Entries tagged as heartbleed
addresssanitizer afl americanfuzzylop asan bufferoverflow c clang fuzzing gcc gentoo linux memorysafety openssl security useafterfree bash altushost base64 css freesoftware ircbot malware script shellbot shellshock vulnerability web gimp sunras 23c3 27c3 3d 3ddrucker adobe amusementpark asia ati backnang beijing berlin beryl bios blob bonn camera canon ccc cellular chdk chemnitz china chromium cinderella cinelerra clt code codecs compiz compizfusion composite compression console copyright creativecommons csrf cve ddwrt debian desktop developingworld digitalcamera disney disneyland driver dvd eltorito evince exe fake ffmpeg film firefox firmware france freeculture freewvs freiegesellschaft freifunk frequencies frequency froscon froscon2007 fsf fsfe gaia games gargoyle ghost glibc gnome google googleearth graphics grub gsm hardware homebrew ibm ico icons icoutils iso itu ixus jugendumweltbewegung jukss karlsruhe kde königswusterhausen kpdf laptop lenovo lessig license lpi lpic lspci lsusb lug memdisk messe microsoft mobilephones movie musik nancy nessus nouveau nvidia ökologie okular olpc openbsc openbts openexpo opengl opensourceexpo openstreetmap openvas osmocombb pciids pdf phoronix php poppler presse privacy rapidprototyping rar realmedia realvideo redhat reprap retrogames reverseengineering rmll router rv30 rv40 s9y science sciencefiction serendipity sfd shijingshan siegburg simcity society softwarefreedomday sqlinjection stepmania sumatrapdf syslinux talk theory thesource theunarchiver thinkpad travel trip2011 tuxmas unar usbids video videoediting wii wiibrew wiki windows windowsrefund wiretapping wos wos4 wrestool xorg xss clamav zzuf 1und1 4k ac100 aiglx android apache apt artikel assembler augsburg augsburgerallgemeine bahn cacert cardreader ccwn come2linux core coredump cpu cpufreq crash cryptography darmstadt deb delilinux demoscene distribution dmidecode drm english entropia essen esslingen fedora fma86t frankreich freedesktop gadgets gammu gatos gnokii gnupg gpg gphoto gpn gpn5 grsecurity gtk hacker harddisk hash hddtemp howto hp http inkscape installparty iptables kgtk kubuntu libressl lit07 lm_sensors ludwigsburg luga lugbk macos mandriva md5 memorystick metisse mobile motherboard mplayer mrmcd mrmcd101b multimedia network nokia notebook omnibook openbsd openpgp overheatd overheating packagemanagement passwörter pcmagazin pcmcia pgp programming proxy ptp qt r300 radeon randr12 ricoh rpm samsung schokokeks sd sdricohcs segfault server sha1 signatures smart smartbook smartmontools sncf squid ssl standards subnotebook support symlink t61 time tls toshiba tv tvout ubuntu unicode usability usb utf-8 vc-1 vista vortrag waiblingen web20 webhosting webinale webroot websecurity webserver win32codecs wine wlan wmv x1carbon xgl zeitung berserk bleichenbacher ca certificate certificateauthority chrome email encryption https nss poodle privatekey rc2 rsa smime sni symantec x509 0days adguard aead aes afra algorithm antivir antivirus aok auskunftsanspruch axfr azure badkeys barcamp bias bigbluebutton blog bodensee botnetz braunschweig browser bsi bsideshn bugbounty bundesdatenschutzgesetz bundestrojaner bundesverfassungsgericht busby bypass cbc cccamp11 cfb chcounter clickjacking cloudflare cmi cms conflictofinterest cookie crypto datenschutz dell deolalikar diffiehellman dingens diploma diplomarbeit distributions dns domain drupal easterhegg edellroot eff eplus facebook fileexfiltration firewall fortigate fortinet forwardsecrecy freak ftp gajim gallery git gnutls gobi gsoc gstreamer hackerone hacking hannover helma infoleak informationdisclosure internetscan itsecurity jabber javascript jodconverter joomla kaspersky key keyexchange komodia leak libreoffice luckythirteen maninthemiddle mantis math mephisto milleniumproblems mitm modulobias moodle mozilla mpaa mrmcd100b mysql napster netfiltersdk newspaper nist ntp ntpd observatory onlinedurchsuchung openid openidconnect openleaks otr owncloud padding panda papierlos password passwordalert passwort pdo phishing pnp privdog protocolfilters provablesecurity pss python rand random rhein rsapss rss salinecourier schlüssel session sha2 sha256 sha512 sicherheit slides snallygaster sniffing spam squirrelmail sso staatsanwaltschaft stacktrace study stuttgart subdomain superfish taz thesis tlsdate toendacms transvalid überwachung unicef update updates userdir verschlüsselung virus vlc vulnerabilities webapps webmontag wiesbaden windowsxp wordpress xine xmpp xsa zerodays zugangsdaten bugtracker github nextcloud
Tuesday, April 7. 2015
How Heartbleed could've been found
 tl;dr With a reasonably simple fuzzing setup I was able to rediscover the Heartbleed bug. This uses state-of-the-art fuzzing and memory protection technology (american fuzzy lop and Address Sanitizer), but it doesn't require any prior knowledge about specifics of the Heartbleed bug or the TLS Heartbeat extension. We can learn from this to find similar bugs in the future.
