateauthority email privatekey rc2 smime sni symantec badcannstatt cannstatt cccs earth exif geotagging gpx jpeg kaisersbach mars media osm2poly osmosis rtl sfd spiegel tomorrow phoronix content-security-policy cookie csp drupal gallery infoleak mantis pdo session sniffing squirrelmail stacktrace schwäbischestaglatt sexismus agb antigenozidbewegung aok datamining db diy einkaufen frankfurt hausdurchsuchung humanistischeunion innenpolitik justiz key köln mobil optoutday rechtsbeugung richtervorbehalt schlüssel sha2 steuerid steuernummer verschlüsselung 3dprinter ikea obsolescence recycling repair atari blinkenlights brownbox computerhistory magistral museum painstation pong pongmechanik pongmythos tankodrom wkv blowfish onlinetvrecorder otrkey schneier cablemodem climate d-link efficiency eletricity environment firewall kabeldeutschland o2 tcp zyxel sqlinjection 0days bias busby conflictofinterest hacking journalism rand study vulnerabilities zerodays adguard aead aes algorithm antivir antivirus auskunftsanspruch axfr azure badkeys bigbluebutton bugbounty bundesdatenschutzgesetz bundestrojaner cbc cccamp11 cfb chcounter clamav cloudflare cmi cms crypto dell deolalikar dingens diploma diplomarbeit dns domain edellroot eff eplus facebook fileexfiltration fortigate fortinet freak git gnutls gsoc hackerone internetscan itsecurity jodconverter joomla kaspersky komodia libreoffice luckythirteen maninthemiddle math mephisto milleniumproblems mitm modulobias napster netfiltersdk newspaper nist ntp ntpd observatory onlinedurchsuchung openid openidconnect openleaks otr owncloud padding panda phishing pnp privdog protocolfilters provablesecurity pss random rss salinecourier sha256 sha512 snallygaster sso staatsanwaltschaft subdomain superfish thesis tlsdate toendacms unicef update updates userdir virus calendar ipv6 mod_rewrite architecture astana baiterek crookedforest forest gryfino khanshatyry migrationpolice nature places ard ardget audio cartoon deutschland download feuerwerk filter fireworks flvstreamer fußball kapitalismuskritik kickit krisis mediathek mitschnitt nationalismus rtmp rtmpdump theorie wm bugtracker github nextcloud acid3 midori webkit webstandards esowatch skeptizismus absturz okte
Friday, January 30. 2015
What the GHOST tells us about free software vulnerability management
 On Tuesday details about the security vulnerability GHOST in Glibc were published by the company Qualys. When severe security vulnerabilities hit the news I always like to take this as a chance to learn what can be improved and how to avoid similar incidents in the future (see e. g. my posts on Heartbleed/Shellshock, POODLE/BERserk and NTP lately).
On Tuesday details about the security vulnerability GHOST in Glibc were published by the company Qualys. When severe security vulnerabilities hit the news I always like to take this as a chance to learn what can be improved and how to avoid similar incidents in the future (see e. g. my posts on Heartbleed/Shellshock, POODLE/BERserk and NTP lately).GHOST itself is a Heap Overflow in the name resolution function of the Glibc. The Glibc is the standard C library on Linux systems, almost every software that runs on a Linux system uses it. It is somewhat unclear right now how serious GHOST really is. A lot of software uses the affected function gethostbyname(), but a lot of conditions have to be met to make this vulnerability exploitable. Right now the most relevant attack is against the mail server exim where Qualys has developed a working exploit which they plan to release soon. There have been speculations whether GHOST might be exploitable through Wordpress, which would make it much more serious.
Technically GHOST is a heap overflow, which is a very common bug in C programming. C is inherently prone to these kinds of memory corruption errors and there are essentially two things here to move forwards: Improve the use of exploit mitigation techniques like ASLR and create new ones (levee is an interesting project, watch this 31C3 talk). And if possible move away from C altogether and develop core components in memory safe languages (I have high hopes for the Mozilla Servo project, watch this linux.conf.au talk).
