Monday, February 5. 2024
How to create a Secure, Random Password with JavaScript
 I recently needed to create a random password in a piece of JavaScript code. It was surprisingly difficult to find instructions and good examples of how to do that. Almost every result that Google, StackOverflow, or, for that matter, ChatGPT, turned up was flawed in one way or another.
I recently needed to create a random password in a piece of JavaScript code. It was surprisingly difficult to find instructions and good examples of how to do that. Almost every result that Google, StackOverflow, or, for that matter, ChatGPT, turned up was flawed in one way or another.Let's look at a few examples and learn how to create an actually secure password generation function. Our goal is to create a password from a defined set of characters with a fixed length. The password should be generated from a secure source of randomness, and it should have a uniform distribution, meaning every character should appear with the same likelihood. While the examples are JavaScript code, the principles can be used in any programming language.
One of the first examples to show up in Google is a blog post on the webpage dev.to. Here is the relevant part of the code:
/* Example with weak random number generator, DO NOT USE */
var chars = "0123456789abcdefghijklmnopqrstuvwxyz!@#$%^&*()ABCDEFGHIJKLMNOPQRSTUVWXYZ";
var passwordLength = 12;
var password = "";
for (var i = 0; i <= passwordLength; i++) {
var randomNumber = Math.floor(Math.random() * chars.length);
password += chars.substring(randomNumber, randomNumber +1);
}Math.random() does not provide cryptographically secure random numbers. Do not use them for anything related to security. Use the Web Crypto API instead, and more precisely, the window.crypto.getRandomValues() method.
This is pretty clear: We should not use Math.random() for security purposes, as it gives us no guarantees about the security of its output. This is not a merely theoretical concern: here is an example where someone used Math.random() to generate tokens and ended up seeing duplicate tokens in real-world use.
MDN tells us to use the getRandomValues() function of the Web Crypto API, which generates cryptographically strong random numbers.
We can make a more general statement here: Whenever we need randomness for security purposes, we should use a cryptographically secure random number generator. Even in non-security contexts, using secure random sources usually has no downsides. Theoretically, cryptographically strong random number generators can be slower, but unless you generate Gigabytes of random numbers, this is irrelevant. (I am not going to expand on how exactly cryptographically strong random number generators work, as this is something that should be done by the operating system. You can find a good introduction here.)
All modern operating systems have built-in functionality for this. Unfortunately, for historical reasons, in many programming languages, there are simple and more widely used random number generation functions that many people use, and APIs for secure random numbers often come with extra obstacles and may not always be available. However, in the case of Javascript, crypto.getRandomValues() has been available in all major browsers for over a decade.
After establishing that we should not use Math.random(), we may check whether searching specifically for that gives us a better answer. When we search for "Javascript random password without Math.Random()", the first result that shows up is titled "Never use Math.random() to create passwords in JavaScript". That sounds like a good start. Unfortunately, it makes another mistake. Here is the code it recommends:
/* Example with floating point rounding bias, DO NOT USE */
function generatePassword(length = 16)
{
let generatedPassword = "";
const validChars = "0123456789" +
"abcdefghijklmnopqrstuvwxyz" +
"ABCDEFGHIJKLMNOPQRSTUVWXYZ" +
",.-{}+!\"#$%/()=?";
for (let i = 0; i < length; i++) {
let randomNumber = crypto.getRandomValues(new Uint32Array(1))[0];
randomNumber = randomNumber / 0x100000000;
randomNumber = Math.floor(randomNumber * validChars.length);
generatedPassword += validChars[randomNumber];
}
return generatedPassword;
}The problem with this approach is that it uses floating-point numbers. It is generally a good idea to avoid floats in security and particularly cryptographic applications whenever possible. Floats introduce rounding errors, and due to the way they are stored, it is practically almost impossible to generate a uniform distribution. (See also this explanation in a StackExchange comment.)
Therefore, while this implementation is better than the first and probably "good enough" for random passwords, it is not ideal. It does not give us the best security we can have with a certain length and character choice of a password.
Another way of mapping a random integer number to an index for our list of characters is to use a random value modulo the size of our character class. Here is an example from a StackOverflow comment:
/* Example with modulo bias, DO NOT USE */
var generatePassword = (
length = 20,
characters = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~!@-#$'
) =>
Array.from(crypto.getRandomValues(new Uint32Array(length)))
.map((x) => characters[x % characters.length])
.join('')The modulo bias in this example is quite small, so let's look at a different example. Assume we use letters and numbers (a-z, A-Z, 0-9, 62 characters total) and take a single byte (256 different values, 0-255) r from the random number generator. If we use the modulus r % 62, some characters are more likely to appear than others. The reason is that 256 is not a multiple of 62, so it is impossible to map our byte to this list of characters with a uniform distribution.
In our example, the lowercase "a" would be mapped to five values (0, 62, 124, 186, 248). The uppercase "A" would be mapped to only four values (26, 88, 150, 212). Some values have a higher probability than others.
(For more detailed explanations of a modulo bias, check this post by Yolan Romailler from Kudelski Security and this post from Sebastian Pipping.)
One way to avoid a modulo bias is to use rejection sampling. The idea is that you throw away the values that cause higher probabilities. In our example above, 248 and higher values cause the modulo bias, so if we generate such a value, we repeat the process. A piece of code to generate a single random character could look like this:
const pwchars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
const limit = 256 - (256 % pwchars.length);
do {
randval = window.crypto.getRandomValues(new Uint8Array(1))[0];
} while (randval >= limit);An alternative to rejection sampling is to make the modulo bias so small that it does not matter (by using a very large random value).
However, I find rejection sampling to be a much cleaner solution. If you argue that the modulo bias is so small that it does not matter, you must carefully analyze whether this is true. For a password, a small modulo bias may be okay. For cryptographic applications, things can be different. Rejection sampling avoids the modulo bias completely. Therefore, it is always a safe choice.
There are two things you might wonder about this approach. One is that it introduces a timing difference. In cases where the random number generator turns up multiple numbers in a row that are thrown away, the code runs a bit longer.
Timing differences can be a problem in security code, but this one is not. It does not reveal any information about the password because it is only influenced by values we throw away. Even if an attacker were able to measure the exact timing of our password generation, it would not give him any useful information. (This argument is however only true for a cryptographically secure random number generator. It assumes that the ignored random values do not reveal any information about the random number generator's internal state.)