tl;dr With a reasonably simple fuzzing setup I was able to rediscover the Heartbleed bug. This uses state-of-the-art fuzzing and memory protection technology (american fuzzy lop and Address Sanitizer), but it doesn't require any prior knowledge about specifics of the Heartbleed bug or the TLS Heartbeat extension. We can learn from this to find similar bugs in the future.Exactly one year ago a bug in the OpenSSL library became public that is one of the most well-known security bug of all time: Heartbleed. It is a bug in the code of a TLS extension that up until then was rarely known by anybody. A read buffer overflow allowed an attacker to extract parts of the memory of every server using OpenSSL.
Can we find Heartbleed with fuzzing?
Heartbleed was introduced in OpenSSL 1.0.1, which was released in March 2012, two years earlier. Many people wondered how it could've been hidden there for so long. David A. Wheeler wrote an essay discussing how fuzzing and memory protection technologies could've detected Heartbleed. It covers many aspects in detail, but in the end he only offers speculation on whether or not fuzzing would have found Heartbleed. So I wanted to try it out.
Of course it is easy to find a bug if you know what you're looking for. As best as reasonably possible I tried not to use any specific information I had about Heartbleed. I created a setup that's reasonably simple and similar to what someone would also try it without knowing anything about the specifics of Heartbleed.
Heartbleed is a read buffer overflow. What that means is that an application is reading outside the boundaries of a buffer. For example, imagine an application has a space in memory that's 10 bytes long. If the software tries to read 20 bytes from that buffer, you have a read buffer overflow. It will read whatever is in the memory located after the 10 bytes. These bugs are fairly common and the basic concept of exploiting buffer overflows is pretty old. Just to give you an idea how old: Recently the Chaos Computer Club celebrated the 30th anniversary of a hack of the German BtX-System, an early online service. They used a buffer overflow that was in many aspects very similar to the Heartbleed bug. (It is actually disputed if this is really what happened, but it seems reasonably plausible to me.)
Fuzzing is a widely used strategy to find security issues and bugs in software. The basic idea is simple: Give the software lots of inputs with small errors and see what happens. If the software crashes you likely found a bug.
When buffer overflows happen an application doesn't always crash. Often it will just read (or write if it is a write overflow) to the memory that happens to be there. Whether it crashes depends on a lot of circumstances. Most of the time read overflows won't crash your application. That's also the case with Heartbleed. There are a couple of technologies that improve the detection of memory access errors like buffer overflows. An old and well-known one is the debugging tool Valgrind. However Valgrind slows down applications a lot (around 20 times slower), so it is not really well suited for fuzzing, where you want to run an application millions of times on different inputs.
Address Sanitizer finds more bug
A better tool for our purpose is Address Sanitizer. David A. Wheeler calls it “nothing short of amazing”, and I want to reiterate that. I think it should be a tool that every C/C++ software developer should know and should use for testing.
Address Sanitizer is part of the C compiler and has been included into the two most common compilers in the free software world, gcc and llvm. To use Address Sanitizer one has to recompile the software with the command line parameter -fsanitize=address . It slows down applications, but only by a relatively small amount. According to their own numbers an application using Address Sanitizer is around 1.8 times slower. This makes it feasible for fuzzing tasks.
For the fuzzing itself a tool that recently gained a lot of popularity is american fuzzy lop (afl). This was developed by Michal Zalewski from the Google security team, who is also known by his nick name lcamtuf. As far as I'm aware the approach of afl is unique. It adds instructions to an application during the compilation that allow the fuzzer to detect new code paths while running the fuzzing tasks. If a new interesting code path is found then the sample that created this code path is used as the starting point for further fuzzing.