GHOST was discovered three times
But the thing I want to elaborate here is something different about GHOST: It turns out that it has been discovered independently three times. It was already fixed in 2013 in the Glibc Code itself. The commit message didn't indicate that it was a security vulnerability. Then in early 2014 developers at Google found it again using Address Sanitizer (which – by the way – tells you that all software developers should use Address Sanitizer more often to test their software). Google fixed it in Chrome OS and explicitly called it an overflow and a vulnerability. And then recently Qualys found it again and made it public.
Now you may wonder why a vulnerability fixed in 2013 made headlines in 2015. The reason is that it widely wasn't fixed because it wasn't publicly known that it was serious. I don't think there was any malicious intent. The original Glibc fix was probably done without anyone noticing that it is serious and the Google devs may have thought that the fix is already public, so they don't need to make any noise about it. But we can clearly see that something doesn't work here. Which brings us to a discussion how the Linux and free software world in general and vulnerability management in particular work.
The “Never touch a running system” principle
Quite early when I came in contact with computers I heard the phrase “Never touch a running system”. This may have been a reasonable approach to IT systems back then when computers usually weren't connected to any networks and when remote exploits weren't a thing, but it certainly isn't a good idea today in a world where almost every computer is part of the Internet. Because once new security vulnerabilities become public you should change your system and fix them. However that doesn't change the fact that many people still operate like that.
A number of Linux distributions provide “stable” or “Long Time Support” versions. Basically the idea is this: At some point they take the current state of their systems and further updates will only contain important fixes and security updates. They guarantee to fix security vulnerabilities for a certain time frame. This is kind of a compromise between the “Never touch a running system” approach and reasonable security. It tries to give you a system that will basically stay the same, but you get fixes for security issues. Popular examples for this approach are the stable branch of Debian, Ubuntu LTS versions and the Enterprise versions of Red Hat and SUSE.
To give you an idea about time frames, Debian currently supports the stable trees Squeeze (6.0) which was released 2011 and Wheezy (7.0) which was released 2013. Red Hat Enterprise Linux has currently 4 supported version (4, 5, 6, 7), the oldest one was originally released in 2005. So we're talking about pretty long time frames that these systems get supported. Ubuntu and Suse have similar long time supported Systems.
These systems are delivered with an implicit promise: We will take care of security and if you update regularly you'll have a system that doesn't change much, but that will be secure against know threats. Now the interesting question is: How well do these systems deliver on that promise and how hard is that?
Vulnerability management is chaotic and fragile
I'm not sure how many people are aware how vulnerability management works in the free software world. It is a pretty fragile and chaotic process. There is no standard way things work. The information is scattered around many different places. Different people look for vulnerabilities for different reasons. Some are developers of the respective projects themselves, some are companies like Google that make use of free software projects, some are just curious people interested in IT security or researchers. They report a bug through the channels of the respective project. That may be a mailing list, a bug tracker or just a direct mail to the developer. Hopefully the developers fix the issue. It does happen that the person finding the vulnerability first has to explain to the developer why it actually is a vulnerability. Sometimes the fix will happen in a public code repository, sometimes not. Sometimes the developer will mention that it is a vulnerability in the commit message or the release notes of the new version, sometimes not. There are notorious projects that refuse to handle security vulnerabilities in a transparent way. Sometimes whoever found the vulnerability will post more information on his/her blog or on a mailing list like full disclosure or oss-security. Sometimes not. Sometimes vulnerabilities get a CVE id assigned, sometimes not.
Add to that the fact that in many cases it's far from clear what is a security vulnerability. It is absolutely common that if you ask the people involved whether this is serious the best and most honest answer they can give is “we don't know”. And very often bugs get fixed without anyone noticing that it even could be a security vulnerability.
Then there are projects where the number of security vulnerabilities found and fixed is really huge. The latest Chrome 40 release had 62 security fixes, version 39 had 42. Chrome releases a new version every two months. Browser vulnerabilities are found and fixed on a daily basis. Not that extreme but still high is the vulnerability count in PHP, which is especially worrying if you know that many webhosting providers run PHP versions not supported any more.