Another issue with this approach is that it is not guaranteed to finish in any given time. Theoretically, the random number generator could produce numbers above our limit so often that the function stalls. However, the probability of that happening quickly becomes so low that it is irrelevant. Such code is generally so fast that even multiple rounds of rejection would not cause a noticeable delay.
To summarize: If we want to write a secure, random password generation function, we should consider three things: We should use a secure random number generation function. We should avoid floating point numbers. And we should avoid a modulo bias.
Taking this all together, here is a Javascript function that generates a 15-character password, composed of ASCII letters and numbers:
function simplesecpw() {
const pwlen = 15;
const pwchars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
const limit = 256 - (256 % pwchars.length);
let passwd = "";
let randval;
for (let i = 0; i < pwlen; i++) {
do {
randval = window.crypto.getRandomValues(new Uint8Array(1))[0];
} while (randval >= limit);
passwd += pwchars[randval % pwchars.length];
}
return passwd;
}If you want to use that code, feel free to do so. I have published it - and a slightly more configurable version that allows optionally setting the length and the set of characters - under a very permissive license (0BSD license).
An online demo generating a password with this code can be found at https://password.hboeck.de/. All code is available on GitHub.
Image Source: SVG Repo, CC0
Monday, April 13. 2020
Generating CRIME safe CSRF Tokens
 For a small web project I recently had to consider how to generate secure tokens to prevent Cross Site Request Forgery (CSRF). I wanted to share how I think this should be done, primarily to get some feedback whether other people agree or see room for improvement.
For a small web project I recently had to consider how to generate secure tokens to prevent Cross Site Request Forgery (CSRF). I wanted to share how I think this should be done, primarily to get some feedback whether other people agree or see room for improvement.I am not going to discuss CSRF in general here, I will generally assume that you are aware of how this attack class works. The standard method to protect against CSRF is to add a token to every form that performs an action that is sufficiently random and unique for the session.
Some web applications use the same token for every request or at least the same token for every request of the same kind. However this is problematic due to some TLS attacks.
There are several attacks against TLS and HTTPS that work by generating a large number of requests and then slowly learning about a secret. A common target of such attacks are CSRF tokens. The list of these attacks is long: BEAST, all Padding Oracle attacks (Lucky Thirteen, POODLE, Zombie POODLE, GOLDENDOODLE), RC4 bias attacks and probably a few more that I have forgotten about. The good news is that none of these attacks should be a concern, because they all affect fragile cryptography that is no longer present in modern TLS stacks.
However there is a class of TLS attacks that is still a concern, because there is no good general fix, and these are compression based attacks. The first such attack that has been shown was called CRIME, which targeted TLS compression. TLS compression is no longer used, but a later attack called BREACH used HTTP compression, which is still widely in use and which nobody wants to disable, because HTML code compresses so well. Further improvements of these attacks are known as TIME and HEIST.
I am not going to discuss these attacks in detail, it is sufficient to know that they all rely on a secret being transmitted again and again over a connection. So CSRF tokens are vulnerable to this if they are the same over multiple connections. If we have an always changing CSRF token this attack does not apply to it.
An obvious fix for this is to always generate new CSRF tokens. However this requires quite a bit of state management on the server or other trade-offs, therefore I don’t think it’s desirable. Rather a good concept would be to keep a single server-side secret, but put some randomness in so the token changes on every request.
The BREACH authors have the following brief recommendation (thanks to Ivan Ristic for pointing this out): “Masking secrets (effectively randomizing by XORing with a random secret per request)”.
I read this as having a real token and a random value and the CSRF token would look like random_value + XOR(random_value, real_token). The server could verify this by splitting up the token, XORing the first half with the second and then comparing that to the real token.
However I would like to add something: I would prefer if a token used for one form and action cannot be used for another action. In case there is any form of token exfiltration it seems reasonable to limit the utility of the token as much as possible.
My idea is therefore to use a cryptographic hash function instead of XOR and add a scope string. This could be something like “adduser”, “addblogpost” etc., anything that identifies the action.
The server would keep a secret token per session on the server side and the CSRF token would look like this: random_value + hash(random_value + secret_token + scope). The random value changes each time the token is sent.
I have created some simple PHP code to implement this (if there is sufficient interest I will learn how to turn this into a composer package). The usage is very simple, there is one function to create a token that takes a scope string as the only parameter and another to check a token that takes the public token and the scope and returns true or false.
As for the implementation details I am using 256 bit random values and secret tokens, which is excessively too much and should avoid any discussion about them being too short. For the hash I am using sha364, which is widely supported and not vulnerable to length extension attacks. I do not see any reason why length extension attacks would be relevant here, but still this feels safer. I believe the order of the hash inputs should not matter, but I have seen constructions where having
The CSRF token is Base64-encoded, which should work fine in HTML forms.
My question would be if people think this is a sane design or if they see room for improvement. Also as this is all relatively straightforward and obvious, I am almost sure I am not the first person to invent this, pointers welcome.
 Now there is an elephant in the room I also need to discuss. Form tokens are the traditional way to prevent CSRF attacks, but in recent years browsers have introduced a new and completely different way of preventing CSRF attacks called SameSite Cookies. The long term plan is to enable them by default, which would likely make CSRF almost impossible. (These plans have been delayed due to Covid-19 and there will probably be some unfortunate compatibility trade-offs that are reason enough to still set the flag manually in a SameSite-by-default world.)
Now there is an elephant in the room I also need to discuss. Form tokens are the traditional way to prevent CSRF attacks, but in recent years browsers have introduced a new and completely different way of preventing CSRF attacks called SameSite Cookies. The long term plan is to enable them by default, which would likely make CSRF almost impossible. (These plans have been delayed due to Covid-19 and there will probably be some unfortunate compatibility trade-offs that are reason enough to still set the flag manually in a SameSite-by-default world.)SameSite Cookies have two flavors: Lax and Strict. When set to Lax, which is what I would recommend that every web application should do, POST requests sent from another host are sent without the Cookie. With Strict all requests, including GET requests, sent from another host are sent without the Cookie. I do not think this is a desirable setting in most cases, as this breaks many workflows and GET requests should not perform any actions anyway.
Now here is a question I have: Are SameSite cookies enough? Do we even need to worry about CSRF tokens any more or can we just skip them? Are there any scenarios where one can bypass SameSite Cookies, but not CSRF tokens?