Currently afl only uses file inputs and cannot directly fuzz network input. OpenSSL has a command line tool that allows all kinds of file inputs, so you can use it for example to fuzz the certificate parser. But this approach does not allow us to directly fuzz the TLS connection, because that only happens on the network layer. By fuzzing various file inputs I recently found two issues in OpenSSL, but both had been found by Brian Carpenter before, who at the same time was also fuzzing OpenSSL.
Let OpenSSL talk to itself
So to fuzz the TLS network connection I had to create a workaround. I wrote a small application that creates two instances of OpenSSL that talk to each other. This application doesn't do any real networking, it is just passing buffers back and forth and thus doing a TLS handshake between a server and a client. Each message packet is written down to a file. It will result in six files, but the last two are just empty, because at that point the handshake is finished and no more data is transmitted. So we have four files that contain actual data from a TLS handshake. If you want to dig into this, a good description of a TLS handshake is provided by the developers of OCaml-TLS and MirageOS.
Then I added the possibility of switching out parts of the handshake messages by files I pass on the command line. By calling my test application selftls with a number and a filename a handshake message gets replaced by this file. So to test just the first part of the server handshake I'd call the test application, take the output file packed-1 and pass it back again to the application by running selftls 1 packet-1. Now we have all the pieces we need to use american fuzzy lop and fuzz the TLS handshake.
I compiled OpenSSL 1.0.1f, the last version that was vulnerable to Heartbleed, with american fuzzy lop. This can be done by calling ./config and then replacing gcc in the Makefile with afl-gcc. Also we want to use Address Sanitizer, to do so we have to set the environment variable AFL_USE_ASAN to 1.
There are some issues when using Address Sanitizer with american fuzzy lop. Address Sanitizer needs a lot of virtual memory (many Terabytes). American fuzzy lop limits the amount of memory an application may use. It is not trivially possible to only limit the real amount of memory an application uses and not the virtual amount, therefore american fuzzy lop cannot handle this flawlessly. Different solutions for this problem have been proposed and are currently developed. I usually go with the simplest solution: I just disable the memory limit of afl (parameter -m -1). This poses a small risk: A fuzzed input may lead an application to a state where it will use all available memory and thereby will cause other applications on the same system to malfuction. Based on my experience this is very rare, so I usually just ignore that potential problem.
After having compiled OpenSSL 1.0.1f we have two files libssl.a and libcrypto.a. These are static versions of OpenSSL and we will use them for our test application. We now also use the afl-gcc to compile our test application:
AFL_USE_ASAN=1 afl-gcc selftls.c -o selftls libssl.a libcrypto.a -ldl
Now we run the application. It needs a dummy certificate. I have put one in the repo. To make things faster I'm using a 512 bit RSA key. This is completely insecure, but as we don't want any security here – we just want to find bugs – this is fine, because a smaller key makes things faster. However if you want to try fuzzing the latest OpenSSL development code you need to create a larger key, because it'll refuse to accept such small keys.
The application will give us six packet files, however the last two will be empty. We only want to fuzz the very first step of the handshake, so we're interested in the first packet. We will create an input directory for american fuzzy lop called in and place packet-1 in it. Then we can run our fuzzing job:
afl-fuzz -i in -o out -m -1 -t 5000 ./selftls 1 @@
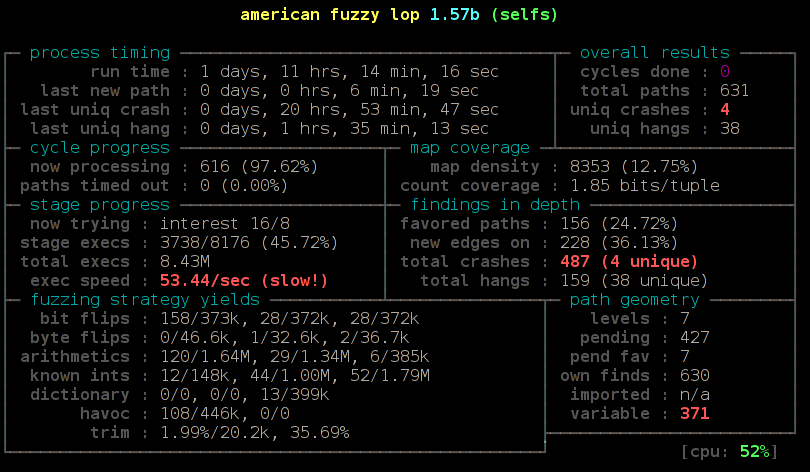
We pass the input and output directory, disable the memory limit and increase the timeout value, because TLS handshakes are slower than common fuzzing tasks. On my test machine around 6 hours later afl found the first crash. Now we can manually pass our output to the test application and will get a stack trace by Address Sanitizer:
==2268==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x629000013748 at pc 0x7f228f5f0cfa bp 0x7fffe8dbd590 sp 0x7fffe8dbcd38