So you probably see my point: There is a very chaotic stream of information in various different places about bugs and vulnerabilities in free software projects. The number of vulnerabilities is huge. Making a promise that you will scan all this information for security vulnerabilities and backport the patches to your operating system is a big promise. And I doubt anyone can fulfill that.
GHOST is a single example, so you might ask how often these things happen. At some point right after GHOST became public this excerpt from the Debian Glibc changelog caught my attention (excuse the bad quality, had to take the image from Twitter because I was unable to find that changelog on Debian's webpages):

What you can see here: While Debian fixed GHOST (which is CVE-2015-0235) they also fixed CVE-2012-6656 – a security issue from 2012. Admittedly this is a minor issue, but it's a vulnerability nevertheless. A quick look at the Debian changelog of Chromium both in squeeze and wheezy will tell you that they aren't fixing all the recent security issues in it. (Debian already had discussions about removing Chromium and in Wheezy they don't stick to a single version.)
It would be an interesting (and time consuming) project to take a package like PHP and check for all the security vulnerabilities whether they are fixed in the latest packages in Debian Squeeze/Wheezy, all Red Hat Enterprise versions and other long term support systems. PHP is probably more interesting than browsers, because the high profile targets for these vulnerabilities are servers. What worries me: I'm pretty sure some people already do that. They just won't tell you and me, instead they'll write their exploits and sell them to repressive governments or botnet operators.
Then there are also stories like this: Tavis Ormandy reported a security issue in Glibc in 2012 and the people from Google's Project Zero went to great lengths to show that it is actually exploitable. Reading the Glibc bug report you can learn that this was already reported in 2005(!), just nobody noticed back then that it was a security issue and it was minor enough that nobody cared to fix it.
There are also bugs that require changes so big that backporting them is essentially impossible. In the TLS world a lot of protocol bugs have been highlighted in recent years. Take Lucky Thirteen for example. It is a timing sidechannel in the way the TLS protocol combines the CBC encryption, padding and authentication. I like to mention this bug because I like to quote it as the TLS bug that was already mentioned in the specification (RFC 5246, page 23: "This leaves a small timing channel"). The real fix for Lucky Thirteen is not to use the erratic CBC mode any more and switch to authenticated encryption modes which are part of TLS 1.2. (There's another possible fix which is using Encrypt-then-MAC, but it is hardly deployed.) Up until recently most encryption libraries didn't support TLS 1.2. Debian Squeeze and Red Hat Enterprise 5 ship OpenSSL versions that only support TLS 1.0. There is no trivial patch that could be backported, because this is a huge change. What they likely backported are workarounds that avoid the timing channel. This will stop the attack, but it is not a very good fix, because it keeps the problematic old protocol and will force others to stay compatible with it.
LTS and stable distributions are there for a reason
The big question is of course what to do about it. OpenBSD developer Ted Unangst wrote a blog post yesterday titled Long term support considered harmful, I suggest you read it. He argues that we should get rid of long term support completely and urge users to upgrade more often. OpenBSD has a 6 month release cycle and supports two releases, so one version gets supported for one year.
Given what I wrote before you may think that I agree with him, but I don't. While I personally always avoided to use too old systems – I 'm usually using Gentoo which doesn't have any snapshot releases at all and does rolling releases – I can see the value in long term support releases. There are a lot of systems out there – connected to the Internet – that are never updated. Taking away the option to install systems and let them run with relatively little maintenance overhead over several years will probably result in more systems never receiving any security updates. With all its imperfectness running a Debian Squeeze with the latest updates is certainly better than running an operating system from 2011 that stopped getting security fixes in 2012.
Improving the information flow
I don't think there is a silver bullet solution, but I think there are things we can do to improve the situation. What could be done is to coordinate and share the work. Debian, Red Hat and other distributions with stable/LTS versions could agree that their next versions are based on a specific Glibc version and they collaboratively work on providing patch sets to fix all the vulnerabilities in it. This already somehow happens with upstream projects providing long term support versions, the Linux kernel does that for example. Doing that at scale would require vast organizational changes in the Linux distributions. They would have to agree on a roughly common timescale to start their stable versions.