One could of course say “Why not both?” and see this as a kind of defense in depth. It is a popular mode of thinking to always see more security mechanisms as better, but I do not agree with that reasoning. Security mechanisms introduce complexity and if you can do with less complexity you usually should. CSRF tokens always felt like an ugly solution to me, and I feel SameSite Cookies are a much cleaner way to solve this problem.
So are there situations where SameSite Cookies do not protect and we need tokens? The obvious one is old browsers that do not support SameSite Cookies, however they have been around for a while and if you are willing to not support really old and obscure browsers that should not matter.
A remaining problem I could think of is software that accepts action requests both as GET and POST variables (e. g. in PHP if one uses the $_REQUESTS variable instead of $_POST). These need to be avoided, but using GET for anything that performs actions in the application should not be done anyway. (SameSite=Strict does not really fix his, as GET requests can still plausibly come from links, e. g. on applications that support internal messaging.)
Also an edge case problem may be a transition period: If a web application removes CSRF tokens and starts using SameSite Cookies at the same time Users may still have old Cookies around without the flag. So a transition period at least as long as the Cookie lifetime should be used.
Furthermore there are bypasses for the SameSite-by-default Cookies as planned by browser vendors, but these do not apply when the web application sets the SameSite flag itself. (Essentially the SameSite-by-default Cookies are only SameSite after two minutes, so there is a small window for an attack after setting the Cookie.)
Considering all this if one carefully makes sure that actions can only be performed by POST requests, sets SameSite=Lax on all Cookies and plans a transition period one should be able to safely remove CSRF tokens. Anyone disagrees?
Image sources: Piqsels, Wikimedia Commons
{kind=link}
Tuesday, September 5. 2017
Abandoned Domain Takeover as a Web Security Risk
In the modern web it's extremely common to include thirdparty content on web pages. Youtube videos, social media buttons, ads, statistic tools, CDNs for fonts and common javascript files - there are plenty of good and many not so good reasons for this. What is often forgotten is that including other peoples content means giving other people control over your webpage. This is obviously particularly risky if it involves javascript, as this gives a third party full code execution rights in the context of your webpage.
I recently helped a person whose Wordpress blog had a problem: The layout looked broken. The cause was that the theme used a font from a web host - and that host was down. This was easy to fix. I was able to extract the font file from the Internet Archive and store a copy locally. But it made me thinking: What happens if you include third party content on your webpage and the service from which you're including it disappears?
I put together a simple script that would check webpages for HTML tags with the src attribute. If the src attribute points to an external host it checks if the host name actually can be resolved to an IP address. I ran that check on the Alexa Top 1 Million list. It gave me some interesting results. (This methodology has some limits, as it won't discover indirect src references or includes within javascript code, but it should be good enough to get a rough picture.)
Yahoo! Web Analytics was shut down in 2012, yet in 2017 Flickr still tried to use it
The webpage of Flickr included a script from Yahoo! Web Analytics. If you don't know Yahoo Analytics - that may be because it's been shut down in 2012. Although Flickr is a Yahoo! company it seems they haven't noted for quite a while. (The code is gone now, likely because I mentioned it on Twitter.) This example has no security impact as the domain still belongs to Yahoo. But it likely caused an unnecessary slowdown of page loads over many years.
Going through the list of domains I saw plenty of the things you'd expect: Typos, broken URLs, references to localhost and subdomains no longer in use. Sometimes I saw weird stuff, like references to javascript from browser extensions. My best explanation is that someone had a plugin installed that would inject those into pages and then created a copy of the page with the browser which later endet up being used as the real webpage.
I looked for abandoned domain names that might be worth registering. There weren't many. In most cases the invalid domains were hosts that didn't resolve, but that still belonged to someone. I found a few, but they were only used by one or two hosts.
Takeover of unregistered Azure subdomain
But then I saw a couple of domains referencing a javascript from a non-resolving host called piwiklionshare.azurewebsites.net. This is a subdomain from Microsoft's cloud service Azure. Conveniently Azure allows creating test accounts for free, so I was able to grab this subdomain without any costs.
Doing so allowed me to look at the HTTP log files and see what web pages included code from that subdomain. All of them were local newspapers from the US. 20 of them belonged to two adjacent IP addresses, indicating that they were all managed by the same company. I was able to contact them. While I never received any answer, shortly afterwards the code was gone from all those pages.
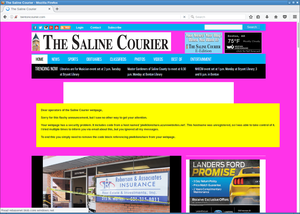 However the page with most hits was not so easy to contact. It was also a newspaper, the Saline Courier. I tried contacting them directly, their chief editor and their second chief editor. No answer.
However the page with most hits was not so easy to contact. It was also a newspaper, the Saline Courier. I tried contacting them directly, their chief editor and their second chief editor. No answer.
After a while I wondered what I could do. Ultimately at some point Microsoft wouldn't let me host that subdomain any longer for free. I didn't want to risk that others could grab that subdomain, but at the same time I obviously also didn't want to pay in order to keep some web page safe whose owners didn't even bother to read my e-mails.
But of course I had another way of contacting them: I could execute Javascript on their web page and use that for some friendly defacement. After some contemplating whether that would be a legitimate thing to do I decided to go for it. I changed the background color to some flashy pink and send them a message. The page remained usable, but it was a message hard to ignore.
With some trouble on the way - first they broke their CSS, then they showed a PHP error message, then they reverted to the page with the defacement. But in the end they managed to remove the code.
There are still a couple of other pages that include that Javascript. Most of them however look like broken test webpages. The only legitimately looking webpage that still embeds that code is the Columbia Missourian. However they don't embed it on the start page, only on the error reporting form they have for every article. It's been several weeks now, they don't seem to care.
What happens to abandoned domains?
There are reasons to believe that what I showed here is only the tip of the iceberg. In many cases when services discontinue their domains don't simply disappear. If the domain name is valuable then almost certainly someone will try to register it immediately after it becomes available.
Someone trying to abuse abandoned domains could watch out for services going ot of business or widely referenced domains becoming available. Just to name an example: I found a couple of hosts referencing subdomains of compete.com. If you go to their web page, you can learn that the company Compete has discontinued its service in 2016. How long will they keep their domain? And what will happen with it afterwards? Whoever gets the domain can hijack all the web pages that still include javascript from it.
