Friday, January 17. 2025
Private Keys in the Fortigate Leak
 A few days ago, a download link for a leak of configuration files for Fortigate/Fortinet devices was posted on an Internet forum. It appears that the data was collected in 2022 due to a security vulnerability known as CVE-2022-40684. According to a blog post by Fortinet in 2022, they were already aware of active exploitation of the issue back then. It was first reported by heise, a post by Kevin Beaumont contains further info.
A few days ago, a download link for a leak of configuration files for Fortigate/Fortinet devices was posted on an Internet forum. It appears that the data was collected in 2022 due to a security vulnerability known as CVE-2022-40684. According to a blog post by Fortinet in 2022, they were already aware of active exploitation of the issue back then. It was first reported by heise, a post by Kevin Beaumont contains further info.The leaked configurations contain keys looking like this (not an actual key from the leak):
set private-key "-----BEGIN ENCRYPTED PRIVATE KEY----- MIGjMF8GCSqGSIb3DQEFDTBSMDEGCSqGSIb3DQEFDDAkBBC5oRB/b9iViG5YoFmw 03T1AgIIADAMBggqhkiG9w0CCQUAMB0GCWCGSAFlAwQBKgQQPsMiXQoINAe2uBZX cbB1MARAXz1LwSJhElDvazEtfywe9pLSdCG9+A0G6CMk2Lp5eR954OjScEQY6Zqe 9J3V/fCQeDanrAE+/dpCefjAD4LhGg== -----END ENCRYPTED PRIVATE KEY-----"They also include corresponding certificates and keys in OpenSSH format. As you can see, these private keys are encrypted. However, above those keys, we can find the encryption password. The password is also encrypted, looking like this:
set password ENC SGFja1RoZVBsYW5ldCF[...]UA==A quick search for the encryption method turned up a script containing code to decrypt these passwords. The encryption key is static and publicly known.
The password line contains a Base64 string that decodes to 148 bytes. The first four bytes, padded with 12 zero bytes, are the initialization vector. The remaining bytes are the encrypted payload. The encryption uses AES-128 in CBC mode. The decrypted passwords appear to be mostly hex numbers and are padded with zero bytes - and sometimes other characters. (I am unaware of their meaning.)
In case I lost you here with technical details, the important takeaway is that in almost all cases, it is possible to decrypt the private key. (I may share a tool to extract the keys at a later point in time.)
The use of a static encryption key is a known vulnerability, tracked as CVE-2019-6693. According to Fortinet's advisory from 2020, this was "fixed" by introducing a setting that allows to configure a custom password.
"Fixing" default passwords by providing and documenting an option to change the password is something I have strong opinions about. It does not work (see also).
One result of this incident is that it gives us some real-world data on how many people will actually change their password if the option is given to them and documented in a security advisory. 99,5% of the keys could be decrypted with the default password. (Consider this as a lower bound and not an exact number. The password decryption may be flaky due to the unclear padding mechanism.)
Overall, there were around 100,000 private keys in PKCS format and 60,000 in OpenSSH format. Most of the corresponding certificates were self-signed, but a few thousand were issued by publicly trusted web certificate authorities, most of them expired. However, the data included keys for 84 WebPKI certificates that were neither expired nor revoked as of this morning. Only 10 unexpired certificates were already revoked.
I have reported the still valid certificates to the responsible certificate authorities for revocation. CAs are obliged to revoke certificates with known-compromised keys within 24 hours. Therefore, these certificates will all be revoked soon. (I also filed two reports due to difficulties with the reporting process of some CAs.)
As mentioned above, it was already known in 2022 that this vulnerabiltiy was actively exploited. Yet, it appears that, overwhelmingly, this did not lead to people replacing their likely compromised private keys and revoking their certificates. While we cannot tell from this observation whether the same is true for passwords and other private keys not used in publicly trusted certificates, it appears likely.
Rant
It is an unfortunate reality that these days, security products often are themselves the source of security vulnerabilities. While I have no empirical evidence for this (and nobody else has the data, have I complained about this before?), I believe that we have entered a situation in recent years where security products turned from "mostly useless, sometimes harmful" to "almost certainly causing more security issues than they prevent". I have more thoughts on this that I may share at another time.
If you are wondering what to do, the solution is neither to patch and fix your Fortinet device nor to buy additional attack surface from one of its equally bad competitors. It is to stop believing that adding more attack surface will increase security.
Detecting affected keys
Detection for those keys has been added to badkeys. It is an open source tool, installable via Python's package management. You can use it to scan SSH host keys, certificates, or private keys. Make sure to update the badkeys blocklist (badkeys --update-bl) before doing so.
Please note that this detection is currently based on incomplete data and does not cover all keys in the leak. More updates with more complete coverage may come. Please also note that I have not made the private keys public. Unlike in other cases, this means badkeys cannot give you the private key. (I may decide to publish the keys at some point in the future.)
The badkeys blocklist uses a yet poorly documented format (it is on my todo list to improve this). I am sharing a list of SPKI SHA256 hashes of the affected keys to make it easier for others to write their own detection.
Update (2025-01-23): As mentioned, the original analysis was done with an incomplete set of the data. I later was able to access more complete data, increasing the number of keys to around 98,000 SSH keys and 167,000 PKCS keys. This also led to additional certificates reported for revocation. I have not kept track of the exact numbers. Therefore, the numbers above all refer to the incomplete dataset.
You can find a script to extract and decrypt passwords and private keys from Fortigate configuration files here.
Update (2025-01-24): During further analysis, I discovered that the dataset contained 314 private keys belonging to Let's Encrypt ACME accounts. I have now deactivated those accounts. Given that it has been over a week since the initial report of the incident, this adds to the impression that neither Fortinet itself nor their affected customers appear to have put any effort into cleaning up after this incident.
Update (2025-04-16): The keys.
Image source: paomedia / Public Domain
Monday, February 5. 2024
How to create a Secure, Random Password with JavaScript
 I recently needed to create a random password in a piece of JavaScript code. It was surprisingly difficult to find instructions and good examples of how to do that. Almost every result that Google, StackOverflow, or, for that matter, ChatGPT, turned up was flawed in one way or another.
I recently needed to create a random password in a piece of JavaScript code. It was surprisingly difficult to find instructions and good examples of how to do that. Almost every result that Google, StackOverflow, or, for that matter, ChatGPT, turned up was flawed in one way or another.Let's look at a few examples and learn how to create an actually secure password generation function. Our goal is to create a password from a defined set of characters with a fixed length. The password should be generated from a secure source of randomness, and it should have a uniform distribution, meaning every character should appear with the same likelihood. While the examples are JavaScript code, the principles can be used in any programming language.
One of the first examples to show up in Google is a blog post on the webpage dev.to. Here is the relevant part of the code:
/* Example with weak random number generator, DO NOT USE */
var chars = "0123456789abcdefghijklmnopqrstuvwxyz!@#$%^&*()ABCDEFGHIJKLMNOPQRSTUVWXYZ";
var passwordLength = 12;
var password = "";
for (var i = 0; i <= passwordLength; i++) {
var randomNumber = Math.floor(Math.random() * chars.length);
password += chars.substring(randomNumber, randomNumber +1);
}Math.random() does not provide cryptographically secure random numbers. Do not use them for anything related to security. Use the Web Crypto API instead, and more precisely, the window.crypto.getRandomValues() method.
This is pretty clear: We should not use Math.random() for security purposes, as it gives us no guarantees about the security of its output. This is not a merely theoretical concern: here is an example where someone used Math.random() to generate tokens and ended up seeing duplicate tokens in real-world use.
MDN tells us to use the getRandomValues() function of the Web Crypto API, which generates cryptographically strong random numbers.
We can make a more general statement here: Whenever we need randomness for security purposes, we should use a cryptographically secure random number generator. Even in non-security contexts, using secure random sources usually has no downsides. Theoretically, cryptographically strong random number generators can be slower, but unless you generate Gigabytes of random numbers, this is irrelevant. (I am not going to expand on how exactly cryptographically strong random number generators work, as this is something that should be done by the operating system. You can find a good introduction here.)
All modern operating systems have built-in functionality for this. Unfortunately, for historical reasons, in many programming languages, there are simple and more widely used random number generation functions that many people use, and APIs for secure random numbers often come with extra obstacles and may not always be available. However, in the case of Javascript, crypto.getRandomValues() has been available in all major browsers for over a decade.
After establishing that we should not use Math.random(), we may check whether searching specifically for that gives us a better answer. When we search for "Javascript random password without Math.Random()", the first result that shows up is titled "Never use Math.random() to create passwords in JavaScript". That sounds like a good start. Unfortunately, it makes another mistake. Here is the code it recommends:
/* Example with floating point rounding bias, DO NOT USE */
function generatePassword(length = 16)
{
let generatedPassword = "";
const validChars = "0123456789" +
"abcdefghijklmnopqrstuvwxyz" +
"ABCDEFGHIJKLMNOPQRSTUVWXYZ" +
",.-{}+!\"#$%/()=?";
for (let i = 0; i < length; i++) {
let randomNumber = crypto.getRandomValues(new Uint32Array(1))[0];
randomNumber = randomNumber / 0x100000000;
randomNumber = Math.floor(randomNumber * validChars.length);
generatedPassword += validChars[randomNumber];
}
return generatedPassword;
}The problem with this approach is that it uses floating-point numbers. It is generally a good idea to avoid floats in security and particularly cryptographic applications whenever possible. Floats introduce rounding errors, and due to the way they are stored, it is practically almost impossible to generate a uniform distribution. (See also this explanation in a StackExchange comment.)
Therefore, while this implementation is better than the first and probably "good enough" for random passwords, it is not ideal. It does not give us the best security we can have with a certain length and character choice of a password.
Another way of mapping a random integer number to an index for our list of characters is to use a random value modulo the size of our character class. Here is an example from a StackOverflow comment:
/* Example with modulo bias, DO NOT USE */
var generatePassword = (
length = 20,
characters = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~!@-#$'
) =>
Array.from(crypto.getRandomValues(new Uint32Array(length)))
.map((x) => characters[x % characters.length])
.join('')The modulo bias in this example is quite small, so let's look at a different example. Assume we use letters and numbers (a-z, A-Z, 0-9, 62 characters total) and take a single byte (256 different values, 0-255) r from the random number generator. If we use the modulus r % 62, some characters are more likely to appear than others. The reason is that 256 is not a multiple of 62, so it is impossible to map our byte to this list of characters with a uniform distribution.
In our example, the lowercase "a" would be mapped to five values (0, 62, 124, 186, 248). The uppercase "A" would be mapped to only four values (26, 88, 150, 212). Some values have a higher probability than others.
(For more detailed explanations of a modulo bias, check this post by Yolan Romailler from Kudelski Security and this post from Sebastian Pipping.)
One way to avoid a modulo bias is to use rejection sampling. The idea is that you throw away the values that cause higher probabilities. In our example above, 248 and higher values cause the modulo bias, so if we generate such a value, we repeat the process. A piece of code to generate a single random character could look like this:
const pwchars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
const limit = 256 - (256 % pwchars.length);
do {
randval = window.crypto.getRandomValues(new Uint8Array(1))[0];
} while (randval >= limit);An alternative to rejection sampling is to make the modulo bias so small that it does not matter (by using a very large random value).
However, I find rejection sampling to be a much cleaner solution. If you argue that the modulo bias is so small that it does not matter, you must carefully analyze whether this is true. For a password, a small modulo bias may be okay. For cryptographic applications, things can be different. Rejection sampling avoids the modulo bias completely. Therefore, it is always a safe choice.
There are two things you might wonder about this approach. One is that it introduces a timing difference. In cases where the random number generator turns up multiple numbers in a row that are thrown away, the code runs a bit longer.
Timing differences can be a problem in security code, but this one is not. It does not reveal any information about the password because it is only influenced by values we throw away. Even if an attacker were able to measure the exact timing of our password generation, it would not give him any useful information. (This argument is however only true for a cryptographically secure random number generator. It assumes that the ignored random values do not reveal any information about the random number generator's internal state.)
Another issue with this approach is that it is not guaranteed to finish in any given time. Theoretically, the random number generator could produce numbers above our limit so often that the function stalls. However, the probability of that happening quickly becomes so low that it is irrelevant. Such code is generally so fast that even multiple rounds of rejection would not cause a noticeable delay.
To summarize: If we want to write a secure, random password generation function, we should consider three things: We should use a secure random number generation function. We should avoid floating point numbers. And we should avoid a modulo bias.
Taking this all together, here is a Javascript function that generates a 15-character password, composed of ASCII letters and numbers:
function simplesecpw() {
const pwlen = 15;
const pwchars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
const limit = 256 - (256 % pwchars.length);
let passwd = "";
let randval;
for (let i = 0; i < pwlen; i++) {
do {
randval = window.crypto.getRandomValues(new Uint8Array(1))[0];
} while (randval >= limit);
passwd += pwchars[randval % pwchars.length];
}
return passwd;
}If you want to use that code, feel free to do so. I have published it - and a slightly more configurable version that allows optionally setting the length and the set of characters - under a very permissive license (0BSD license).