What I'd consider the most crucial thing is to improve and streamline the information flow about vulnerabilities. When Google fixes a vulnerability in Chrome OS they should make sure this information is shared with other Linux distributions and the public. And they should know where and how they should share this information.
One mechanism that tries to organize the vulnerability process is the system of CVE ids. The idea is actually simple: Publicly known vulnerabilities get a fixed id and they are in a public database. GHOST is CVE-2015-0235 (the scheme will soon change because four digits aren't enough for all the vulnerabilities we find every year). I got my first CVEs assigned in 2007, so I have some experiences with the CVE system and they are rather mixed. Sometimes I briefly mention rather minor issues in a mailing list thread and a CVE gets assigned right away. Sometimes I explicitly ask for CVE assignments and never get an answer.
I would like to see that we just assign CVEs for everything that even remotely looks like a security vulnerability. However right now I think the process is to unreliable to deliver that. There are other public vulnerability databases like OSVDB, I have limited experience with them, so I can't judge if they'd be better suited. Unfortunately sometimes people hesitate to request CVE ids because others abuse the CVE system to count assigned CVEs and use this as a metric how secure a product is. Such bad statistics are outright dangerous, because it gives people an incentive to downplay vulnerabilities or withhold information about them.
This post was partly inspired by some discussions on oss-security
Monday, October 6. 2014
How to stop Bleeding Hearts and Shocking Shells
 The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.
The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.Heartbleed hit the news in April this year. A bug in OpenSSL that allowed to extract privat keys of encrypted connections. When a bug in Bash called Shellshock hit the news I was first hesistant to call it bigger than Heartbleed. But now I am pretty sure it is. While Heartbleed was big there were some things that alleviated the impact. It took some days till people found out how to practically extract private keys - and it still wasn't fast. And the most likely attack scenario - stealing a private key and pulling off a Man-in-the-Middle-attack - seemed something that'd still pose some difficulties to an attacker. It seemed that people who update their systems quickly (like me) weren't in any real danger.
Shellshock was different. It's astonishingly simple to use and real attacks started hours after it became public. If circumstances had been unfortunate there would've been a very real chance that my own servers could've been hit by it. I usually feel the IT stuff under my responsibility is pretty safe, so things like this scare me.
What OpenSSL and Bash have in common
Shortly after Heartbleed something became very obvious: The OpenSSL project wasn't in good shape. The software that pretty much everyone in the Internet uses to do encryption was run by a small number of underpaid people. People trying to contribute and submit patches were often ignored (I know that, I tried it). The truth about Bash looks even grimmer: It's a project mostly run by a single volunteer. And yet almost every large Internet company out there uses it. Apple installs it on every laptop. OpenSSL and Bash are crucial pieces of software and run on the majority of the servers that run the Internet. Yet they are very small projects backed by few people. Besides they are both quite old, you'll find tons of legacy code in them written more than a decade ago.
People like to rant about the code quality of software like OpenSSL and Bash. However I am not that concerned about these two projects. This is the upside of events like these: OpenSSL is probably much securer than it ever was and after the dust settles Bash will be a better piece of software. If you want to ask yourself where the next Heartbleed/Shellshock-alike bug will happen, ask this: What projects are there that are installed on almost every Linux system out there? And how many of them have a healthy community and received a good security audit lately?
Software installed on almost any Linux system
Let me propose a little experiment: Take your favorite Linux distribution, make a minimal installation without anything and look what's installed. These are the software projects you should worry about. To make things easier I did this for you. I took my own system of choice, Gentoo Linux, but the results wouldn't be very different on other distributions. The results are at at the bottom of this text. (I removed everything Gentoo-specific.) I admit this is oversimplifying things. Some of these provide more attack surface than others, we should probably worry more about the ones that are directly involved in providing network services.
After Heartbleed some people already asked questions like these. How could it happen that a project so essential to IT security is so underfunded? Some large companies acted and the result is the Core Infrastructure Initiative by the Linux Foundation, which already helped improving OpenSSL development. This is a great start and an example for an initiative of which we should have more. We should ask the large IT companies who are not part of that initiative what they are doing to improve overall Internet security.