Be sure to know what you include
There are some obvious takeaways from this. If you include other peoples code on your web page then you should know what that means: You give them permission to execute whatever they want on your web page. This means you need to wonder how much you can trust them.
At the very least you should be aware who is allowed to execute code on your web page. If they shut down their business or discontinue the service you have been using then you obviously should remove that code immediately. And if you include code from a web statistics service that you never look at anyway you may simply want to remove that as well.
I recently helped a person whose Wordpress blog had a problem: The layout looked broken. The cause was that the theme used a font from a web host - and that host was down. This was easy to fix. I was able to extract the font file from the Internet Archive and store a copy locally. But it made me thinking: What happens if you include third party content on your webpage and the service from which you're including it disappears?
I put together a simple script that would check webpages for HTML tags with the src attribute. If the src attribute points to an external host it checks if the host name actually can be resolved to an IP address. I ran that check on the Alexa Top 1 Million list. It gave me some interesting results. (This methodology has some limits, as it won't discover indirect src references or includes within javascript code, but it should be good enough to get a rough picture.)
Yahoo! Web Analytics was shut down in 2012, yet in 2017 Flickr still tried to use it
The webpage of Flickr included a script from Yahoo! Web Analytics. If you don't know Yahoo Analytics - that may be because it's been shut down in 2012. Although Flickr is a Yahoo! company it seems they haven't noted for quite a while. (The code is gone now, likely because I mentioned it on Twitter.) This example has no security impact as the domain still belongs to Yahoo. But it likely caused an unnecessary slowdown of page loads over many years.
Going through the list of domains I saw plenty of the things you'd expect: Typos, broken URLs, references to localhost and subdomains no longer in use. Sometimes I saw weird stuff, like references to javascript from browser extensions. My best explanation is that someone had a plugin installed that would inject those into pages and then created a copy of the page with the browser which later endet up being used as the real webpage.
I looked for abandoned domain names that might be worth registering. There weren't many. In most cases the invalid domains were hosts that didn't resolve, but that still belonged to someone. I found a few, but they were only used by one or two hosts.
Takeover of unregistered Azure subdomain
But then I saw a couple of domains referencing a javascript from a non-resolving host called piwiklionshare.azurewebsites.net. This is a subdomain from Microsoft's cloud service Azure. Conveniently Azure allows creating test accounts for free, so I was able to grab this subdomain without any costs.
Doing so allowed me to look at the HTTP log files and see what web pages included code from that subdomain. All of them were local newspapers from the US. 20 of them belonged to two adjacent IP addresses, indicating that they were all managed by the same company. I was able to contact them. While I never received any answer, shortly afterwards the code was gone from all those pages.
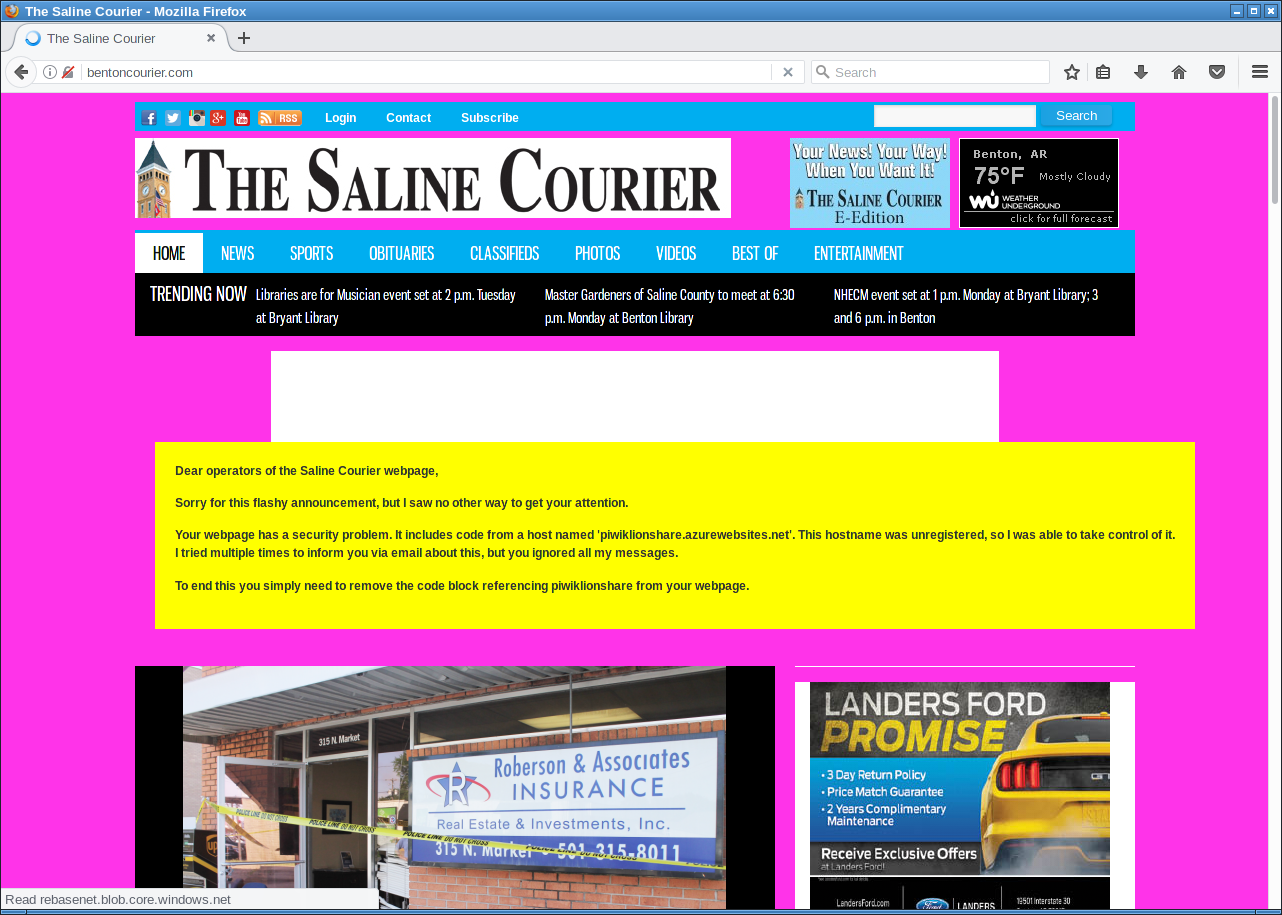
"Friendly defacement" of the Saline Courier.