An online demo generating a password with this code can be found at https://password.hboeck.de/. All code is available on GitHub.
Image Source: SVG Repo, CC0
Wednesday, October 21. 2020
File Exfiltration via Libreoffice in BigBlueButton and JODConverter
 BigBlueButton is a free web-based video conferencing software that lately got quite popular, largely due to Covid-19. Earlier this year I did a brief check on its security which led to an article on Golem.de (German). I want to share the most significant findings here.
BigBlueButton is a free web-based video conferencing software that lately got quite popular, largely due to Covid-19. Earlier this year I did a brief check on its security which led to an article on Golem.de (German). I want to share the most significant findings here.BigBlueButton has a feature that lets a presenter upload a presentation in a wide variety of file formats that gets then displayed in the web application. This looked like a huge attack surface. The conversion for many file formats is done with Libreoffice on the server. Looking for ways to exploit server-side Libreoffice rendering I found a blog post by Bret Buerhaus that discussed a number of ways of exploiting such setups.
One of the methods described there is a feature in Opendocument Text (ODT) files that allows embedding a file from an external URL in a text section. This can be a web URL like https or a file url and include a local file.
This directly worked in BigBlueButton. An ODT file that referenced a local file would display that local file. This allows displaying any file that the user running the BigBlueButton service could access on the server. A possible way to exploit this is to exfiltrate the configuration file that contains the API secret key, which then allows basically controlling the BigBlueButton instance. I have a video showing the exploit here. (I will publish the exploit later.)
I reported this to the developers of BigBlueButton in May. Unfortunately my experience with their security process was not very good. At first I did not get an answer at all. After another mail they told me they plan to sandbox the Libreoffice process either via a chroot or a docker container. However that still has not happened yet. It is planned for the upcoming version 2.3 and independent of this bug this is a good idea, as Libreoffice just creates a lot of attack surface.
Recently I looked a bit more into this. The functionality to include external files only happens after a manual user confirmation and if one uses Libreoffice on the command line it does not work at all by default. So in theory this exploit should not have worked, but it did.
It turned out the reason for this was another piece of software that BigBlueButton uses called JODConverter. It provides a wrapper around the conversion functionality of Libreoffice. After contacting both the Libreoffice security team and the developer of JODConverter we figured out that it enables including external URLs by default.
I forwarded this information to the BigBlueButton developers and it finally let to a fix, they now change the default settings of JODConverter manually. The JODConverter developer considers changing the default as well, but this has not happened yet. Other software or web pages using JODConverter for serverside file conversion may thus still be vulnerable.
The fix was included in version 2.2.27. Today I learned that the company RedTeam Pentesting has later independently found the same vulnerability. They also requested a CVE: It is now filed as CVE-2020-25820.
While this issue is fixed, the handling of security issues by BigBlueButton was not exactly stellar. It took around five months from my initial report to a fix. The release notes do not mention that this is an important security update (the change has the note “speed up the conversion”).
I found a bunch of other security issues in BigBlueButton and proposed some hardening changes. This took a lot of back and forth, but all significant issues are resolved now.
Another issue with the presentation upload was that it allowed cross site scripting, because it did not set a proper content type for downloads. This was independently discovered by another person and was fixed a while ago. (If you are interested in details about this class of vulnerabilities: I have given a talk about it at last year’s Security Fest.)
The session Cookies both from BigBlueButton itself and from its default web frontend Greenlight were not set with a secure flag, so the cookies could be transmitted in clear text over the network. This has also been changed now.
By default the BigBlueButton installation script starts several services that open ports that do not need to be publicly accessible. This is now also changed. A freeswitch service run locally was installed with a default password (“ClueCon”), this is now also changed to a random password by the installation script.
What also looks quite problematic is the use of outdated software. BigBlueButton only works on Ubuntu 16.04, which is a long term support version, so it still receives updates. But it also uses several external repositories, including one that installs NodeJS version 8 and shows a warning that this repository no longer receives security updates. There is an open bug in the bug tracker.
If you are using BigBlueButton I strongly recommend you update to at least version 2.2.27. This should fix all the issues I found. I would wish that the BigBlueButton developers improve their security process, react more timely to external reports and more transparent when issues are fixed.
Image Source: Wikimedia Commons / NOAA / Public Domain
{kind=link}
Update: Proof of concept published.
Monday, December 16. 2019
#include </etc/shadow>
Recently I saw a tweet where someone mentioned that you can include /dev/stdin in C code compiled with gcc. This is, to say the very least, surprising.
When you see something like this with an IT security background you start to wonder if this can be abused for an attack. While I couldn't come up with anything, I started to wonder what else you could include. As you can basically include arbitrary paths on a system this may be used to exfiltrate data - if you can convince someone else to compile your code.
There are plenty of webpages that offer online services where you can type in C code and run it. It is obvious that such systems are insecure if the code running is not sandboxed in some way. But is it equally obvious that the compiler also needs to be sandboxed?
How would you attack something like this? Exfiltrating data directly through the code is relatively difficult, because you need to include data that ends up being valid C code. Maybe there's a trick to make something like /etc/shadow valid C code (you can put code before and after the include), but I haven't found it. But it's not needed either: The error messages you get from the compiler are all you need. All online tools I tested will show you the errors if your code doesn't compile.
I even found one service that allowed me to add
#include </etc/shadow>
and showed me the hash of the root password. This effectively means this service is running compile tasks as root.
Including various files in /etc allows to learn something about the system. For example /etc/lsb-release often gives information about the distribution in use. Interestingly, including pseudo-files from /proc does not work. It seems gcc treats them like empty files. This limits possibilities to learn about the system. /sys and /dev work, but they contain less human readable information.
In summary I think services letting other people compile code should consider sandboxing the compile process and thus make sure no interesting information can be exfiltrated with these attack vectors.
When you see something like this with an IT security background you start to wonder if this can be abused for an attack. While I couldn't come up with anything, I started to wonder what else you could include. As you can basically include arbitrary paths on a system this may be used to exfiltrate data - if you can convince someone else to compile your code.
There are plenty of webpages that offer online services where you can type in C code and run it. It is obvious that such systems are insecure if the code running is not sandboxed in some way. But is it equally obvious that the compiler also needs to be sandboxed?
How would you attack something like this? Exfiltrating data directly through the code is relatively difficult, because you need to include data that ends up being valid C code. Maybe there's a trick to make something like /etc/shadow valid C code (you can put code before and after the include), but I haven't found it. But it's not needed either: The error messages you get from the compiler are all you need. All online tools I tested will show you the errors if your code doesn't compile.
I even found one service that allowed me to add
#include </etc/shadow>
and showed me the hash of the root password. This effectively means this service is running compile tasks as root.
Including various files in /etc allows to learn something about the system. For example /etc/lsb-release often gives information about the distribution in use. Interestingly, including pseudo-files from /proc does not work. It seems gcc treats them like empty files. This limits possibilities to learn about the system. /sys and /dev work, but they contain less human readable information.
In summary I think services letting other people compile code should consider sandboxing the compile process and thus make sure no interesting information can be exfiltrated with these attack vectors.
Friday, September 13. 2019
Security Issues with PGP Signatures and Linux Package Management
In discussions around the PGP ecosystem one thing I often hear is that while PGP has its problems, it's an important tool for package signatures in Linux distributions. I therefore want to highlight a few issues I came across in this context that are rooted in problems in the larger PGP ecosystem.
Let's look at an example of the use of PGP signatures for deb packages, the Ubuntu Linux installation instructions for HHVM. HHVM is an implementation of the HACK programming language and developed by Facebook. I'm just using HHVM as an example here, as it nicely illustrates two attacks I want to talk about, but you'll find plenty of similar installation instructions for other software packages. I have reported these issues to Facebook, but they decided not to change anything.
The instructions for Ubuntu (and very similarly for Debian) recommend that users execute these commands in order to install HHVM from the repository of its developers:
The crucial part here is the line starting with apt-key. It fetches the key that is used to sign the repository from the Ubuntu key server, which itself is part of the PGP keyserver network.
 Attack 1: Flooding Key with Signatures
Attack 1: Flooding Key with Signatures
The first possible attack is actually quite simple: One can make the signature key offered here unusable by appending many signatures.
A key concept of the PGP keyservers is that they operate append-only. New data gets added, but never removed. PGP keys can sign other keys and these signatures can also be uploaded to the keyservers and get added to a key. Crucially the owner of a key has no influence on this.
This means everyone can grow the size of a key by simply adding many signatures to it. Lately this has happened to a number of keys, see the blog posts by Daniel Kahn Gillmor and Robert Hansen, two members of the PGP community who have personally been affected by this. The effect of this is that when GnuPG tries to import such a key it becomes excessively slow and at some point will simply not work any more.
For the above installation instructions this means anyone can make them unusable by attacking the referenced release key. In my tests I was still able to import one of the attacked keys with apt-key after several minutes, but these keys "only" have a few ten thousand signatures, growing them to a few megabytes size. There's no reason an attacker couldn't use millions of signatures and grow single keys to gigabytes.
Attack 2: Rogue packages with a colliding Key Id
The installation instructions reference the key as 0xB4112585D386EB94, which is a 64 bit hexadecimal key id.
Key ids are a central concept in the PGP ecosystem. The key id is a truncated SHA1 hash of the public key. It's possible to either use the last 32 bit, 64 bit or the full 160 bit of the hash.
It's been pointed out in the past that short key ids allow colliding key ids. This means an attacker can generate a different key with the same key id where he owns the private key simply by bruteforcing the id. In 2014 Richard Klafter and Eric Swanson showed with the Evil32 attack how to create colliding key ids for all keys in the so-called strong set (meaning all keys that are connected with most other keys in the web of trust). Later someone unknown uploaded these keys to the key servers causing quite some confusion.
It should be noted that the issue of colliding key ids was known and discussed in the community way earlier, see for example this discussion from 2002.
The practical attacks targeted 32 bit key ids, but the same attack works against 64 bit key ids, too, it just costs more. I contacted the authors of the Evil32 attack and Eric Swanson estimated in a back of the envelope calculation that it would cost roughly $ 120.000 to perform such an attack with GPUs on cloud providers. This is expensive, but within the possibilities of powerful attackers. Though one can also find similar installation instructions using a 32 bit key id, where the attack is really cheap.
Going back to the installation instructions from above we can imagine the following attack: A man in the middle network attacker can intercept the connection to the keyserver - it's not encrypted or authenticated - and provide the victim a colliding key. Afterwards the key is imported by the victim, so the attacker can provide repositories with packages signed by his key, ultimately leading to code execution.
You may notice that there's a problem with this attack: The repository provided by HHVM is using HTTPS. Thus the attacker can not simply provide a rogue HHVM repository. However the attack still works.
The imported PGP key is not bound to any specific repository. Thus if the victim has any non-HTTPS repository configured in his system the attacker can provide a rogue repository on the next call of "apt update". Notably by default both Debian and Ubuntu use HTTP for their repositories (a Debian developer even runs a dedicated web page explaining why this is no big deal).
Attack 3: Key over HTTP
Issues with package keys aren't confined to Debian/APT-based distributions. I found these installation instructions at Dropbox (Link to Wayback Machine, as Dropbox has changed them after I reported this):
It should be obvious what the issue here is: Both the key and the repository are fetched over HTTP, a network attacker can simply provide his own key and repository.
Discussion
The standard answer you often get when you point out security problems with PGP-based systems is: "It's not PGP/GnuPG, people are just using it wrong". But I believe these issues show some deeper problems with the PGP ecosystem. The key flooding issue is inherited from the systemically flawed concept of the append only key servers.
The other issue here is lack of deprecation. Short key ids are problematic, it's been known for a long time and there have been plenty of calls to get rid of them. This begs the question why no effort has been made to deprecate support for them. One could have said at some point: Future versions of GnuPG will show a warning for short key ids and in three years we will stop supporting them.
This reminds of other issues like unauthenticated encryption, where people have been arguing that this was fixed back in 1999 by the introduction of the MDC. Yet in 2018 it was still exploitable, because the unauthenticated version was never properly deprecated.
Fix
For all people having installation instructions for external repositories my recommendation would be to avoid any use of public key servers. Host the keys on your own infrastructure and provide them via HTTPS. Furthermore any reference to 32 bit or 64 bit key ids should be avoided.
Update: Some people have pointed out to me that the Debian Wiki contains guidelines for third party repositories that avoid the issues mentioned here.
Let's look at an example of the use of PGP signatures for deb packages, the Ubuntu Linux installation instructions for HHVM. HHVM is an implementation of the HACK programming language and developed by Facebook. I'm just using HHVM as an example here, as it nicely illustrates two attacks I want to talk about, but you'll find plenty of similar installation instructions for other software packages. I have reported these issues to Facebook, but they decided not to change anything.