Just to put this into perspective: A thorough security audit of a project like Bash would probably require a five figure number of dollars. For a small, volunteer driven project this is huge. For a company like Apple - the one that installed Bash on all their laptops - it's nearly nothing.
There's another recent development I find noteworthy. Google started Project Zero where they hired some of the brightest minds in IT security and gave them a single job: Search for security bugs. Not in Google's own software. In every piece of software out there. This is not merely an altruistic project. It makes sense for Google. They want the web to be a safer place - because the web is where they earn their money. I like that approach a lot and I have only one question to ask about it: Why doesn't every large IT company have a Project Zero?
Sparking interest
There's another aspect I want to talk about. After Heartbleed people started having a closer look at OpenSSL and found a number of small and one other quite severe issue. After Bash people instantly found more issues in the function parser and we now have six CVEs for Shellshock and friends. When a piece of software is affected by a severe security bug people start to look for more. I wonder what it'd take to have people looking at the projects that aren't in the spotlight.
I was brainstorming if we could have something like a "free software audit action day". A regular call where an important but neglected project is chosen and the security community is asked to have a look at it. This is just a vague idea for now, if you like it please leave a comment.
That's it. I refrain from having discussions whether bugs like Heartbleed or Shellshock disprove the "many eyes"-principle that free software advocates like to cite, because I think these discussions are a pointless waste of time. I'd like to discuss how to improve things. Let's start.
Here's the promised list of Gentoo packages in the standard installation:
bzip2
gzip
tar
unzip
xz-utils
nano
ca-certificates
mime-types
pax-utils
bash
build-docbook-catalog
docbook-xml-dtd
docbook-xsl-stylesheets
openjade
opensp
po4a
sgml-common
perl
python
elfutils
expat
glib
gmp
libffi
libgcrypt
libgpg-error
libpcre
libpipeline
libxml2
libxslt
mpc
mpfr
openssl
popt
Locale-gettext
SGMLSpm
TermReadKey
Text-CharWidth
Text-WrapI18N
XML-Parser
gperf
gtk-doc-am
intltool
pkgconfig
iputils
netifrc
openssh
rsync
wget
acl
attr
baselayout
busybox
coreutils
debianutils
diffutils
file
findutils
gawk
grep
groff
help2man
hwids
kbd
kmod
less
man-db
man-pages
man-pages-posix
net-tools
sed
shadow
sysvinit
tcp-wrappers
texinfo
util-linux
which
pambase
autoconf
automake
binutils
bison
flex
gcc
gettext
gnuconfig
libtool
m4
make
patch
e2fsprogs
udev
linux-headers
cracklib
db
e2fsprogs-libs
gdbm
glibc
libcap
ncurses
pam
readline
timezone-data
zlib
procps
psmisc
shared-mime-info
Wednesday, March 26. 2014
Extract base64-encoded images from CSS
Saturday, October 8. 2011
Free rar unpacking code
Sunday, August 21. 2011
The sad state of the Linux Desktop
 Some days ago it was reported that Microsoft declared it considers Linux on the desktop no longer a threat for its business. Now I usually wouldn't care that much what Microsoft is saying, but in this case, I think, they're very right – and thererfore I wonder why this hasn't raised any discussions in the free software community (at least I haven't seen one – if it has and I missed it, please provide links in the comments). So I'd like to make a start.
Some days ago it was reported that Microsoft declared it considers Linux on the desktop no longer a threat for its business. Now I usually wouldn't care that much what Microsoft is saying, but in this case, I think, they're very right – and thererfore I wonder why this hasn't raised any discussions in the free software community (at least I haven't seen one – if it has and I missed it, please provide links in the comments). So I'd like to make a start.A few years ago, I can remember that I was pretty optimistic about a Linux-based Desktop (and I think many shared my views). It seemed with advantages like being able to provide a large number of high quality applications for free and having proven to be much more resilient against security threats it was just a matter of time. I had the impression that development was often going into the right direction, just to name one example freedesktop.org was just starting to try to unify the different Linux desktop environments and make standards so KDE applications work better under GNOME and vice versa.