After a while I wondered what I could do. Ultimately at some point Microsoft wouldn't let me host that subdomain any longer for free. I didn't want to risk that others could grab that subdomain, but at the same time I obviously also didn't want to pay in order to keep some web page safe whose owners didn't even bother to read my e-mails.
But of course I had another way of contacting them: I could execute Javascript on their web page and use that for some friendly defacement. After some contemplating whether that would be a legitimate thing to do I decided to go for it. I changed the background color to some flashy pink and send them a message. The page remained usable, but it was a message hard to ignore.
With some trouble on the way - first they broke their CSS, then they showed a PHP error message, then they reverted to the page with the defacement. But in the end they managed to remove the code.
There are still a couple of other pages that include that Javascript. Most of them however look like broken test webpages. The only legitimately looking webpage that still embeds that code is the Columbia Missourian. However they don't embed it on the start page, only on the error reporting form they have for every article. It's been several weeks now, they don't seem to care.
What happens to abandoned domains?
There are reasons to believe that what I showed here is only the tip of the iceberg. In many cases when services discontinue their domains don't simply disappear. If the domain name is valuable then almost certainly someone will try to register it immediately after it becomes available.
Someone trying to abuse abandoned domains could watch out for services going ot of business or widely referenced domains becoming available. Just to name an example: I found a couple of hosts referencing subdomains of compete.com. If you go to their web page, you can learn that the company Compete has discontinued its service in 2016. How long will they keep their domain? And what will happen with it afterwards? Whoever gets the domain can hijack all the web pages that still include javascript from it.
Be sure to know what you include
There are some obvious takeaways from this. If you include other peoples code on your web page then you should know what that means: You give them permission to execute whatever they want on your web page. This means you need to wonder how much you can trust them.
At the very least you should be aware who is allowed to execute code on your web page. If they shut down their business or discontinue the service you have been using then you obviously should remove that code immediately. And if you include code from a web statistics service that you never look at anyway you may simply want to remove that as well.
Friday, July 15. 2016
Insecure updates in Joomla before 3.6
Friday, September 19. 2014
Some experience with Content Security Policy
 I recently started playing around with Content Security Policy (CSP). CSP is a very neat feature and a good example how to get IT security right.
I recently started playing around with Content Security Policy (CSP). CSP is a very neat feature and a good example how to get IT security right.The main reason CSP exists are cross site scripting vulnerabilities (XSS). Every time a malicious attacker is able to somehow inject JavaScript or other executable code into your webpage this is called an XSS. XSS vulnerabilities are amongst the most common vulnerabilities in web applications.
CSP fixes XSS for good
The approach to fix XSS in the past was to educate web developers that they need to filter or properly escape their input. The problem with this approach is that it doesn't work. Even large websites like Amazon or Ebay don't get this right. The problem, simply stated, is that there are just too many places in a complex web application to create XSS vulnerabilities. Fixing them one at a time doesn't scale.
CSP tries to fix this in a much more generic way: How can we prevent XSS from happening at all? The way to do this is that the web server is sending a header which defines where JavaScript and other content (images, objects etc.) is allowed to come from. If used correctly CSP can prevent XSS completely. The problem with CSP is that it's hard to add to an already existing project, because if you want CSP to be really secure you have to forbid inline JavaScript. That often requires large re-engineering of existing code. Preferrably CSP should be part of the development process right from the beginning. If you start a web project keep that in mind and educate your developers to use restrictive CSP before they write any code. Starting a new web page without CSP these days is irresponsible.
To play around with it I added a CSP header to my personal webpage. This was a simple target, because it's a very simple webpage. I'm essentially sure that my webpage is XSS free because it doesn't use any untrusted input, I mainly wanted to have an easy target to do some testing. I also tried to add CSP to this blog, but this turned out to be much more complicated.
For my personal webpage this is what I did (PHP code):
header("Content-Security-Policy:default-src 'none';img-src 'self';style-src 'self';report-uri /c/");
The default policy is to accept nothing. The only things I use on my webpage are images and stylesheets and they all are located on the same webspace as the webpage itself, so I allow these two things.
This is an extremely simple CSP policy. To give you an idea how a more realistic policy looks like this is the one from Github:
Content-Security-Policy: default-src *; script-src assets-cdn.github.com www.google-analytics.com collector-cdn.github.com; object-src assets-cdn.github.com; style-src 'self' 'unsafe-inline' 'unsafe-eval' assets-cdn.github.com; img-src 'self' data: assets-cdn.github.com identicons.github.com www.google-analytics.com collector.githubapp.com *.githubusercontent.com *.gravatar.com *.wp.com; media-src 'none'; frame-src 'self' render.githubusercontent.com gist.github.com www.youtube.com player.vimeo.com checkout.paypal.com; font-src assets-cdn.github.com; connect-src 'self' ghconduit.com:25035 live.github.com uploads.github.com s3.amazonaws.com
Reporting feature
You may have noticed in my CSP header line that there's a "report-uri" command at the end. The idea is that whenever a browser blocks something by CSP it is able to report this to the webpage owner. Why should we do this? Because we still want to fix XSS issues (there are browsers with little or no CSP support (I'm looking at you Internet Explorer) and we want to know if our policy breaks anything that is supposed to work. The way this works is that a json file with details is sent via a POST request to the URL given.
While this sounds really neat in theory, in practise I found it to be quite disappointing. As I said above I'm almost certain my webpage has no XSS issues, so I shouldn't get any reports at all. However I get lots of them and they are all false positives. The problem are browser extensions that execute things inside a webpage's context. Sometimes you can spot them (when source-file starts with "chrome-extension" or "safari-extension"), sometimes you can't (source-file will only say "data"). Sometimes this is triggered not by single extensions but by combinations of different ones (I found out that a combination of HTTPS everywhere and Adblock for Chrome triggered a CSP warning). I'm not sure how to handle this and if this is something that should be reported as a bug either to the browser vendors or the extension developers.
Conclusion
If you start a web project use CSP. If you have a web page that needs extra security use CSP (my bank doesn't - does yours?). CSP reporting is neat, but it's usefulness is limited due to too many false positives.
Then there's the bigger picture of IT security in general. Fixing single security bugs doesn't work. Why? XSS is as old as JavaScript (1995) and it's still a huge problem. An example for a simliar technology are prepared statements for SQL. If you use them you won't have SQL injections. SQL injections are the second most prevalent web security problem after XSS. By using CSP and prepared statements you eliminate the two biggest issues in web security. Sounds like a good idea to me.