The instructions for Ubuntu (and very similarly for Debian) recommend that users execute these commands in order to install HHVM from the repository of its developers:
apt-get update
apt-get install software-properties-common apt-transport-https
apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xB4112585D386EB94
add-apt-repository https://dl.hhvm.com/ubuntu
apt-get update
apt-get install hhvm
apt-get install software-properties-common apt-transport-https
apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xB4112585D386EB94
add-apt-repository https://dl.hhvm.com/ubuntu
apt-get update
apt-get install hhvm
The crucial part here is the line starting with apt-key. It fetches the key that is used to sign the repository from the Ubuntu key server, which itself is part of the PGP keyserver network.
Attack 1: Flooding Key with SignaturesThe first possible attack is actually quite simple: One can make the signature key offered here unusable by appending many signatures.
A key concept of the PGP keyservers is that they operate append-only. New data gets added, but never removed. PGP keys can sign other keys and these signatures can also be uploaded to the keyservers and get added to a key. Crucially the owner of a key has no influence on this.
This means everyone can grow the size of a key by simply adding many signatures to it. Lately this has happened to a number of keys, see the blog posts by Daniel Kahn Gillmor and Robert Hansen, two members of the PGP community who have personally been affected by this. The effect of this is that when GnuPG tries to import such a key it becomes excessively slow and at some point will simply not work any more.
For the above installation instructions this means anyone can make them unusable by attacking the referenced release key. In my tests I was still able to import one of the attacked keys with apt-key after several minutes, but these keys "only" have a few ten thousand signatures, growing them to a few megabytes size. There's no reason an attacker couldn't use millions of signatures and grow single keys to gigabytes.
Attack 2: Rogue packages with a colliding Key Id
The installation instructions reference the key as 0xB4112585D386EB94, which is a 64 bit hexadecimal key id.
Key ids are a central concept in the PGP ecosystem. The key id is a truncated SHA1 hash of the public key. It's possible to either use the last 32 bit, 64 bit or the full 160 bit of the hash.
It's been pointed out in the past that short key ids allow colliding key ids. This means an attacker can generate a different key with the same key id where he owns the private key simply by bruteforcing the id. In 2014 Richard Klafter and Eric Swanson showed with the Evil32 attack how to create colliding key ids for all keys in the so-called strong set (meaning all keys that are connected with most other keys in the web of trust). Later someone unknown uploaded these keys to the key servers causing quite some confusion.
It should be noted that the issue of colliding key ids was known and discussed in the community way earlier, see for example this discussion from 2002.
The practical attacks targeted 32 bit key ids, but the same attack works against 64 bit key ids, too, it just costs more. I contacted the authors of the Evil32 attack and Eric Swanson estimated in a back of the envelope calculation that it would cost roughly $ 120.000 to perform such an attack with GPUs on cloud providers. This is expensive, but within the possibilities of powerful attackers. Though one can also find similar installation instructions using a 32 bit key id, where the attack is really cheap.
Going back to the installation instructions from above we can imagine the following attack: A man in the middle network attacker can intercept the connection to the keyserver - it's not encrypted or authenticated - and provide the victim a colliding key. Afterwards the key is imported by the victim, so the attacker can provide repositories with packages signed by his key, ultimately leading to code execution.
You may notice that there's a problem with this attack: The repository provided by HHVM is using HTTPS. Thus the attacker can not simply provide a rogue HHVM repository. However the attack still works.
The imported PGP key is not bound to any specific repository. Thus if the victim has any non-HTTPS repository configured in his system the attacker can provide a rogue repository on the next call of "apt update". Notably by default both Debian and Ubuntu use HTTP for their repositories (a Debian developer even runs a dedicated web page explaining why this is no big deal).
Attack 3: Key over HTTP
Issues with package keys aren't confined to Debian/APT-based distributions. I found these installation instructions at Dropbox (Link to Wayback Machine, as Dropbox has changed them after I reported this):
Add the following to /etc/yum.conf.
name=Dropbox Repository
baseurl=http://linux.dropbox.com/fedora/\$releasever/
gpgkey=http://linux.dropbox.com/fedora/rpm-public-key.asc
name=Dropbox Repository
baseurl=http://linux.dropbox.com/fedora/\$releasever/
gpgkey=http://linux.dropbox.com/fedora/rpm-public-key.asc
It should be obvious what the issue here is: Both the key and the repository are fetched over HTTP, a network attacker can simply provide his own key and repository.
Discussion
The standard answer you often get when you point out security problems with PGP-based systems is: "It's not PGP/GnuPG, people are just using it wrong". But I believe these issues show some deeper problems with the PGP ecosystem. The key flooding issue is inherited from the systemically flawed concept of the append only key servers.
The other issue here is lack of deprecation. Short key ids are problematic, it's been known for a long time and there have been plenty of calls to get rid of them. This begs the question why no effort has been made to deprecate support for them. One could have said at some point: Future versions of GnuPG will show a warning for short key ids and in three years we will stop supporting them.
This reminds of other issues like unauthenticated encryption, where people have been arguing that this was fixed back in 1999 by the introduction of the MDC. Yet in 2018 it was still exploitable, because the unauthenticated version was never properly deprecated.
Fix
For all people having installation instructions for external repositories my recommendation would be to avoid any use of public key servers. Host the keys on your own infrastructure and provide them via HTTPS. Furthermore any reference to 32 bit or 64 bit key ids should be avoided.
Update: Some people have pointed out to me that the Debian Wiki contains guidelines for third party repositories that avoid the issues mentioned here.
Wednesday, April 11. 2018
Introducing Snallygaster - a Tool to Scan for Secrets on Web Servers
 A few days ago I figured out that several blogs operated by T-Mobile Austria had a Git repository exposed which included their wordpress configuration file. Due to the fact that a phpMyAdmin installation was also accessible this would have allowed me to change or delete their database and subsequently take over their blogs.
A few days ago I figured out that several blogs operated by T-Mobile Austria had a Git repository exposed which included their wordpress configuration file. Due to the fact that a phpMyAdmin installation was also accessible this would have allowed me to change or delete their database and subsequently take over their blogs.Git Repositories, Private Keys, Core Dumps
Last year I discovered that the German postal service exposed a database with 200.000 addresses on their webpage, because it was simply named dump.sql (which is the default filename for database exports in the documentation example of mysql). An Australian online pharmacy exposed a database under the filename xaa, which is the output of the "split" tool on Unix systems.
It also turns out that plenty of people store their private keys for TLS certificates on their servers - or their SSH keys. Crashing web applications can leave behind coredumps that may expose application memory.
For a while now I became interested in this class of surprisingly trivial vulnerabilities: People leave files accessible on their web servers that shouldn't be public. I've given talks at a couple of conferences (recordings available from Bornhack, SEC-T, Driving IT). I scanned for these issues with a python script that extended with more and more such checks.
Scan your Web Pages with snallygaster
It's taken a bit longer than intended, but I finally released it: It's called Snallygaster and is available on Github and PyPi.
Apart from many checks for secret files it also contains some checks for related issues like checking invalid src references which can lead to Domain takeover vulnerabilities, for the Optionsleed vulnerability which I discovered during this work and for a couple of other vulnerabilities I found interesting and easily testable.
Some may ask why I wrote my own tool instead of extending an existing project. I thought about it, but I didn't really find any existing free software vulnerability scanner that I found suitable. The tool that comes closest is probably Nikto, but testing it I felt it comes with a lot of checks - thus it's slow - and few results. I wanted a tool with a relatively high impact that doesn't take forever to run. Another commonly mentioned free vulnerability scanner is OpenVAS - a fork from Nessus back when that was free software - but I found that always very annoying to use and overengineered. It's not a tool you can "just run". So I ended up creating my own tool.
A Dragon Legend in US Maryland
Finally you may wonder what the name means. The Snallygaster is a dragon that according to some legends was seen in Maryland and other parts of the US. Why that name? There's no particular reason, I just searched for a suitable name, I thought a mythical creature may make a good name. So I searched Wikipedia for potential names and checked for name collisions. This one had none and also sounded funny and interesting enough.
I hope snallygaster turns out to be useful for administrators and pentesters and helps exposing this class of trivial, but often powerful, vulnerabilities. Obviously I welcome new ideas of further tests that could be added to snallygaster.
Thursday, September 7. 2017
In Search of a Secure Time Source
Update: This blogpost was written before NTS was available, and the information is outdated. If you are looking for a modern solution, I recommend using software and a time server with Network Time Security, as specified in RFC 8915.
 All our computers and smartphones have an internal clock and need to know the current time. As configuring the time manually is annoying it's common to set the time via Internet services. What tends to get forgotten is that a reasonably accurate clock is often a crucial part of security features like certificate lifetimes or features with expiration times like HSTS. Thus the timesetting should be secure - but usually it isn't.
All our computers and smartphones have an internal clock and need to know the current time. As configuring the time manually is annoying it's common to set the time via Internet services. What tends to get forgotten is that a reasonably accurate clock is often a crucial part of security features like certificate lifetimes or features with expiration times like HSTS. Thus the timesetting should be secure - but usually it isn't.
I'd like my systems to have a secure time. So I'm looking for a timesetting tool that fullfils two requirements:
Although these seem like trivial requirements to my knowledge such a tool doesn't exist. These are relatively loose requirements. One might want to add:
Some people need a very accurate time source, for example for certain scientific use cases. But that's outside of my scope. For the vast majority of use cases a clock that is off by a few seconds doesn't matter. While it's certainly a good idea to consider rogue servers given the current state of things I'd be happy to have a solution where I simply trust a server from Google or any other major Internet entity.
So let's look at what we have:
NTP
The common way of setting the clock is the NTP protocol. NTP itself has no transport security built in. It's a plaintext protocol open to manipulation and man in the middle attacks.
There are two variants of "secure" NTP. "Autokey", an authenticated variant of NTP, is broken. There's also a symmetric authentication, but that is impractical for widespread use, as it would require to negotiate a pre-shared key with the time server in advance.
NTPsec and Ntimed
In response to some vulnerabilities in the reference implementation of NTP two projects started developing "more secure" variants of NTP. Ntimed - a rewrite by Poul-Henning Kamp - and NTPsec, a fork of the original NTP software. Ntimed hasn't seen any development for several years, NTPsec seems active. NTPsec had some controversies with the developers of the original NTP reference implementation and its main developer is - to put it mildly - a controversial character.
But none of that matters. Both projects don't implement a "secure" NTP. The "sec" in NTPsec refers to the security of the code, not to the security of the protocol itself. It's still just an implementation of the old, insecure NTP.
Network Time Security
There's a draft for a new secure variant of NTP - called Network Time Security. It adds authentication to NTP.
However it's just a draft and it seems stalled. It hasn't been updated for over a year. In any case: It's not widely implemented and thus it's currently not usable. If that changes it may be an option.
tlsdate
tlsdate is a hack abusing the timestamp of the TLS protocol. The TLS timestamp of a server can be used to set the system time. This doesn't provide high accuracy, as the timestamp is only given in seconds, but it's good enough.
I've used and advocated tlsdate for a while, but it has some problems. The timestamp in the TLS handshake doesn't really have any meaning within the protocol, so several implementers decided to replace it with a random value. Unfortunately that is also true for the default server hardcoded into tlsdate.
Some Linux distributions still ship a package with a default server that will send random timestamps. The result is that your system time is set to a random value. I reported this to Ubuntu a while ago. It never got fixed, however the latest Ubuntu version Zesty Zapis (17.04) doesn't ship tlsdate any more.
Given that Google has shipped tlsdate for some in ChromeOS time it seems unlikely that Google will send randomized timestamps any time soon. Thus if you use tlsdate with www.google.com it should work for now. But it's no future-proof solution.
TLS 1.3 removes the TLS timestamp, so this whole concept isn't future-proof. Alternatively it supports using an HTTPS timestamp. The development of tlsdate has stalled, it hasn't seen any updates lately. It doesn't build with the latest version of OpenSSL (1.1) So it likely will become unusable soon.
 OpenNTPD
OpenNTPD
The developers of OpenNTPD, the NTP daemon from OpenBSD, came up with a nice idea. NTP provides high accuracy, yet no security. Via HTTPS you can get a timestamp with low accuracy. So they combined the two: They use NTP to set the time, but they check whether the given time deviates significantly from an HTTPS host. So the HTTPS host provides safety boundaries for the NTP time.
This would be really nice, if there wasn't a catch: This feature depends on an API only provided by LibreSSL, the OpenBSD fork of OpenSSL. So it's not available on most common Linux systems. (Also why doesn't the OpenNTPD web page support HTTPS?)
Roughtime
Roughtime is a Google project. It fetches the time from multiple servers and uses some fancy cryptography to make sure that malicious servers get detected. If a roughtime server sends a bad time then the client gets a cryptographic proof of the malicious behavior, making it possible to blame and shame rogue servers. Roughtime doesn't provide the high accuracy that NTP provides.
From a security perspective it's the nicest of all solutions. However it fails the availability test. Google provides two reference implementations in C++ and in Go, but it's not packaged for any major Linux distribution. Google has an unfortunate tendency to use unusual dependencies and arcane build systems nobody else uses, so packaging it comes with some challenges.
One line bash script beats all existing solutions
As you can see none of the currently available solutions is really feasible and none fulfils the two mild requirements of authenticity and availability.