Today, my impression is that everything is in a pretty sad state. Don't get me wrong: Free software plays an important role on Desktops – and that's really good. Major web browsers are based on free software, applications like VLC are very successful. But the basis – the operating system – is usually a non-free one.
I recently was looking for netbooks. Some years ago, Asus came out with the Eee PC, a small and cheap laptop which ran Linux by default – one year later they provided a version with Windows as an alternative. Today, you won't find a single Netbook with Linux as the default OS. I read more often than not in recent years that public authorities trying to get along with Linux have failed.
I think I made my point; the Linux Desktop is in a sad state – I'd like to discuss why this is the case and how we (the free software community) can change it. I won't claim that I have the definite answer for the cause. I think it's a mix of things, I'd like to start with some points:
- Some people seem to see Desktop environments more as a playground for creative ideas than something other people want to use on a daily basis in a stable way. This is pretty much true for KDE 4 – the KDE team abandoned a well-working Desktop environment KDE 3.5 for something that isn't stable even today and suffers from a lot of regressions. They permanently invent new things like Akonadi and make them mandatory even for people who don't care about them – I seriously don't have an idea what it does, except throwing strange error messages at me. I switched to GNOME, but what I heard about GNOME 3 doesn't make me feel that it's much better there (I haven't tested it yet and I hope that, unlike the KDE-team, GNOME learns from that and supports 2.x until version 3 is in a state working equally well). I think Ubuntu's playing with the Unity Desktop go in the same direction: We found something cool, we'll use it, we don't care that we'll piss of a bunch of our users. In contrast to that, I have the impression that what I named above – the idea that we can integrate different desktop environments better by standards – isn't seen as important as it used to be. (I know this part may provoke flames, I hope this won't hide the other points I made)
- The driver problem. I still encounter it to be one of the biggest obstacles and it hasn't changed a bit for years. You just can't buy a piece of hardware and use it. It usually is “somehow possible”, but the default is that it requires a lot of extra geeky work that the average user will never manage. I think there's no easy solution to that, as it would require cooperation from hardware vendors (and with diminishing importance of the Linux Desktop this is likely getting harder). But a lot of things are also self-made. In 2006, Eric Raymond wrote an essay how crappy CUPS is – I think it hasn't improved since then. How often have I read Ubuntu bug reports that go like this: “My printer worked in version [last version], but it doesn't work in [current version]” - “Me too.” - “Me too.” - “Me too” - no reply from any developer. One point that this shares with the one above is the caring about regressions, which I think should be a top priority, but obviously, many in the free software community don't seem to think so. (if you don't know the word: something is called a regression if something worked in an older version of a software, but no longer works in the current version)
- The market around us has changed. Back then, we were faced with a “Windows or nothing” situation we wanted to change to a “Windows or Linux” situation. Today, we're faced with “Windows or MacOS X”. Sure, MacOS existed back then, but it only got a relevant market share in recent years (and many current or former free software developers use MacOS X now). Competition makes products better, so Windows today is not Windows back then. Our competitors just got better.
- The desktop is loosing share. This is a point often made, with mobile phones, tablets, gaming consoles and other devices taking over tasks that were done with desktop computers in the past. This is certainly true for some degree, but I think it's also often overestimated. Desktop computers still play an important role and I'm sure they will continue to do so for a long time. The discussion how free software performs on other devices (and how free Android is) is an interesting one, too, but I won't go into it for now, as I want to talk about the Desktop here.
Okay, I've started the discussion, I'd like others to join. Please remember: It's not my goal to flame or to blame anyone – my goal is to discuss how we can make the Linux desktop successful again.
Sunday, July 10. 2011
Welcome to Fake Disneyland
 Maybe you've heared that some years ago, a story about a fake Disneyland amusement park in China made some rumors in the media. As I love good fakes, I obviously had to take a look. The amusement park in question is Shijingshan Amusement Park ( 北京石景山游乐园) and is located in Beijing. It can easily be reached, as it has its own metro station.