Buffer overflows where first documented 1972 and they still are the source of many security issues. Fixing them for good is trickier but it is also possible.
Wednesday, March 26. 2014
Extract base64-encoded images from CSS
Monday, February 3. 2014
Adblock Plus, Werbung und die Zukunft des Journalismus
 tl;dr Journalismus bangt um seine Finanzierung, aber Werbung nervt. Die Aufmerksamkeit für die Ereignisse um Adblock Plus ist völlig übertrieben. Die Idee der Acceptable Ads ist eigentlich vernünftig, die Medien sollten sie selbst aufgreifen.
tl;dr Journalismus bangt um seine Finanzierung, aber Werbung nervt. Die Aufmerksamkeit für die Ereignisse um Adblock Plus ist völlig übertrieben. Die Idee der Acceptable Ads ist eigentlich vernünftig, die Medien sollten sie selbst aufgreifen.In den letzten Tagen macht mal wieder eine Nachricht um den Werbeblocker Adblock Plus die Runde und wird von zahlreichen Medien aufgegriffen. Ich wollte mal meine Meinung dazu aufschreiben, das wird jetzt etwas länger. Vorneweg: Ich fühle mich in gewisser Weise zwischen den Stühlen. Ich verdiene mein Geld überwiegend mit Journalismus, ich kann aber sehr gut nachvollziehen, warum Menschen Adblocker einsetzen.
Die eine Seite: Zukunft des Journalismus
Der Journalismus ist in der Krise, das wissen wir spätestens seit dem Ende von dapd, der Financial Times Deutschland und dem Beinahe-Ende der Frankfurter Rundschau. Viele Menschen machen sich Sorgen um die Zukunft guter Berichterstattung und viele Journalisten machen sich Sorgen um ihren Job. Die Zukunft des Journalismus liegt im Internet, aber es gibt ein Problem: Bisher haben Zeitungen damit Geld verdient, bedrucktes Papier zu verkaufen und dieses Geschäftsmodell erodiert in rapider Geschwindigkeit. Im Internet Geld zu verdienen ist schwer. Es gibt im wesentlichen vier Möglichkeiten, mit Jouranlismus im Netz Geld zu verdienen: Werbung, bezahlte Inhalte, Spenden/Sponsoring und aus Steuern und Gebühren finanzierter Journalismus.
Keine dieser Möglichkeiten funktioniert sonderlich gut. Viele, die gute Inhalte produzieren, haben es verdammt schwer. Viele glauben, dass man die Nutzer nur irgendwann zum Bezahlen von Inhalten „umerziehen“ muss und dann alle ihre Paywalls anschalten, ich halte das aus verschiedenen Gründen für eine Illusion. Von allen Möglichkeiten, Onlinejournalismus zu finanzieren, funktioniert Werbung derzeit am besten. Nicht gut, aber für die meisten besser als alles andere.
Aber das Geschäftsmodell „Werbung“ wird angenagt. Immer mehr Nutzer nutzen Software wie Adblock Plus, ein relativ simpel zu installierendes Browserplugin.
Die andere Seite: Der genervte Nutzer
Wer heute ohne Werbeblocker im Netz surft bekommt den Eindruck die Werbeindustrie hat jedes Maß verloren. Werbung, die Musik abspielt, die wild blinkend um Aufmerksamkeit bettelt, die ihn ausspioniert, die das System auslastet oder die – das kommt immer wieder vor - versucht, Viren auf dem Rechner des Nutzers zu installieren oder ihn auf betrügerische Webangebote weiterleitet.
Die wenigsten installieren sich einen Adblocker leichtfertig. Denn auch das ist nervig und problembehaftet. Ich habe beispielsweise jahrelang ohne Werbeblocker gesurft. Schon lange vor es Adblock Plus überhaupt gab hatte ich mal ein Tool namens Privoxy installiert, es aber nach kurzer Zeit wieder deinstalliert. Jeder Werbeblocker bringt Probleme mit sich: Manche Seiten funktionieren nicht richtig, der Werbeblocker selbst will Speicher und Systemressourcen, kann für Browserabstürze verantwortlich sein und hat möglicherweise Sicherheitslücken. Werbeblocker installiert man sich erst dann, wenn die Nachteile durch Werbung so gravierend sind, dass sie die Nachteile eines Adblockers deutlich aufwiegen.
Diesen Punkt haben wir inzwischen erreicht und er führt dazu, dass gerade auf IT-Webseiten immer mehr Nutzer mit Adblockern unterwegs sind.
Die dritte Seite: Werbung an sich
Es gibt noch eine dritte Perspektive, die hier nicht verschwiegen werden soll und der ich einiges abgewinnen kann: Werbung ist eigentlich – aus gesellschaftlicher Sicht – eine reichlich dumme Angelegenheit. Werbung dient dazu, Menschen zu mehr Konsum zu bewegen. Sie fragt nicht, ob dieser Konsum irgendeinem Zweck dient. Sie bindet unglaubliche Mengen an Ressourcen und menschlicher Kreativität.
Diese Meinung mag nicht jeder im Detail teilen, aber mehr oder weniger denken vermutlich sehr viele Menschen so. Die wenigsten werden sagen: „Werbung ist etwas grundsätzlich tolles und schützenswertes.“ Schützenswert ist vielleicht der von der Werbung finanzierte Journalismus, aber nicht die Werbung selbst. Deswegen hat man auch wenig Hemmungen, Werbung zu blockieren. Man blockiert nichts wertvolles und hat nicht das Gefühl, etwas zu verpassen.
Es ist in gewisser Weise eine Tragik, dass so etwas sinnvolles wie Journalismus (bei aller Kritik im Detail) heute in starkem Maße von so etwas sinnlosem wie Werbung abhängt. Nein, einen einfachen Ausweg habe ich nicht anzubieten. Aber ich denke man muss sich dieses Dilemmas bewusst sein.