This is frustrating given that it's a really simple problem. In fact, it's so simple that you can solve it with a single line bash script:
This line sends an HTTPS request to Google, fetches the date header from the response and passes that to the date command line utility.
It provides authenticity via TLS. If the current system time is far off then this fails, as the TLS connection relies on the validity period of the current certificate. Google currently uses certificates with a validity of around three months. The accuracy is only in seconds, so it doesn't qualify for high accuracy requirements. There's no protection against a rogue Google server providing a wrong time.
Another potential security concern may be that Google might attack the parser of the date setting tool by serving a malformed date string. However I ran american fuzzy lop against it and it looks robust.
While this certainly isn't as accurate as NTP or as secure as roughtime, it's better than everything else that's available. I put this together in a slightly more advanced bash script called httpstime.
All our computers and smartphones have an internal clock and need to know the current time. As configuring the time manually is annoying it's common to set the time via Internet services. What tends to get forgotten is that a reasonably accurate clock is often a crucial part of security features like certificate lifetimes or features with expiration times like HSTS. Thus the timesetting should be secure - but usually it isn't.I'd like my systems to have a secure time. So I'm looking for a timesetting tool that fullfils two requirements:
- It provides authenticity of the time and is not vulnerable to man in the middle attacks.
- It is widely available on common Linux systems.
Although these seem like trivial requirements to my knowledge such a tool doesn't exist. These are relatively loose requirements. One might want to add:
- The timesetting needs to provide a good accuracy.
- The timesetting needs to be protected against malicious time servers.
Some people need a very accurate time source, for example for certain scientific use cases. But that's outside of my scope. For the vast majority of use cases a clock that is off by a few seconds doesn't matter. While it's certainly a good idea to consider rogue servers given the current state of things I'd be happy to have a solution where I simply trust a server from Google or any other major Internet entity.
So let's look at what we have:
NTP
The common way of setting the clock is the NTP protocol. NTP itself has no transport security built in. It's a plaintext protocol open to manipulation and man in the middle attacks.
There are two variants of "secure" NTP. "Autokey", an authenticated variant of NTP, is broken. There's also a symmetric authentication, but that is impractical for widespread use, as it would require to negotiate a pre-shared key with the time server in advance.
NTPsec and Ntimed
In response to some vulnerabilities in the reference implementation of NTP two projects started developing "more secure" variants of NTP. Ntimed - a rewrite by Poul-Henning Kamp - and NTPsec, a fork of the original NTP software. Ntimed hasn't seen any development for several years, NTPsec seems active. NTPsec had some controversies with the developers of the original NTP reference implementation and its main developer is - to put it mildly - a controversial character.
But none of that matters. Both projects don't implement a "secure" NTP. The "sec" in NTPsec refers to the security of the code, not to the security of the protocol itself. It's still just an implementation of the old, insecure NTP.
Network Time Security
There's a draft for a new secure variant of NTP - called Network Time Security. It adds authentication to NTP.
However it's just a draft and it seems stalled. It hasn't been updated for over a year. In any case: It's not widely implemented and thus it's currently not usable. If that changes it may be an option.
tlsdate
tlsdate is a hack abusing the timestamp of the TLS protocol. The TLS timestamp of a server can be used to set the system time. This doesn't provide high accuracy, as the timestamp is only given in seconds, but it's good enough.
I've used and advocated tlsdate for a while, but it has some problems. The timestamp in the TLS handshake doesn't really have any meaning within the protocol, so several implementers decided to replace it with a random value. Unfortunately that is also true for the default server hardcoded into tlsdate.
Some Linux distributions still ship a package with a default server that will send random timestamps. The result is that your system time is set to a random value. I reported this to Ubuntu a while ago. It never got fixed, however the latest Ubuntu version Zesty Zapis (17.04) doesn't ship tlsdate any more.
Given that Google has shipped tlsdate for some in ChromeOS time it seems unlikely that Google will send randomized timestamps any time soon. Thus if you use tlsdate with www.google.com it should work for now. But it's no future-proof solution.
TLS 1.3 removes the TLS timestamp, so this whole concept isn't future-proof. Alternatively it supports using an HTTPS timestamp. The development of tlsdate has stalled, it hasn't seen any updates lately. It doesn't build with the latest version of OpenSSL (1.1) So it likely will become unusable soon.
OpenNTPDThe developers of OpenNTPD, the NTP daemon from OpenBSD, came up with a nice idea. NTP provides high accuracy, yet no security. Via HTTPS you can get a timestamp with low accuracy. So they combined the two: They use NTP to set the time, but they check whether the given time deviates significantly from an HTTPS host. So the HTTPS host provides safety boundaries for the NTP time.
This would be really nice, if there wasn't a catch: This feature depends on an API only provided by LibreSSL, the OpenBSD fork of OpenSSL. So it's not available on most common Linux systems. (Also why doesn't the OpenNTPD web page support HTTPS?)
Roughtime
Roughtime is a Google project. It fetches the time from multiple servers and uses some fancy cryptography to make sure that malicious servers get detected. If a roughtime server sends a bad time then the client gets a cryptographic proof of the malicious behavior, making it possible to blame and shame rogue servers. Roughtime doesn't provide the high accuracy that NTP provides.
From a security perspective it's the nicest of all solutions. However it fails the availability test. Google provides two reference implementations in C++ and in Go, but it's not packaged for any major Linux distribution. Google has an unfortunate tendency to use unusual dependencies and arcane build systems nobody else uses, so packaging it comes with some challenges.
One line bash script beats all existing solutions
As you can see none of the currently available solutions is really feasible and none fulfils the two mild requirements of authenticity and availability.
This is frustrating given that it's a really simple problem. In fact, it's so simple that you can solve it with a single line bash script:
date -s "$(curl -sI https://www.google.com/|grep -i 'date:'|sed -e 's/^.ate: //g')"This line sends an HTTPS request to Google, fetches the date header from the response and passes that to the date command line utility.
It provides authenticity via TLS. If the current system time is far off then this fails, as the TLS connection relies on the validity period of the current certificate. Google currently uses certificates with a validity of around three months. The accuracy is only in seconds, so it doesn't qualify for high accuracy requirements. There's no protection against a rogue Google server providing a wrong time.
Another potential security concern may be that Google might attack the parser of the date setting tool by serving a malformed date string. However I ran american fuzzy lop against it and it looks robust.
While this certainly isn't as accurate as NTP or as secure as roughtime, it's better than everything else that's available. I put this together in a slightly more advanced bash script called httpstime.
Tuesday, September 5. 2017
Abandoned Domain Takeover as a Web Security Risk
In the modern web it's extremely common to include thirdparty content on web pages. Youtube videos, social media buttons, ads, statistic tools, CDNs for fonts and common javascript files - there are plenty of good and many not so good reasons for this. What is often forgotten is that including other peoples content means giving other people control over your webpage. This is obviously particularly risky if it involves javascript, as this gives a third party full code execution rights in the context of your webpage.
I recently helped a person whose Wordpress blog had a problem: The layout looked broken. The cause was that the theme used a font from a web host - and that host was down. This was easy to fix. I was able to extract the font file from the Internet Archive and store a copy locally. But it made me thinking: What happens if you include third party content on your webpage and the service from which you're including it disappears?
I put together a simple script that would check webpages for HTML tags with the src attribute. If the src attribute points to an external host it checks if the host name actually can be resolved to an IP address. I ran that check on the Alexa Top 1 Million list. It gave me some interesting results. (This methodology has some limits, as it won't discover indirect src references or includes within javascript code, but it should be good enough to get a rough picture.)
Yahoo! Web Analytics was shut down in 2012, yet in 2017 Flickr still tried to use it
The webpage of Flickr included a script from Yahoo! Web Analytics. If you don't know Yahoo Analytics - that may be because it's been shut down in 2012. Although Flickr is a Yahoo! company it seems they haven't noted for quite a while. (The code is gone now, likely because I mentioned it on Twitter.) This example has no security impact as the domain still belongs to Yahoo. But it likely caused an unnecessary slowdown of page loads over many years.
Going through the list of domains I saw plenty of the things you'd expect: Typos, broken URLs, references to localhost and subdomains no longer in use. Sometimes I saw weird stuff, like references to javascript from browser extensions. My best explanation is that someone had a plugin installed that would inject those into pages and then created a copy of the page with the browser which later endet up being used as the real webpage.
I looked for abandoned domain names that might be worth registering. There weren't many. In most cases the invalid domains were hosts that didn't resolve, but that still belonged to someone. I found a few, but they were only used by one or two hosts.
Takeover of unregistered Azure subdomain
But then I saw a couple of domains referencing a javascript from a non-resolving host called piwiklionshare.azurewebsites.net. This is a subdomain from Microsoft's cloud service Azure. Conveniently Azure allows creating test accounts for free, so I was able to grab this subdomain without any costs.
Doing so allowed me to look at the HTTP log files and see what web pages included code from that subdomain. All of them were local newspapers from the US. 20 of them belonged to two adjacent IP addresses, indicating that they were all managed by the same company. I was able to contact them. While I never received any answer, shortly afterwards the code was gone from all those pages.
 However the page with most hits was not so easy to contact. It was also a newspaper, the Saline Courier. I tried contacting them directly, their chief editor and their second chief editor. No answer.
However the page with most hits was not so easy to contact. It was also a newspaper, the Saline Courier. I tried contacting them directly, their chief editor and their second chief editor. No answer.
After a while I wondered what I could do. Ultimately at some point Microsoft wouldn't let me host that subdomain any longer for free. I didn't want to risk that others could grab that subdomain, but at the same time I obviously also didn't want to pay in order to keep some web page safe whose owners didn't even bother to read my e-mails.
But of course I had another way of contacting them: I could execute Javascript on their web page and use that for some friendly defacement. After some contemplating whether that would be a legitimate thing to do I decided to go for it. I changed the background color to some flashy pink and send them a message. The page remained usable, but it was a message hard to ignore.
With some trouble on the way - first they broke their CSS, then they showed a PHP error message, then they reverted to the page with the defacement. But in the end they managed to remove the code.
There are still a couple of other pages that include that Javascript. Most of them however look like broken test webpages. The only legitimately looking webpage that still embeds that code is the Columbia Missourian. However they don't embed it on the start page, only on the error reporting form they have for every article. It's been several weeks now, they don't seem to care.
What happens to abandoned domains?
There are reasons to believe that what I showed here is only the tip of the iceberg. In many cases when services discontinue their domains don't simply disappear. If the domain name is valuable then almost certainly someone will try to register it immediately after it becomes available.
Someone trying to abuse abandoned domains could watch out for services going ot of business or widely referenced domains becoming available. Just to name an example: I found a couple of hosts referencing subdomains of compete.com. If you go to their web page, you can learn that the company Compete has discontinued its service in 2016. How long will they keep their domain? And what will happen with it afterwards? Whoever gets the domain can hijack all the web pages that still include javascript from it.
Be sure to know what you include
There are some obvious takeaways from this. If you include other peoples code on your web page then you should know what that means: You give them permission to execute whatever they want on your web page. This means you need to wonder how much you can trust them.
At the very least you should be aware who is allowed to execute code on your web page. If they shut down their business or discontinue the service you have been using then you obviously should remove that code immediately. And if you include code from a web statistics service that you never look at anyway you may simply want to remove that as well.
I recently helped a person whose Wordpress blog had a problem: The layout looked broken. The cause was that the theme used a font from a web host - and that host was down. This was easy to fix. I was able to extract the font file from the Internet Archive and store a copy locally. But it made me thinking: What happens if you include third party content on your webpage and the service from which you're including it disappears?
I put together a simple script that would check webpages for HTML tags with the src attribute. If the src attribute points to an external host it checks if the host name actually can be resolved to an IP address. I ran that check on the Alexa Top 1 Million list. It gave me some interesting results. (This methodology has some limits, as it won't discover indirect src references or includes within javascript code, but it should be good enough to get a rough picture.)
Yahoo! Web Analytics was shut down in 2012, yet in 2017 Flickr still tried to use it
The webpage of Flickr included a script from Yahoo! Web Analytics. If you don't know Yahoo Analytics - that may be because it's been shut down in 2012. Although Flickr is a Yahoo! company it seems they haven't noted for quite a while. (The code is gone now, likely because I mentioned it on Twitter.) This example has no security impact as the domain still belongs to Yahoo. But it likely caused an unnecessary slowdown of page loads over many years.
Going through the list of domains I saw plenty of the things you'd expect: Typos, broken URLs, references to localhost and subdomains no longer in use. Sometimes I saw weird stuff, like references to javascript from browser extensions. My best explanation is that someone had a plugin installed that would inject those into pages and then created a copy of the page with the browser which later endet up being used as the real webpage.
I looked for abandoned domain names that might be worth registering. There weren't many. In most cases the invalid domains were hosts that didn't resolve, but that still belonged to someone. I found a few, but they were only used by one or two hosts.
Takeover of unregistered Azure subdomain
But then I saw a couple of domains referencing a javascript from a non-resolving host called piwiklionshare.azurewebsites.net. This is a subdomain from Microsoft's cloud service Azure. Conveniently Azure allows creating test accounts for free, so I was able to grab this subdomain without any costs.