Maybe you've heared that some years ago, a story about a fake Disneyland amusement park in China made some rumors in the media. As I love good fakes, I obviously had to take a look. The amusement park in question is Shijingshan Amusement Park ( 北京石景山游乐园) and is located in Beijing. It can easily be reached, as it has its own metro station. The park had the advertisement slogan "Disneyland is too far to go" some years ago and some images of Mickey Mouse and other Disney figures in the park boosted the story (see Wikipedia for details). Also, like all Disneylands, the Park has a Cinderella castle. It seems in the meantime things have changed - we didn't see any Disney charakters there. The only thing that still reminds of the story is the Cinderella castle - but as much as Disneys lawyers might want this, Cinderella is not a Disney invention after all.
The park had the advertisement slogan "Disneyland is too far to go" some years ago and some images of Mickey Mouse and other Disney figures in the park boosted the story (see Wikipedia for details). Also, like all Disneylands, the Park has a Cinderella castle. It seems in the meantime things have changed - we didn't see any Disney charakters there. The only thing that still reminds of the story is the Cinderella castle - but as much as Disneys lawyers might want this, Cinderella is not a Disney invention after all.I even found a fake Mickey Mouse (at least I think it was fake, it looked somehow wrong) in Beijing, but it was not in the amusement park, it was in the olympic village.
 The story of a fake Disneyland seems highly exaggerated. The Cinderella is probably no issue at all, as I doubt there's anything that makes it a special "Disney-Cinderella". I'm not sure if there was a copyright violation at all: The fake Mickey Mouse and other figures in combination with the solgan could probably be considered parody - which is legally allowed in most of the world's copyright laws.
The story of a fake Disneyland seems highly exaggerated. The Cinderella is probably no issue at all, as I doubt there's anything that makes it a special "Disney-Cinderella". I'm not sure if there was a copyright violation at all: The fake Mickey Mouse and other figures in combination with the solgan could probably be considered parody - which is legally allowed in most of the world's copyright laws. The park itself was kind of weird. Large parts of it were in really bad shape. Some looked like a construction site, many parts were not operational. On the other hand, other parts of it were really well-designed. One could hardly imagine that this was the same park.
The park itself was kind of weird. Large parts of it were in really bad shape. Some looked like a construction site, many parts were not operational. On the other hand, other parts of it were really well-designed. One could hardly imagine that this was the same park. A nice thing to mention: They had a dance dance revolution like arcade machine - but the game on it was StepMania - a free software game. I think this is the first time I saw a free software game in an arcade machine.
A nice thing to mention: They had a dance dance revolution like arcade machine - but the game on it was StepMania - a free software game. I think this is the first time I saw a free software game in an arcade machine.Unlike most european amusement parks, the pricing concept here is different - the entrance fee costs almost nothing (10 Yuan, approximately 1 €), but you pay for every ride.
Pictures from the park
Friday, December 10. 2010
Notes from talk about GSM and free software
Thursday, January 14. 2010
BIOS update by extracting HD image from ISO
Thursday, June 11. 2009
Looking for router firmware alternatives
Saturday, March 21. 2009
LPI / LPIC - ein kleines Resumee
Saturday, March 14. 2009
Chemnitzer Linux-Tage 2009
 Ich bin mal wieder, wie in den Vorjahren auch schon, auf den Chemnitzer Linux-Tagen. Die Linux-Tage in Chemnitz gehören inzwischen zu einer der zentralen Veranstaltungen der freien Software-Community.
Ich bin mal wieder, wie in den Vorjahren auch schon, auf den Chemnitzer Linux-Tagen. Die Linux-Tage in Chemnitz gehören inzwischen zu einer der zentralen Veranstaltungen der freien Software-Community.Morgen werde ich mich zum ersten Mal an einer LPI-Prüfung versuchen. Habe mich kaum vorbereitet und bin mal gespannt ob man das auch so schafft. Wenn es nicht klappt werde ich mir evtl. entsprechende Literatur zulegen und es erneut versuchen.