mobilegeeks versus Adblock Plus
Eine sehr erfolgreiche Software zum Blocken von Werbung ist das Browserplugin Adblock Plus. Adblock Plus hat vor einiger Zeit ein Programm für sogenannte „akzeptable Werbung“ (Acceptable Ads) eingeführt. Dafür hat Adblock Plus eine Reihe von Regeln, die wenig überraschen. Sie entspricht in vielen Punkten dem, was auch die meisten Nutzer als „akzeptable Werbung“ betrachten würden, etwa das Verbot von Sound in der Werbung oder von Layer Ads. Adblock Plus pflegt eine Whitelist von Seiten, die sie als akzeptabel betrachten und diese werden in der Standardeinstellung nicht blockiert.
Nun nimmt Adblock Plus von manchen Werbebetreibern auch Geld dafür, dass sie vom Werbeblocker ausgenommen werden. Das kann man fragwürdig finden. Der Betreiber der Webseite mobilegeeks Sascha Pallenberg berichtete darüber schon mehrfach, oft in ausgesprochen polemischer Weise („mafiöses Netzwerk“), und hat dabei eine erstaunliche Medienresonanz. Zuletzt berichtete mobilegeeks, dass Google und andere große Unternehmen an Adblock Plus nicht unerhebliche Beträge zahlen, um in die Liste der akzeptablen Werbung aufgenommen zu werden.
Dass eine Software mit Geschäftsmodellen arbeitet, die fragwürdig sind, kommt häufiger vor. Dass einiges von dem, was die Firma hinter Adblock Plus treibt, kritikwürdig ist, will ich nicht bezweifeln. Die gigantische Medienresonanz der Geschichte hat aber einen faden Beigeschmack. Die Süddeutsche, die Welt, die FAZ oder die Neue Züricher Zeitung sind üblicherweise keine Blätter, die besonders ausführlich über Netzthemen berichten oder sich für die Details seltsamer Geschäftsmodelle im Internet interessieren. Die ganze Geschichte wird viel größer gemacht als sie ist.
Der Effekt dürfte bei vielen Nutzern übrigens kaum sein, dass sie künftig ohne Adblocker surfen. Wer Adblock Plus misstraut, wird entweder das Acceptable Ads-Feature abschalten (ist problemlos möglich) oder auf einen alternativen Werbeblocker setzen, der ohne ein solches Feature auskommt (es gibt genügend davon).
Acceptable Ads
Grundsätzlich ist die Idee von Acceptable Ads nicht dumm. Die Medienbranche täte gut daran, die Diskussion darum, was an Werbung akzeptabel ist und was nicht, selbst zu führen. Man könnte sich etwa eine Selbstverpflichtung der Medienbranche ähnlich dem Pressekodex des deutschen Presserats vorstellen. Im Prinzip kommt man immer wieder zu ähnlichen Schlüssen, was akzeptable Werbung ist: Kein Blinken, kein Sound, keine Layer-Ads, kein Flash.

Werbelinks im Text findet Adblock Plus "akzeptabel"
Man kann sich über manche Details sicher streiten. Ob Animationen generell verboten oder im bestimmten Rahmen erlaubt sein sollten etwa, oder ob Flash eine Existenzberechtigung hat. Manche Nutzer finden es spooky, wenn ihnen Werbebanner durchs Netz folgen, andere haben damit kein Problem. Aber es gibt denke ich zwei Punkte bei denen kann man sich nicht streiten: Sicherheit und Systemauslastung.
Adblocker als Schutz vor Malware
Werbung im Netz ist ein Sicherheitsrisiko. Werbeblocker sind eine sinnvolle Maßnahme, die Sicherheit beim Surfen zu erhöhen. Die Situation ist einigermaßen gruselig. Das BSI hat im letzten Jahr zweimal vor Malware in Werbebannern gewarnt. Es ging dabei nicht um die Schmuddelecken des Internets, zahlreiche populäre Webseiten waren betroffen.
Eine beliebte Software zur Verbreitung von Werbung nennt sich OpenX. OpenX hatte in der Vergangenheit immer wieder massive Sicherheitslücken. Im vergangenen Jahr verteilte die offizielle Webseite von OpenX eine gehackte Version mit einer Backdoor. Diese gehackte Version ist extrem verbreitet. Ich betreibe selber Webserver und habe schon mehrere Installationen davon stillgelegt. OpenX wird inzwischen nicht mehr weiterentwickelt, es gibt einen Nachfolger namens Revive, aber http://www.kreativrauschen.com/blog/2013/12/18/zero-day-vulnerability-in-openx-source-2-8-11-and-revive-adserver-3-0-1/ erst im Dezember wurde in Revive eine weitere massive Sicherheitslücke entdeckt.
Das ist nicht akzeptabel. Überhaupt nicht. Ein „wir bemühen uns, dass so etwas nicht vorkommt“ reicht nicht. Dafür kommt es viel zu oft vor. Ich möchte wissen, welche Strategie die Werbebranche hat, so etwas abzustellen. Ich möchte von den werbenden Webseiten, die mich darum bitten, meinen Adblocker abzuschalten, wissen, welche Software ihre Werbepartner einsetzen, denen sie immerhin die Sicherheit ihrer Kunden anvertrauen. Ich möchte wissen, warum noch niemand einen professionellen Audit von Revive organisiert hat oder Bug-Bounties bezahlt. Solange die Branche dieses Problem nicht soweit im Griff hat, dass das Risiko geringer ist als sich durch den Werbeblocker Sicherheitsprobleme einzuhandeln, werde ich weiterhin jedem, der mich um seine Meinung fragt (und das sind in Sachen PC-Sicherheit ein paar) sagen, dass Adblocker eine effektive Maßnahme zu mehr Sicherheit im Netz sind.
Flash-Banner treiben CPU-Last nach oben
Kommen wir zum Thema Systemlast. Werbung benötigt Rechenpower. Nicht ein bisschen, sondern ganz erheblich. Als es zuletzt mal wieder eine Kampagne von verschiedenen Medien mit der Nachricht „schaltet doch bitte Eure Adblocker aus“ gab, habe ich testweise die Seiten der beteiligten Medien mit Firefox und ohne Werbeblocker aufgerufen. Das Ergebnis war beeindruckend. Auf allen Seiten schnellte die Systemlast nach oben, in top (ein Tool unter Linux zum Anzeigen der Systemauslastung) waren abwechselnd Firefox und das Flash-Plugin ganz oben und benötigten über 50 Prozent der CPU-Leistung.
Ich habe dazu nur eine Frage: Wenn ihr schreibt „Bitte schaltet den Adblocker aus“ - meint ihr wirklich, dass sich eure Besucher deswegen einen schnelleren PC kaufen?