Doing so allowed me to look at the HTTP log files and see what web pages included code from that subdomain. All of them were local newspapers from the US. 20 of them belonged to two adjacent IP addresses, indicating that they were all managed by the same company. I was able to contact them. While I never received any answer, shortly afterwards the code was gone from all those pages.
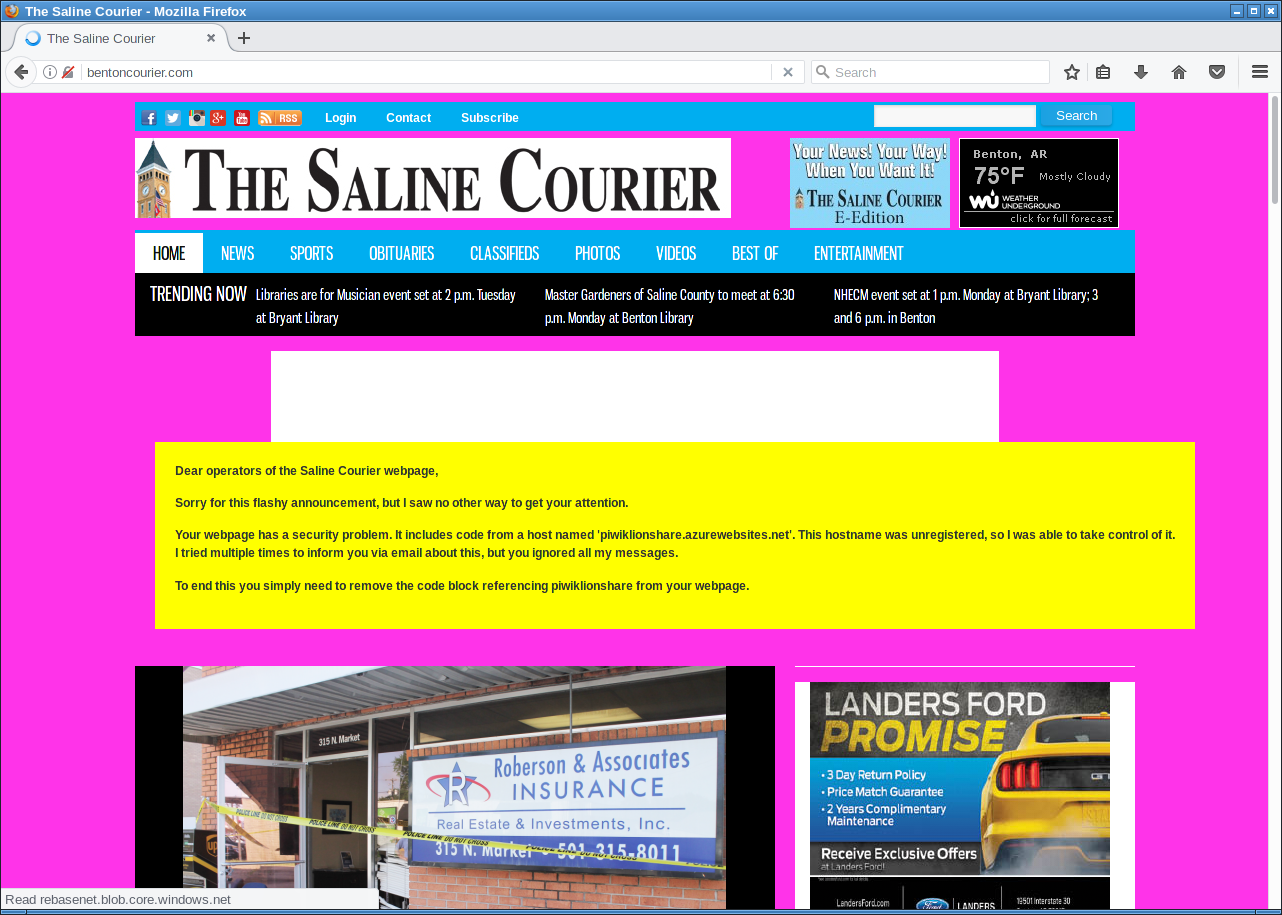
"Friendly defacement" of the Saline Courier.
After a while I wondered what I could do. Ultimately at some point Microsoft wouldn't let me host that subdomain any longer for free. I didn't want to risk that others could grab that subdomain, but at the same time I obviously also didn't want to pay in order to keep some web page safe whose owners didn't even bother to read my e-mails.
But of course I had another way of contacting them: I could execute Javascript on their web page and use that for some friendly defacement. After some contemplating whether that would be a legitimate thing to do I decided to go for it. I changed the background color to some flashy pink and send them a message. The page remained usable, but it was a message hard to ignore.
With some trouble on the way - first they broke their CSS, then they showed a PHP error message, then they reverted to the page with the defacement. But in the end they managed to remove the code.
There are still a couple of other pages that include that Javascript. Most of them however look like broken test webpages. The only legitimately looking webpage that still embeds that code is the Columbia Missourian. However they don't embed it on the start page, only on the error reporting form they have for every article. It's been several weeks now, they don't seem to care.
What happens to abandoned domains?
There are reasons to believe that what I showed here is only the tip of the iceberg. In many cases when services discontinue their domains don't simply disappear. If the domain name is valuable then almost certainly someone will try to register it immediately after it becomes available.
Someone trying to abuse abandoned domains could watch out for services going ot of business or widely referenced domains becoming available. Just to name an example: I found a couple of hosts referencing subdomains of compete.com. If you go to their web page, you can learn that the company Compete has discontinued its service in 2016. How long will they keep their domain? And what will happen with it afterwards? Whoever gets the domain can hijack all the web pages that still include javascript from it.
Be sure to know what you include
There are some obvious takeaways from this. If you include other peoples code on your web page then you should know what that means: You give them permission to execute whatever they want on your web page. This means you need to wonder how much you can trust them.
At the very least you should be aware who is allowed to execute code on your web page. If they shut down their business or discontinue the service you have been using then you obviously should remove that code immediately. And if you include code from a web statistics service that you never look at anyway you may simply want to remove that as well.
Tuesday, January 26. 2016
Safer use of C code - running Gentoo with Address Sanitizer
Update: When I wrote this blog post it was an open question for me whether using Address Sanitizer in production is a good idea. A recent analysis posted on the oss-security mailing list explains in detail why using Asan in its current form is almost certainly not a good idea. Having any suid binary built with Asan enables a local root exploit - and there are various other issues. Therefore using Gentoo with Address Sanitizer is only recommended for developing and debugging purposes.
 Address Sanitizer is a remarkable feature that is part of the gcc and clang compilers. It can be used to find many typical C bugs - invalid memory reads and writes, use after free errors etc. - while running applications. It has found countless bugs in many software packages. I'm often surprised that many people in the free software community seem to be unaware of this powerful tool.
Address Sanitizer is a remarkable feature that is part of the gcc and clang compilers. It can be used to find many typical C bugs - invalid memory reads and writes, use after free errors etc. - while running applications. It has found countless bugs in many software packages. I'm often surprised that many people in the free software community seem to be unaware of this powerful tool.
Address Sanitizer is mainly intended to be a debugging tool. It is usually used to test single applications, often in combination with fuzzing. But as Address Sanitizer can prevent many typical C security bugs - why not use it in production? It doesn't come for free. Address Sanitizer takes significantly more memory and slows down applications by 50 - 100 %. But for some security sensitive applications this may be a reasonable trade-off. The Tor project is already experimenting with this with its Hardened Tor Browser.
One project I've been working on in the past months is to allow a Gentoo system to be compiled with Address Sanitizer. Today I'm publishing this and want to allow others to test it. I have created a page in the Gentoo Wiki that should become the central documentation hub for this project. I published an overlay with several fixes and quirks on Github.
I see this work as part of my Fuzzing Project. (I'm posting it here because the Gentoo category of my personal blog gets indexed by Planet Gentoo.)
I am not sure if using Gentoo with Address Sanitizer is reasonable for a production system. One thing that makes me uneasy in suggesting this for high security requirements is that it's currently incompatible with Grsecurity. But just creating this project already caused me to find a whole number of bugs in several applications. Some notable examples include Coreutils/shred, Bash ([2], [3]), man-db, Pidgin-OTR, Courier, Syslog-NG, Screen, Claws-Mail ([2], [3]), ProFTPD ([2], [3]) ICU, TCL ([2]), Dovecot. I think it was worth the effort.
I will present this work in a talk at FOSDEM in Brussels this Saturday, 14:00, in the Security Devroom.
Address Sanitizer is a remarkable feature that is part of the gcc and clang compilers. It can be used to find many typical C bugs - invalid memory reads and writes, use after free errors etc. - while running applications. It has found countless bugs in many software packages. I'm often surprised that many people in the free software community seem to be unaware of this powerful tool.Address Sanitizer is mainly intended to be a debugging tool. It is usually used to test single applications, often in combination with fuzzing. But as Address Sanitizer can prevent many typical C security bugs - why not use it in production? It doesn't come for free. Address Sanitizer takes significantly more memory and slows down applications by 50 - 100 %. But for some security sensitive applications this may be a reasonable trade-off. The Tor project is already experimenting with this with its Hardened Tor Browser.
One project I've been working on in the past months is to allow a Gentoo system to be compiled with Address Sanitizer. Today I'm publishing this and want to allow others to test it. I have created a page in the Gentoo Wiki that should become the central documentation hub for this project. I published an overlay with several fixes and quirks on Github.
I see this work as part of my Fuzzing Project. (I'm posting it here because the Gentoo category of my personal blog gets indexed by Planet Gentoo.)
I am not sure if using Gentoo with Address Sanitizer is reasonable for a production system. One thing that makes me uneasy in suggesting this for high security requirements is that it's currently incompatible with Grsecurity. But just creating this project already caused me to find a whole number of bugs in several applications. Some notable examples include Coreutils/shred, Bash ([2], [3]), man-db, Pidgin-OTR, Courier, Syslog-NG, Screen, Claws-Mail ([2], [3]), ProFTPD ([2], [3]) ICU, TCL ([2]), Dovecot. I think it was worth the effort.
I will present this work in a talk at FOSDEM in Brussels this Saturday, 14:00, in the Security Devroom.
Monday, November 30. 2015
A little POODLE left in GnuTLS (old versions)
 tl;dr Older GnuTLS versions (2.x) fail to check the first byte of the padding in CBC modes. Various stable Linux distributions, including Ubuntu LTS and Debian wheezy (oldstable) use this version. Current GnuTLS versions are not affected.
tl;dr Older GnuTLS versions (2.x) fail to check the first byte of the padding in CBC modes. Various stable Linux distributions, including Ubuntu LTS and Debian wheezy (oldstable) use this version. Current GnuTLS versions are not affected.A few days ago an email on the ssllabs mailing list catched my attention. A Canonical developer had observed that the SSL Labs test would report the GnuTLS version used in Ubuntu 14.04 (the current long time support version) as vulnerable to the POODLE TLS vulnerability, while other tests for the same vulnerability showed no such issue.
A little background: The original POODLE vulnerability is a weakness of the old SSLv3 protocol that's now officially deprecated. POODLE is based on the fact that SSLv3 does not specify the padding of the CBC modes and the padding bytes can contain arbitrary bytes. A while after POODLE Adam Langley reported that there is a variant of POODLE in TLS, however while the original POODLE is a protocol issue the POODLE TLS vulnerability is an implementation issue. TLS specifies the values of the padding bytes, but some implementations don't check them. Recently Yngve Pettersen reported that there are different variants of this POODLE TLS vulnerability: Some implementations only check parts of the padding. This is the reason why sometimes different tests lead to different results. A test that only changes one byte of the padding will lead to different results than one that changes all padding bytes. Yngve Pettersen uncovered POODLE variants in devices from Cisco (Cavium chip) and Citrix.
I looked at the Ubuntu issue and found that this was exactly such a case of an incomplete padding check: The first byte wasn't checked. I believe this might explain some of the vulnerable hosts Yngve Pettersen found. This is the code:
for (i = 2; i <= pad; i++)
{
if (ciphertext.data[ciphertext.size - i] != pad)
pad_failed = GNUTLS_E_DECRYPTION_FAILED;
}The padding in TLS is defined that the rightmost byte of the last block contains the length of the padding. This value is also used in all padding bytes. However the length field itself is not part of the padding. Therefore if we have e. g. a padding length of three this would result in four bytes with the value 3. The above code misses one byte. i goes from 2 (setting block length minus 2) to pad (block length minus pad length), which sets pad length minus one bytes. To correct it we need to change the loop to end with pad+1. The code is completely reworked in current GnuTLS versions, therefore they are not affected. Upstream has officially announced the end of life for GnuTLS 2, but some stable Linux distributions still use it.