Bilder gibt's hier: https://pictures.hboeck.de/clt2009/
Thursday, December 25. 2008
Filling the proprietary gaps: Real Video (RV30/RV40) support in ffmpeg
Wednesday, December 17. 2008
Interview on FSFE webpage
Saturday, December 13. 2008
A critique on the FSFE campaign on PDF readers
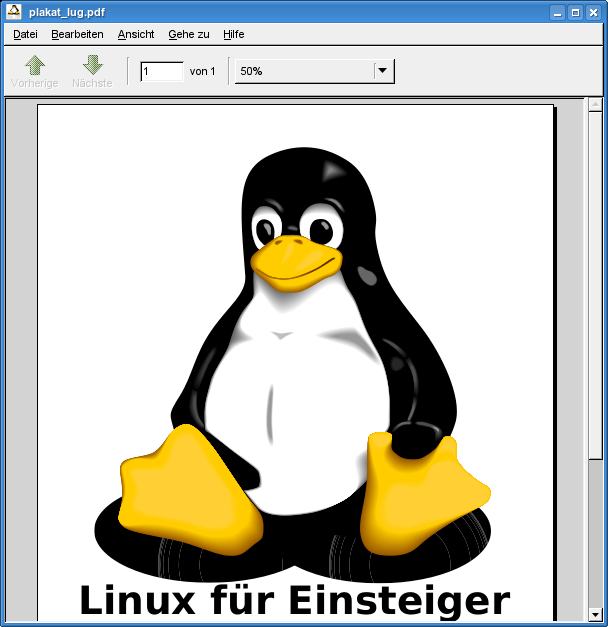 The Free Software Foundation Europe has recently started a campaign promoting free PDF readers. The idea is to replace the tons of »Get Adobe Reader to view the PDF«-Buttons with ones that don't promote a proprietary product for viewing PDFs. On the page, they list a couple of free PDF readers for various operating systems.
The Free Software Foundation Europe has recently started a campaign promoting free PDF readers. The idea is to replace the tons of »Get Adobe Reader to view the PDF«-Buttons with ones that don't promote a proprietary product for viewing PDFs. On the page, they list a couple of free PDF readers for various operating systems.While I fully support the intention of this campaign, I think there's a big strategic misconception. As a small sample, let's take this PDF (an old advertisement for a Linux installation party). It's created with Scribus, based on a transparent SVG tux image I got from Wikipedia. On the right, you can see the PDF rendered with Evince (one of the three Linux-based solutions listed there). The others (kpdf and okular), although based on the same poppler-libarary, show a different rendering, though it's not better.
 Loading the same PDF in the only listed Windows program SumatraPDF (which will, sad but true, probably the one most people will look for) gives an even more interesting result (see on the left). Though, after resizing the window, it changes it's opinion and renders the PDF, although still broken as you can see on the right (results may be false as I only tried it in WINE).
Loading the same PDF in the only listed Windows program SumatraPDF (which will, sad but true, probably the one most people will look for) gives an even more interesting result (see on the left). Though, after resizing the window, it changes it's opinion and renders the PDF, although still broken as you can see on the right (results may be false as I only tried it in WINE).Continuing with the problems, SumatraPDF is unable to fill in PDF forms. Luckily today Linux-based PDF readers are able to do that, though one of the listed programs (kpdf) is not.
 In fact, those are no reasons not to start a campaign for free PDF readers. But it should start with a completely different focus, like »we have some coders wanting to improve free PDF readers, send us your wrong rendered PDFs« or something like that. And then start improving the free PDF readers. And then promote them. Doing it the other way round with a »there is no problem, just take a free PDF reader« message and then giving them ones with grave problems is just lying to people. There's a good reason why for example the Scribus project promotes the Adobe Reader.
In fact, those are no reasons not to start a campaign for free PDF readers. But it should start with a completely different focus, like »we have some coders wanting to improve free PDF readers, send us your wrong rendered PDFs« or something like that. And then start improving the free PDF readers. And then promote them. Doing it the other way round with a »there is no problem, just take a free PDF reader« message and then giving them ones with grave problems is just lying to people. There's a good reason why for example the Scribus project promotes the Adobe Reader.Oh, and before you ask, yes, I have reported the bug about the misrendered transparency a long time ago.