(Hinweis am Rande: Ich weiß, dass das Problem mit der CPU-Last unter Linux verstärkt auftritt, weil der Flash-Player für Linux so schlecht ist. Aber nein, das ist keine Entschuldigung.)
Ein Allmendeproblem
Nachdem ich gestern noch eine Weile über die Sache nachgedacht hab, ist mir ein offensichtliches Problem aufgefallen: Einzelne Nachrichtenwebseiten können vermutlich kaum etwas ausrichten. Werbeblocker deinstallieren werden die Nutzer nicht, wenn eine einzelne Webseite aufhört, nervige Werbung zu schalten. Die Nutzer darum zu bitten, ihren Werbeblocker auf einzelnen Webseiten auszuschalten, funktioniert vermutlich nur in sehr begrenztem Umfang.
Deswegen: Wenn einzelne, kleinere Webangebote voranpreschen und besonders nervige Werbeformen ausschließen, ist das löblich, es wird ihnen aber vermutlich wenig gedankt – ein klassisches Allmendeproblem. Das ganze müsste eine Debatte der Branche sein. Ein guter Anfang wäre es, wenn all diejenigen, die zuletzt entsprechende Appelle an ihre Besucher gestartet haben, sich auf eine Art Kodex einigen würden. Da wäre schon ein relevanter Anteil der deutschsprachigen Nachrichtenwelt zusammen.
Datenschutz
Was ich bis jetzt nur am Rande gestreift habe: Das Thema Datenschutz. Nicht weil ich es vergessen habe, sondern weil ich das Gefühl hatte es verkompliziert die ganze Debatte noch enorm. Werbung wird heute fast immer nicht über die jeweilige Seite selbst sondern über externe Vermarkter ausgeliefert. Das bedeutet automatisch: Der Werbevermarkter bekommt nicht nur Aufmerksamkeit, sondern auch Daten. Dazu kommen noch zahlreiche Services, die ausschließlich Daten abgreifen und für den Nutzer komplett unsichtbar sind. Nicht wenige davon sind gerade für journalistische Angebote kaum verzichtbar, etwa die Zählpixel der VG Wort oder die Statistiken der IVW. Das darf aber nicht darüber hinwegtäuschen: Gerade diese Services dürften inzwischen ein enormes Datenmaterial mit großen Missbrauchspotential haben.
Fazit
Werbung ist doof, aber sie wird auf absehbare Zeit ein wichtiges finanzielles Standbein des Journalismus bleiben. Wenn ihr wollt, dass die Leute aufhören, Adblocker einzusetzen: Macht Werbung erträglich. Dann wird die Rate derer, die sich Werbeblocker installieren, ganz von selbst zurückgehen. Ja, das bedeutet Konflikte mit den Werbevermarktern. Ja, ihr müsst denen erklären, dass Flash doof ist und dass ihr es Euren Nutzern nicht zumuten könnt, wegen ihrer Banner neue Rechner zu kaufen. Nein, von dem Werbebetreiber, der letzten Monat einen Virus verbreitet hat, solltet ihr keine Werbebanner schalten. Ja, es kann dazu führen, dass ihr kurzfristig finanziell lukrative Werbung nicht mehr schalten könnt.
Disclaimer / conflict of interest: Ich benutze auf diesem Blog Google Ads. Google scheint die einzige Firma zu sein, die richtig viel Geld mit Werbung verdient und trotzdem in der Regel das tut, was die meisten als akzeptable Werbung ansehen (mit der großen Ausnahme Datenschutz). Außerdem benutze ich Zählpixel der VG Wort und einen flattr-Button. Ich schreibe regelmäßig Texte für die IT-Nachrichtenseite Golem.de, die an einer der jüngsten Kampagnen zum Thema Adblocker beteiligt war.
Bildquellen: Leuchtreklame von Wikimedia Commons (Public Domain), restliche Bilder Screenshots.
{kind=link}
Wednesday, August 13. 2008
HTML richtig benutzen: max-width und wie heise es falsch macht
Sunday, July 6. 2008
ACID3 with webkit-gtk and midori
 Seems with the latest versions of webkit-gtk and midori, a long-standing crasher-bug got fixed and it now allows you to run the browser-test ACID3.
Seems with the latest versions of webkit-gtk and midori, a long-standing crasher-bug got fixed and it now allows you to run the browser-test ACID3.I just bumped the webkit-gtk ebuild in Gentoo to the latest snapshot.
ACID3 is a test for the standards compliance of modern web browsers. I wrote about ACID2 some years ago.
Tuesday, February 26. 2008
Cross Site Scripting (XSS) in the backend and in the installer
Wednesday, January 9. 2008
The time of personal homepages passed away
Saturday, December 1. 2007
Correct http error code for unconfigured virtual hosts
Tuesday, November 20. 2007
Webmontag Karlsruhe: Talk über Datenschutz
Saturday, July 28. 2007
Neues beim W3C-Validator
Monday, July 16. 2007
Und wieder einmal Webmontag
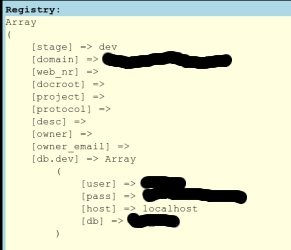 Kleine Lehre von heute: Es ist prinzipiell keine gute Idee, wenn die Fehlermeldungen eines Web-Frameworks die Zugangsdaten zur Datenbank enthalten. Wenn sich dann gleichzeitig noch unter leicht auffindbarer URL ein phpMyAdmin befindet, ist das eher noch schlechter.
Kleine Lehre von heute: Es ist prinzipiell keine gute Idee, wenn die Fehlermeldungen eines Web-Frameworks die Zugangsdaten zur Datenbank enthalten. Wenn sich dann gleichzeitig noch unter leicht auffindbarer URL ein phpMyAdmin befindet, ist das eher noch schlechter.(URL und Projektname gibt's erstmal nicht, weil das bislang nur teilweise gefixt wurde)
Desweiteren soll es jetzt ein neues, aktiveres Stadtblog für Karlsruhe geben. Vielleicht schreib ich bei Gelegenheit auch mal das ein oder andere.
Ansonsten gab es einige Ideen in Richtung Barcamp auf Wasser (Bodensee oder Rhein). Hört sich erstmal ziemlich cool an, bin gespannt was daraus wird.
Links: Webmontag Karlsruhe