The story doesn't end here: After I found this bug I talked about it with Juraj Somorovsky. He mentioned that he already read about this before: In the paper of the Lucky Thirteen attack. That was published in 2013 by Nadhem AlFardan and Kenny Paterson. Here's what the Lucky Thirteen paper has to say about this issue on page 13:
for (i = 2; i < pad; i++)
{
if (ciphertext->data[ciphertext->size - i] != ciphertext->data[ciphertext->size - 1])
pad_failed = GNUTLS_E_DECRYPTION_FAILED;
}It is not hard to see that this loop should also cover the edge case i=pad in order to carry out a full padding check. This means that one byte of what should be padding actually has a free format.
If you look closely you will see that this code is actually different from the one I quoted above. The reason is that the GnuTLS version in question already contained a fix that was applied in response to the Lucky Thirteen paper. However what the Lucky Thirteen paper missed is that the original check was off by two bytes, not just one byte. Therefore it only got an incomplete fix reducing the attack surface from two bytes to one.
In a later commit this whole code was reworked in response to the Lucky Thirteen attack and there the problem got fixed for good. However that change never made it into version 2 of GnuTLS. Red Hat / CentOS packages contain a backport patch of those changes, therefore they are not affected.
You might wonder what the impact of this bug is. I'm not totally familiar with the details of all the possible attacks, but the POODLE attack gets increasingly harder if fewer bytes of the padding can be freely set. It most likely is impossible if there is only one byte. The Lucky Thirteen paper says: "This would enable, for example, a variant of the short MAC attack of [28] even if variable length padding was not supported.". People that know more about crypto than I do should be left with the judgement whether this might be practically exploitabe.
Fixing this bug is a simple one-line patch I have attached here. This will silence all POODLE checks, however this doesn't apply all the changes that were made in response to the Lucky Thirteen attack. I'm not sure if the code is practically vulnerable, but Lucky Thirteen is a tricky issue, recently a variant of that attack was shown against Amazon's s2n library.
The missing padding check for the first byte got CVE-2015-8313 assigned. Currently I'm aware of Ubuntu LTS (now fixed) and Debian oldstable (Wheezy) being affected.
Sunday, May 17. 2015
About the supposed factoring of a 4096 bit RSA key
 tl;dr News about a broken 4096 bit RSA key are not true. It is just a faulty copy of a valid key.
tl;dr News about a broken 4096 bit RSA key are not true. It is just a faulty copy of a valid key.Earlier today a blog post claiming the factoring of a 4096 bit RSA key was published and quickly made it to the top of Hacker News. The key in question was the PGP key of a well-known Linux kernel developer. I already commented on Hacker News why this is most likely wrong, but I thought I'd write up some more details. To understand what is going on I have to explain some background both on RSA and on PGP keyservers. This by itself is pretty interesting.
RSA public keys consist of two values called N and e. The N value, called the modulus, is the interesting one here. It is the product of two very large prime numbers. The security of RSA relies on the fact that these two numbers are secret. If an attacker would be able to gain knowledge of these numbers he could use them to calculate the private key. That's the reason why RSA depends on the hardness of the factoring problem. If someone can factor N he can break RSA. For all we know today factoring is hard enough to make RSA secure (at least as long as there are no large quantum computers).
Now imagine you have two RSA keys, but they have been generated with bad random numbers. They are different, but one of their primes is the same. That means we have N1=p*q1 and N2=p*q2. In this case RSA is no longer secure, because calculating the greatest common divisor (GCD) of two large numbers can be done very fast with the euclidean algorithm, therefore one can calculate the shared prime value.
It is not only possible to break RSA keys if you have two keys with one shared factors, it is also possible to take a large set of keys and find shared factors between them. In 2012 Arjen Lenstra and his team published a paper using this attack on large scale key sets and at the same time Nadia Heninger and a team at the University of Michigan independently also performed this attack. This uncovered a lot of vulnerable keys on embedded devices, but these were mostly SSH and TLS keys. Lenstra's team however also found two vulnerable PGP keys. For more background you can watch this 29C3 talk by Nadia Heninger, Dan Bernstein and Tanja Lange.
PGP keyservers have been around since quite some time and they have a property that makes them especially interesting for this kind of research: They usually never delete anything. You can add a key to a keyserver, but you cannot remove it, you can only mark it as invalid by revoking it. Therefore using the data from the keyservers gives you a large set of cryptographic keys.
Okay, so back to the news about the supposedly broken 4096 bit key: There is a service called Phuctor where you can upload a key and it'll check it against a set of known vulnerable moduli. This service identified the supposedly vulnerable key.
The key in question has the key id e99ef4b451221121 and belongs to the master key bda06085493bace4. Here is the vulnerable modulus:
c844a98e3372d67f 562bd881da8ea66c a71df16deab1541c e7d68f2243a37665 c3f07d3dd6e651cc d17a822db5794c54 ef31305699a6c77c 043ac87cafc022a3 0a2a717a4aa6b026 b0c1c818cfc16adb aae33c47b0803152 f7e424b784df2861 6d828561a41bdd66 bd220cb46cd288ce 65ccaf9682b20c62 5a84ef28c63e38e9 630daa872270fa15 80cb170bfc492b80 6c017661dab0e0c9 0a12f68a98a98271 82913ff626efddfb f8ae8f1d40da8d13 a90138686884bad1 9db776bb4812f7e3 b288b47114e486fa 2de43011e1d5d7ca 8daf474cb210ce96 2aafee552f192ca0 32ba2b51cfe18322 6eb21ced3b4b3c09 362b61f152d7c7e6 51e12651e915fc9f 67f39338d6d21f55 fb4e79f0b2be4d49 00d442d567bacf7b 6defcd5818b050a4 0db6eab9ad76a7f3 49196dcc5d15cc33 69e1181e03d3b24d a9cf120aa7403f40 0e7e4eca532eac24 49ea7fecc41979d0 35a8e4accea38e1b 9a33d733bea2f430 362bd36f68440ccc 4dc3a7f07b7a7c8f cdd02231f69ce357 4568f303d6eb2916 874d09f2d69e15e6 33c80b8ff4e9baa5 6ed3ace0f65afb43 60c372a6fd0d5629 fdb6e3d832ad3d33 d610b243ea22fe66 f21941071a83b252 201705ebc8e8f2a5 cc01112ac8e43428 50a637bb03e511b2 06599b9d4e8e1ebc eb1e820d569e31c5 0d9fccb16c41315f 652615a02603c69f e9ba03e78c64fecc 034aa783adea213b
In fact this modulus is easily factorable, because it can be divided by 3. However if you look at the master key bda06085493bace4 you'll find another subkey with this modulus:
c844a98e3372d67f 562bd881da8ea66c a71df16deab1541c e7d68f2243a37665 c3f07d3dd6e651cc d17a822db5794c54 ef31305699a6c77c 043ac87cafc022a3 0a2a717a4aa6b026 b0c1c818cfc16adb aae33c47b0803152 f7e424b784df2861 6d828561a41bdd66 bd220cb46cd288ce 65ccaf9682b20c62 5a84ef28c63e38e9 630daa872270fa15 80cb170bfc492b80 6c017661dab0e0c9 0a12f68a98a98271 82c37b8cca2eb4ac 1e889d1027bc1ed6 664f3877cd7052c6 db5567a3365cf7e2 c688b47114e486fa 2de43011e1d5d7ca 8daf474cb210ce96 2aafee552f192ca0 32ba2b51cfe18322 6eb21ced3b4b3c09 362b61f152d7c7e6 51e12651e915fc9f 67f39338d6d21f55 fb4e79f0b2be4d49 00d442d567bacf7b 6defcd5818b050a4 0db6eab9ad76a7f3 49196dcc5d15cc33 69e1181e03d3b24d a9cf120aa7403f40 0e7e4eca532eac24 49ea7fecc41979d0 35a8e4accea38e1b 9a33d733bea2f430 362bd36f68440ccc 4dc3a7f07b7a7c8f cdd02231f69ce357 4568f303d6eb2916 874d09f2d69e15e6 33c80b8ff4e9baa5 6ed3ace0f65afb43 60c372a6fd0d5629 fdb6e3d832ad3d33 d610b243ea22fe66 f21941071a83b252 201705ebc8e8f2a5 cc01112ac8e43428 50a637bb03e511b2 06599b9d4e8e1ebc eb1e820d569e31c5 0d9fccb16c41315f 652615a02603c69f e9ba03e78c64fecc 034aa783adea213b
You may notice that these look pretty similar. But they are not the same. The second one is the real subkey, the first one is just a copy of it with errors.
If you run a batch GCD analysis on the full PGP key server data you will find a number of such keys (Nadia Heninger has published code to do a batch GCD attack). I don't know how they appear on the key servers, I assume they are produced by network errors, harddisk failures or software bugs. It may also be that someone just created them in some experiment.
The important thing is: Everyone can generate a subkey to any PGP key and upload it to a key server. That's just the way the key servers work. They don't check keys in any way. However these keys should pose no threat to anyone. The only case where this could matter would be a broken implementation of the OpenPGP key protocol that does not check if subkeys really belong to a master key.
However you won't be able to easily import such a key into your local GnuPG installation. If you try to fetch this faulty sub key from a key server GnuPG will just refuse to import it. The reason is that every sub key has a signature that proves that it belongs to a certain master key. For those faulty keys this signature is obviously wrong.
Now here's my personal tie in to this story: Last year I started a project to analyze the data on the PGP key servers. And at some point I thought I had found a large number of vulnerable PGP keys – including the key in question here. In a rush I wrote a mail to all people affected. Only later I found out that something was not right and I wrote to all affected people again apologizing. Most of the keys I thought I had found were just faulty keys on the key servers.
The code I used to parse the PGP key server data is public, I also wrote a background paper and did a talk at the BsidesHN conference.
Tuesday, April 7. 2015
How Heartbleed could've been found
 tl;dr With a reasonably simple fuzzing setup I was able to rediscover the Heartbleed bug. This uses state-of-the-art fuzzing and memory protection technology (american fuzzy lop and Address Sanitizer), but it doesn't require any prior knowledge about specifics of the Heartbleed bug or the TLS Heartbeat extension. We can learn from this to find similar bugs in the future.
tl;dr With a reasonably simple fuzzing setup I was able to rediscover the Heartbleed bug. This uses state-of-the-art fuzzing and memory protection technology (american fuzzy lop and Address Sanitizer), but it doesn't require any prior knowledge about specifics of the Heartbleed bug or the TLS Heartbeat extension. We can learn from this to find similar bugs in the future.Exactly one year ago a bug in the OpenSSL library became public that is one of the most well-known security bug of all time: Heartbleed. It is a bug in the code of a TLS extension that up until then was rarely known by anybody. A read buffer overflow allowed an attacker to extract parts of the memory of every server using OpenSSL.
Can we find Heartbleed with fuzzing?
Heartbleed was introduced in OpenSSL 1.0.1, which was released in March 2012, two years earlier. Many people wondered how it could've been hidden there for so long. David A. Wheeler wrote an essay discussing how fuzzing and memory protection technologies could've detected Heartbleed. It covers many aspects in detail, but in the end he only offers speculation on whether or not fuzzing would have found Heartbleed. So I wanted to try it out.
Of course it is easy to find a bug if you know what you're looking for. As best as reasonably possible I tried not to use any specific information I had about Heartbleed. I created a setup that's reasonably simple and similar to what someone would also try it without knowing anything about the specifics of Heartbleed.
Heartbleed is a read buffer overflow. What that means is that an application is reading outside the boundaries of a buffer. For example, imagine an application has a space in memory that's 10 bytes long. If the software tries to read 20 bytes from that buffer, you have a read buffer overflow. It will read whatever is in the memory located after the 10 bytes. These bugs are fairly common and the basic concept of exploiting buffer overflows is pretty old. Just to give you an idea how old: Recently the Chaos Computer Club celebrated the 30th anniversary of a hack of the German BtX-System, an early online service. They used a buffer overflow that was in many aspects very similar to the Heartbleed bug. (It is actually disputed if this is really what happened, but it seems reasonably plausible to me.)
Fuzzing is a widely used strategy to find security issues and bugs in software. The basic idea is simple: Give the software lots of inputs with small errors and see what happens. If the software crashes you likely found a bug.
When buffer overflows happen an application doesn't always crash. Often it will just read (or write if it is a write overflow) to the memory that happens to be there. Whether it crashes depends on a lot of circumstances. Most of the time read overflows won't crash your application. That's also the case with Heartbleed. There are a couple of technologies that improve the detection of memory access errors like buffer overflows. An old and well-known one is the debugging tool Valgrind. However Valgrind slows down applications a lot (around 20 times slower), so it is not really well suited for fuzzing, where you want to run an application millions of times on different inputs.
Address Sanitizer finds more bug
A better tool for our purpose is Address Sanitizer. David A. Wheeler calls it “nothing short of amazing”, and I want to reiterate that. I think it should be a tool that every C/C++ software developer should know and should use for testing.
Address Sanitizer is part of the C compiler and has been included into the two most common compilers in the free software world, gcc and llvm. To use Address Sanitizer one has to recompile the software with the command line parameter -fsanitize=address . It slows down applications, but only by a relatively small amount. According to their own numbers an application using Address Sanitizer is around 1.8 times slower. This makes it feasible for fuzzing tasks.
For the fuzzing itself a tool that recently gained a lot of popularity is american fuzzy lop (afl). This was developed by Michal Zalewski from the Google security team, who is also known by his nick name lcamtuf. As far as I'm aware the approach of afl is unique. It adds instructions to an application during the compilation that allow the fuzzer to detect new code paths while running the fuzzing tasks. If a new interesting code path is found then the sample that created this code path is used as the starting point for further fuzzing.
Currently afl only uses file inputs and cannot directly fuzz network input. OpenSSL has a command line tool that allows all kinds of file inputs, so you can use it for example to fuzz the certificate parser. But this approach does not allow us to directly fuzz the TLS connection, because that only happens on the network layer. By fuzzing various file inputs I recently found two issues in OpenSSL, but both had been found by Brian Carpenter before, who at the same time was also fuzzing OpenSSL.
Let OpenSSL talk to itself
So to fuzz the TLS network connection I had to create a workaround. I wrote a small application that creates two instances of OpenSSL that talk to each other. This application doesn't do any real networking, it is just passing buffers back and forth and thus doing a TLS handshake between a server and a client. Each message packet is written down to a file. It will result in six files, but the last two are just empty, because at that point the handshake is finished and no more data is transmitted. So we have four files that contain actual data from a TLS handshake. If you want to dig into this, a good description of a TLS handshake is provided by the developers of OCaml-TLS and MirageOS.
Then I added the possibility of switching out parts of the handshake messages by files I pass on the command line. By calling my test application selftls with a number and a filename a handshake message gets replaced by this file. So to test just the first part of the server handshake I'd call the test application, take the output file packed-1 and pass it back again to the application by running selftls 1 packet-1. Now we have all the pieces we need to use american fuzzy lop and fuzz the TLS handshake.
I compiled OpenSSL 1.0.1f, the last version that was vulnerable to Heartbleed, with american fuzzy lop. This can be done by calling ./config and then replacing gcc in the Makefile with afl-gcc. Also we want to use Address Sanitizer, to do so we have to set the environment variable AFL_USE_ASAN to 1.
There are some issues when using Address Sanitizer with american fuzzy lop. Address Sanitizer needs a lot of virtual memory (many Terabytes). American fuzzy lop limits the amount of memory an application may use. It is not trivially possible to only limit the real amount of memory an application uses and not the virtual amount, therefore american fuzzy lop cannot handle this flawlessly. Different solutions for this problem have been proposed and are currently developed. I usually go with the simplest solution: I just disable the memory limit of afl (parameter -m -1). This poses a small risk: A fuzzed input may lead an application to a state where it will use all available memory and thereby will cause other applications on the same system to malfuction. Based on my experience this is very rare, so I usually just ignore that potential problem.
After having compiled OpenSSL 1.0.1f we have two files libssl.a and libcrypto.a. These are static versions of OpenSSL and we will use them for our test application. We now also use the afl-gcc to compile our test application:
AFL_USE_ASAN=1 afl-gcc selftls.c -o selftls libssl.a libcrypto.a -ldl
Now we run the application. It needs a dummy certificate. I have put one in the repo. To make things faster I'm using a 512 bit RSA key. This is completely insecure, but as we don't want any security here – we just want to find bugs – this is fine, because a smaller key makes things faster. However if you want to try fuzzing the latest OpenSSL development code you need to create a larger key, because it'll refuse to accept such small keys.
The application will give us six packet files, however the last two will be empty. We only want to fuzz the very first step of the handshake, so we're interested in the first packet. We will create an input directory for american fuzzy lop called in and place packet-1 in it. Then we can run our fuzzing job:
afl-fuzz -i in -o out -m -1 -t 5000 ./selftls 1 @@
We pass the input and output directory, disable the memory limit and increase the timeout value, because TLS handshakes are slower than common fuzzing tasks. On my test machine around 6 hours later afl found the first crash. Now we can manually pass our output to the test application and will get a stack trace by Address Sanitizer:
==2268==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x629000013748 at pc 0x7f228f5f0cfa bp 0x7fffe8dbd590 sp 0x7fffe8dbcd38
READ of size 32768 at 0x629000013748 thread T0
#0 0x7f228f5f0cf9 (/usr/lib/gcc/x86_64-pc-linux-gnu/4.9.2/libasan.so.1+0x2fcf9)
#1 0x43d075 in memcpy /usr/include/bits/string3.h:51
#2 0x43d075 in tls1_process_heartbeat /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/t1_lib.c:2586
#3 0x50e498 in ssl3_read_bytes /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_pkt.c:1092
#4 0x51895c in ssl3_get_message /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_both.c:457
#5 0x4ad90b in ssl3_get_client_hello /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_srvr.c:941
#6 0x4c831a in ssl3_accept /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_srvr.c:357
#7 0x412431 in main /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/selfs.c:85
#8 0x7f228f03ff9f in __libc_start_main (/lib64/libc.so.6+0x1ff9f)
#9 0x4252a1 (/data/openssl/openssl-handshake/openssl-1.0.1f-nobreakrng-afl-asan-fuzz/selfs+0x4252a1)
0x629000013748 is located 0 bytes to the right of 17736-byte region [0x62900000f200,0x629000013748)
allocated by thread T0 here:
#0 0x7f228f6186f7 in malloc (/usr/lib/gcc/x86_64-pc-linux-gnu/4.9.2/libasan.so.1+0x576f7)
#1 0x57f026 in CRYPTO_malloc /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/crypto/mem.c:308
We can see here that the crash is a heap buffer overflow doing an invalid read access of around 32 Kilobytes in the function tls1_process_heartbeat(). It is the Heartbleed bug. We found it.
I want to mention a couple of things that I found out while trying this. I did some things that I thought were necessary, but later it turned out that they weren't. After Heartbleed broke the news a number of reports stated that Heartbleed was partly the fault of OpenSSL's memory management. A mail by Theo De Raadt claiming that OpenSSL has “exploit mitigation countermeasures” was widely quoted. I was aware of that, so I first tried to compile OpenSSL without its own memory management. That can be done by calling ./config with the option no-buf-freelist.
But it turns out although OpenSSL uses its own memory management that doesn't defeat Address Sanitizer. I could replicate my fuzzing finding with OpenSSL compiled with its default options. Although it does its own allocation management, it will still do a call to the system's normal malloc() function for every new memory allocation. A blog post by Chris Rohlf digs into the details of the OpenSSL memory allocator.
Breaking random numbers for deterministic behaviour
When fuzzing the TLS handshake american fuzzy lop will report a red number counting variable runs of the application. The reason for that is that a TLS handshake uses random numbers to create the master secret that's later used to derive cryptographic keys. Also the RSA functions will use random numbers. I wrote a patch to OpenSSL to deliberately break the random number generator and let it only output ones (it didn't work with zeros, because OpenSSL will wait for non-zero random numbers in the RSA function).
During my tests this had no noticeable impact on the time it took afl to find Heartbleed. Still I think it is a good idea to remove nondeterministic behavior when fuzzing cryptographic applications. Later in the handshake there are also timestamps used, this can be circumvented with libfaketime, but for the initial handshake processing that I fuzzed to find Heartbleed that doesn't matter.
Conclusion
You may ask now what the point of all this is. Of course we already know where Heartbleed is, it has been patched, fixes have been deployed and it is mostly history. It's been analyzed thoroughly.
The question has been asked if Heartbleed could've been found by fuzzing. I'm confident to say the answer is yes. One thing I should mention here however: American fuzzy lop was already available back then, but it was barely known. It only received major attention later in 2014, after Michal Zalewski used it to find two variants of the Shellshock bug. Earlier versions of afl were much less handy to use, e. g. they didn't have 64 bit support out of the box. I remember that I failed to use an earlier version of afl with Address Sanitizer, it was only possible after a couple of issues were fixed. A lot of other things have been improved in afl, so at the time Heartbleed was found american fuzzy lop probably wasn't in a state that would've allowed to find it in an easy, straightforward way.
I think the takeaway message is this: We have powerful tools freely available that are capable of finding bugs like Heartbleed. We should use them and look for the other Heartbleeds that are still lingering in our software. Take a look at the Fuzzing Project if you're interested in further fuzzing work. There are beginner tutorials that I wrote with the idea in mind to show people that fuzzing is an easy way to find bugs and improve software quality.
I already used my sample application to fuzz the latest OpenSSL code. Nothing was found yet, but of course this could be further tweaked by trying different protocol versions, extensions and other variations in the handshake.
I also wrote a German article about this finding for the IT news webpage Golem.de.
Update:
I want to point out some feedback I got that I think is noteworthy.
On Twitter it was mentioned that Codenomicon actually found Heartbleed via fuzzing. There's a Youtube video from Codenomicon's Antti Karjalainen explaining the details. However the way they did this was quite different, they built a protocol specific fuzzer. The remarkable feature of afl is that it is very powerful without knowing anything specific about the used protocol. Also it should be noted that Heartbleed was found twice, the first one was Neel Mehta from Google.
Kostya Serebryany mailed me that he was able to replicate my findings with his own fuzzer which is part of LLVM, and it was even faster.
In the comments Michele Spagnuolo mentions that by compiling OpenSSL with -DOPENSSL_TLS_SECURITY_LEVEL=0 one can use very short and insecure RSA keys even in the latest version. Of course this shouldn't be done in production, but it is helpful for fuzzing and other testing efforts.
Friday, January 30. 2015
What the GHOST tells us about free software vulnerability management
 On Tuesday details about the security vulnerability GHOST in Glibc were published by the company Qualys. When severe security vulnerabilities hit the news I always like to take this as a chance to learn what can be improved and how to avoid similar incidents in the future (see e. g. my posts on Heartbleed/Shellshock, POODLE/BERserk and NTP lately).
On Tuesday details about the security vulnerability GHOST in Glibc were published by the company Qualys. When severe security vulnerabilities hit the news I always like to take this as a chance to learn what can be improved and how to avoid similar incidents in the future (see e. g. my posts on Heartbleed/Shellshock, POODLE/BERserk and NTP lately).GHOST itself is a Heap Overflow in the name resolution function of the Glibc. The Glibc is the standard C library on Linux systems, almost every software that runs on a Linux system uses it. It is somewhat unclear right now how serious GHOST really is. A lot of software uses the affected function gethostbyname(), but a lot of conditions have to be met to make this vulnerability exploitable. Right now the most relevant attack is against the mail server exim where Qualys has developed a working exploit which they plan to release soon. There have been speculations whether GHOST might be exploitable through Wordpress, which would make it much more serious.
Technically GHOST is a heap overflow, which is a very common bug in C programming. C is inherently prone to these kinds of memory corruption errors and there are essentially two things here to move forwards: Improve the use of exploit mitigation techniques like ASLR and create new ones (levee is an interesting project, watch this 31C3 talk). And if possible move away from C altogether and develop core components in memory safe languages (I have high hopes for the Mozilla Servo project, watch this linux.conf.au talk).
GHOST was discovered three times
But the thing I want to elaborate here is something different about GHOST: It turns out that it has been discovered independently three times. It was already fixed in 2013 in the Glibc Code itself. The commit message didn't indicate that it was a security vulnerability. Then in early 2014 developers at Google found it again using Address Sanitizer (which – by the way – tells you that all software developers should use Address Sanitizer more often to test their software). Google fixed it in Chrome OS and explicitly called it an overflow and a vulnerability. And then recently Qualys found it again and made it public.
Now you may wonder why a vulnerability fixed in 2013 made headlines in 2015. The reason is that it widely wasn't fixed because it wasn't publicly known that it was serious. I don't think there was any malicious intent. The original Glibc fix was probably done without anyone noticing that it is serious and the Google devs may have thought that the fix is already public, so they don't need to make any noise about it. But we can clearly see that something doesn't work here. Which brings us to a discussion how the Linux and free software world in general and vulnerability management in particular work.
The “Never touch a running system” principle
Quite early when I came in contact with computers I heard the phrase “Never touch a running system”. This may have been a reasonable approach to IT systems back then when computers usually weren't connected to any networks and when remote exploits weren't a thing, but it certainly isn't a good idea today in a world where almost every computer is part of the Internet. Because once new security vulnerabilities become public you should change your system and fix them. However that doesn't change the fact that many people still operate like that.
A number of Linux distributions provide “stable” or “Long Time Support” versions. Basically the idea is this: At some point they take the current state of their systems and further updates will only contain important fixes and security updates. They guarantee to fix security vulnerabilities for a certain time frame. This is kind of a compromise between the “Never touch a running system” approach and reasonable security. It tries to give you a system that will basically stay the same, but you get fixes for security issues. Popular examples for this approach are the stable branch of Debian, Ubuntu LTS versions and the Enterprise versions of Red Hat and SUSE.
To give you an idea about time frames, Debian currently supports the stable trees Squeeze (6.0) which was released 2011 and Wheezy (7.0) which was released 2013. Red Hat Enterprise Linux has currently 4 supported version (4, 5, 6, 7), the oldest one was originally released in 2005. So we're talking about pretty long time frames that these systems get supported. Ubuntu and Suse have similar long time supported Systems.
These systems are delivered with an implicit promise: We will take care of security and if you update regularly you'll have a system that doesn't change much, but that will be secure against know threats. Now the interesting question is: How well do these systems deliver on that promise and how hard is that?
Vulnerability management is chaotic and fragile
I'm not sure how many people are aware how vulnerability management works in the free software world. It is a pretty fragile and chaotic process. There is no standard way things work. The information is scattered around many different places. Different people look for vulnerabilities for different reasons. Some are developers of the respective projects themselves, some are companies like Google that make use of free software projects, some are just curious people interested in IT security or researchers. They report a bug through the channels of the respective project. That may be a mailing list, a bug tracker or just a direct mail to the developer. Hopefully the developers fix the issue. It does happen that the person finding the vulnerability first has to explain to the developer why it actually is a vulnerability. Sometimes the fix will happen in a public code repository, sometimes not. Sometimes the developer will mention that it is a vulnerability in the commit message or the release notes of the new version, sometimes not. There are notorious projects that refuse to handle security vulnerabilities in a transparent way. Sometimes whoever found the vulnerability will post more information on his/her blog or on a mailing list like full disclosure or oss-security. Sometimes not. Sometimes vulnerabilities get a CVE id assigned, sometimes not.
Add to that the fact that in many cases it's far from clear what is a security vulnerability. It is absolutely common that if you ask the people involved whether this is serious the best and most honest answer they can give is “we don't know”. And very often bugs get fixed without anyone noticing that it even could be a security vulnerability.
Then there are projects where the number of security vulnerabilities found and fixed is really huge. The latest Chrome 40 release had 62 security fixes, version 39 had 42. Chrome releases a new version every two months. Browser vulnerabilities are found and fixed on a daily basis. Not that extreme but still high is the vulnerability count in PHP, which is especially worrying if you know that many webhosting providers run PHP versions not supported any more.
So you probably see my point: There is a very chaotic stream of information in various different places about bugs and vulnerabilities in free software projects. The number of vulnerabilities is huge. Making a promise that you will scan all this information for security vulnerabilities and backport the patches to your operating system is a big promise. And I doubt anyone can fulfill that.
GHOST is a single example, so you might ask how often these things happen. At some point right after GHOST became public this excerpt from the Debian Glibc changelog caught my attention (excuse the bad quality, had to take the image from Twitter because I was unable to find that changelog on Debian's webpages):

What you can see here: While Debian fixed GHOST (which is CVE-2015-0235) they also fixed CVE-2012-6656 – a security issue from 2012. Admittedly this is a minor issue, but it's a vulnerability nevertheless. A quick look at the Debian changelog of Chromium both in squeeze and wheezy will tell you that they aren't fixing all the recent security issues in it. (Debian already had discussions about removing Chromium and in Wheezy they don't stick to a single version.)
It would be an interesting (and time consuming) project to take a package like PHP and check for all the security vulnerabilities whether they are fixed in the latest packages in Debian Squeeze/Wheezy, all Red Hat Enterprise versions and other long term support systems. PHP is probably more interesting than browsers, because the high profile targets for these vulnerabilities are servers. What worries me: I'm pretty sure some people already do that. They just won't tell you and me, instead they'll write their exploits and sell them to repressive governments or botnet operators.
Then there are also stories like this: Tavis Ormandy reported a security issue in Glibc in 2012 and the people from Google's Project Zero went to great lengths to show that it is actually exploitable. Reading the Glibc bug report you can learn that this was already reported in 2005(!), just nobody noticed back then that it was a security issue and it was minor enough that nobody cared to fix it.
There are also bugs that require changes so big that backporting them is essentially impossible. In the TLS world a lot of protocol bugs have been highlighted in recent years. Take Lucky Thirteen for example. It is a timing sidechannel in the way the TLS protocol combines the CBC encryption, padding and authentication. I like to mention this bug because I like to quote it as the TLS bug that was already mentioned in the specification (RFC 5246, page 23: "This leaves a small timing channel"). The real fix for Lucky Thirteen is not to use the erratic CBC mode any more and switch to authenticated encryption modes which are part of TLS 1.2. (There's another possible fix which is using Encrypt-then-MAC, but it is hardly deployed.) Up until recently most encryption libraries didn't support TLS 1.2. Debian Squeeze and Red Hat Enterprise 5 ship OpenSSL versions that only support TLS 1.0. There is no trivial patch that could be backported, because this is a huge change. What they likely backported are workarounds that avoid the timing channel. This will stop the attack, but it is not a very good fix, because it keeps the problematic old protocol and will force others to stay compatible with it.
LTS and stable distributions are there for a reason
The big question is of course what to do about it. OpenBSD developer Ted Unangst wrote a blog post yesterday titled Long term support considered harmful, I suggest you read it. He argues that we should get rid of long term support completely and urge users to upgrade more often. OpenBSD has a 6 month release cycle and supports two releases, so one version gets supported for one year.
Given what I wrote before you may think that I agree with him, but I don't. While I personally always avoided to use too old systems – I 'm usually using Gentoo which doesn't have any snapshot releases at all and does rolling releases – I can see the value in long term support releases. There are a lot of systems out there – connected to the Internet – that are never updated. Taking away the option to install systems and let them run with relatively little maintenance overhead over several years will probably result in more systems never receiving any security updates. With all its imperfectness running a Debian Squeeze with the latest updates is certainly better than running an operating system from 2011 that stopped getting security fixes in 2012.
Improving the information flow
I don't think there is a silver bullet solution, but I think there are things we can do to improve the situation. What could be done is to coordinate and share the work. Debian, Red Hat and other distributions with stable/LTS versions could agree that their next versions are based on a specific Glibc version and they collaboratively work on providing patch sets to fix all the vulnerabilities in it. This already somehow happens with upstream projects providing long term support versions, the Linux kernel does that for example. Doing that at scale would require vast organizational changes in the Linux distributions. They would have to agree on a roughly common timescale to start their stable versions.
What I'd consider the most crucial thing is to improve and streamline the information flow about vulnerabilities. When Google fixes a vulnerability in Chrome OS they should make sure this information is shared with other Linux distributions and the public. And they should know where and how they should share this information.
One mechanism that tries to organize the vulnerability process is the system of CVE ids. The idea is actually simple: Publicly known vulnerabilities get a fixed id and they are in a public database. GHOST is CVE-2015-0235 (the scheme will soon change because four digits aren't enough for all the vulnerabilities we find every year). I got my first CVEs assigned in 2007, so I have some experiences with the CVE system and they are rather mixed. Sometimes I briefly mention rather minor issues in a mailing list thread and a CVE gets assigned right away. Sometimes I explicitly ask for CVE assignments and never get an answer.
I would like to see that we just assign CVEs for everything that even remotely looks like a security vulnerability. However right now I think the process is to unreliable to deliver that. There are other public vulnerability databases like OSVDB, I have limited experience with them, so I can't judge if they'd be better suited. Unfortunately sometimes people hesitate to request CVE ids because others abuse the CVE system to count assigned CVEs and use this as a metric how secure a product is. Such bad statistics are outright dangerous, because it gives people an incentive to downplay vulnerabilities or withhold information about them.
This post was partly inspired by some discussions on oss-security
Sunday, November 30. 2014
The Fuzzing Project
Saturday, July 12. 2014
LibreSSL on Gentoo
Yesterday and today I played around with it on Gentoo Linux. I was able to replace my system's OpenSSL completely with LibreSSL and with few exceptions was able to successfully rebuild all packages using OpenSSL.
After getting this running on my own system I installed it on a test server. The Webpage tlsfun.de runs on that server. The functionality changes are limited, the only thing visible from the outside is the support for the experimental, not yet standardized ChaCha20-Poly1305 cipher suites, which is a nice thing.
A warning ahead: This is experimental, in no way stable or supported and if you try any of this you do it at your own risk. Please report any bugs you have with my overlay to me or leave a comment and don't disturb anyone else (from Gentoo or LibreSSL) with it. If you want to try it, you can get a portage overlay in a subversion repository. You can check it out with this command:
svn co https://svn.hboeck.de/libressl-overlay/
git clone https://github.com/gentoo/libressl.git
This is what I had to do to get things running:
LibreSSL itself
First of all the Gentoo tree contains a lot of packages that directly depend on openssl, so I couldn't just replace that. The correct solution to handle such issues would be to create a virtual package and change all packages depending directly on openssl to depend on the virtual. This is already discussed in the appropriate Gentoo bug, but this would mean patching hundreds of packages so I skipped it and worked around it by leaving a fake openssl package in place that itself depends on libressl.
LibreSSL deprecates some APIs from OpenSSL. The first thing that stopped me was that various programs use the functions RAND_egd() and RAND_egd_bytes(). I didn't know until yesterday what egd is. It stands for Entropy Gathering Daemon and is a tool written in perl meant to replace the functionality of /dev/(u)random on non-Linux-systems. The LibreSSL-developers consider it insecure and after having read what it is I have to agree. However, the removal of those functions causes many packages not to build, upon them wget, python and ruby. My workaround was to add two dummy functions that just return -1, which is the error code if the Entropy Gathering Daemon is not available. So the API still behaves like expected. I also posted the patch upstream, but the LibreSSL devs don't like it. So on the long term it's probably better to fix applications to stop trying to use egd, but for now these dummy functions make it easier for me to build my system.
The second issue popping up was that the libcrypto.so from libressl contains an undefined main() function symbol which causes linking problems with a couple of applications (subversion, xorg-server, hexchat). According to upstream this undefined symbol is intended and most likely these are bugs in the applications having linking problems. However, for now it was easier for me to patch the symbol out instead of fixing all the apps. Like the egd issue on the long term fixing the applications is better.
The third issue was that LibreSSL doesn't ship pkg-config (.pc) files, some apps use them to get the correct compilation flags. I grabbed the ones from openssl and adjusted them accordingly.
OpenSSH
This was the most interesting issue from all of them.
To understand this you have to understand how both LibreSSL and OpenSSH are developed. They are both from OpenBSD and they use some functions that are only available there. To allow them to be built on other systems they release portable versions which ship the missing OpenBSD-only-functions. One of them is arc4random().
Both LibreSSL and OpenSSH ship their compatibility version of arc4random(). The one from OpenSSH calls RAND_bytes(), which is a function from OpenSSL. The RAND_bytes() function from LibreSSL however calls arc4random(). Due to the linking order OpenSSH uses its own arc4random(). So what we have here is a nice recursion. arc4random() and RAND_bytes() try to call each other. The result is a segfault.
I fixed it by using the LibreSSL arc4random.c file for OpenSSH. I had to copy another function called arc4random_stir() from OpenSSH's arc4random.c and the header file thread_private.h. Surprisingly, this seems to work flawlessly.
Net-SSLeay
This package contains the perl bindings for openssl. The problem is a check for the openssl version string that expected the name OpenSSL and a version number with three numbers and a letter (like 1.0.1h). LibreSSL prints the version 2.0. I just hardcoded the OpenSSL version numer, which is not a real fix, but it works for now.
SpamAssassin
SpamAssassin's code for spamc requires SSLv2 functions to be available. SSLv2 is heavily insecure and should not be used at all and therefore the LibreSSL devs have removed all SSLv2 function calls. Luckily, Debian had a patch to remove SSLv2 that I could use.
libesmtp / gwenhywfar
Some DES-related functions (DES is the old Data Encryption Standard) in OpenSSL are available in two forms: With uppercase DES_ and with lowercase des_. I can only guess that the des_ variants are for backwards compatibliity with some very old versions of OpenSSL. According to the docs the DES_ variants should be used. LibreSSL has removed the des_ variants.
For gwenhywfar I wrote a small patch and sent it upstream. For libesmtp all the code was in ntlm. After reading that ntlm is an ancient, proprietary Microsoft authentication protocol I decided that I don't need that anyway so I just added --disable-ntlm to the ebuild.
Dovecot
In Dovecot two issues popped up. LibreSSL removed the SSL Compression functionality (which is good, because since the CRIME attack we know it's not secure). Dovecot's configure script checks for it, but the check doesn't work. It checks for a function that LibreSSL keeps as a stub. For now I just disabled the check in the configure script. The solution is probably to remove all remaining stub functions. The configure script could probably also be changed to work in any case.
The second issue was that the Dovecot code has some #ifdef clauses that check the openssl version number for the ECDH auto functionality that has been added in OpenSSL 1.0.2 beta versions. As the LibreSSL version number 2.0 is higher than 1.0.2 it thinks it is newer and tries to enable it, but the code is not present in LibreSSL. I changed the #ifdefs to check for the actual functionality by checking a constant defined by the ECDH auto code.
Apache httpd
The Apache http compilation complained about a missing ENGINE_CTRL_CHIL_SET_FORKCHECK. I have no idea what it does, but I found a patch to fix the issue, so I didn't investigate it further.
Further reading:
Someone else tried to get things running on Sabotage Linux.
Update: I've abandoned my own libressl overlay, a LibreSSL overlay by various Gentoo developers is now maintained at GitHub.