READ of size 32768 at 0x629000013748 thread T0
#0 0x7f228f5f0cf9 (/usr/lib/gcc/x86_64-pc-linux-gnu/4.9.2/libasan.so.1+0x2fcf9)
#1 0x43d075 in memcpy /usr/include/bits/string3.h:51
#2 0x43d075 in tls1_process_heartbeat /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/t1_lib.c:2586
#3 0x50e498 in ssl3_read_bytes /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_pkt.c:1092
#4 0x51895c in ssl3_get_message /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_both.c:457
#5 0x4ad90b in ssl3_get_client_hello /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_srvr.c:941
#6 0x4c831a in ssl3_accept /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_srvr.c:357
#7 0x412431 in main /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/selfs.c:85
#8 0x7f228f03ff9f in __libc_start_main (/lib64/libc.so.6+0x1ff9f)
#9 0x4252a1 (/data/openssl/openssl-handshake/openssl-1.0.1f-nobreakrng-afl-asan-fuzz/selfs+0x4252a1)
0x629000013748 is located 0 bytes to the right of 17736-byte region [0x62900000f200,0x629000013748)
allocated by thread T0 here:
#0 0x7f228f6186f7 in malloc (/usr/lib/gcc/x86_64-pc-linux-gnu/4.9.2/libasan.so.1+0x576f7)
#1 0x57f026 in CRYPTO_malloc /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/crypto/mem.c:308
We can see here that the crash is a heap buffer overflow doing an invalid read access of around 32 Kilobytes in the function tls1_process_heartbeat(). It is the Heartbleed bug. We found it.
I want to mention a couple of things that I found out while trying this. I did some things that I thought were necessary, but later it turned out that they weren't. After Heartbleed broke the news a number of reports stated that Heartbleed was partly the fault of OpenSSL's memory management. A mail by Theo De Raadt claiming that OpenSSL has “exploit mitigation countermeasures” was widely quoted. I was aware of that, so I first tried to compile OpenSSL without its own memory management. That can be done by calling ./config with the option no-buf-freelist.
But it turns out although OpenSSL uses its own memory management that doesn't defeat Address Sanitizer. I could replicate my fuzzing finding with OpenSSL compiled with its default options. Although it does its own allocation management, it will still do a call to the system's normal malloc() function for every new memory allocation. A blog post by Chris Rohlf digs into the details of the OpenSSL memory allocator.
Breaking random numbers for deterministic behaviour
When fuzzing the TLS handshake american fuzzy lop will report a red number counting variable runs of the application. The reason for that is that a TLS handshake uses random numbers to create the master secret that's later used to derive cryptographic keys. Also the RSA functions will use random numbers. I wrote a patch to OpenSSL to deliberately break the random number generator and let it only output ones (it didn't work with zeros, because OpenSSL will wait for non-zero random numbers in the RSA function).
During my tests this had no noticeable impact on the time it took afl to find Heartbleed. Still I think it is a good idea to remove nondeterministic behavior when fuzzing cryptographic applications. Later in the handshake there are also timestamps used, this can be circumvented with libfaketime, but for the initial handshake processing that I fuzzed to find Heartbleed that doesn't matter.
Conclusion
You may ask now what the point of all this is. Of course we already know where Heartbleed is, it has been patched, fixes have been deployed and it is mostly history. It's been analyzed thoroughly.
The question has been asked if Heartbleed could've been found by fuzzing. I'm confident to say the answer is yes. One thing I should mention here however: American fuzzy lop was already available back then, but it was barely known. It only received major attention later in 2014, after Michal Zalewski used it to find two variants of the Shellshock bug. Earlier versions of afl were much less handy to use, e. g. they didn't have 64 bit support out of the box. I remember that I failed to use an earlier version of afl with Address Sanitizer, it was only possible after a couple of issues were fixed. A lot of other things have been improved in afl, so at the time Heartbleed was found american fuzzy lop probably wasn't in a state that would've allowed to find it in an easy, straightforward way.
I think the takeaway message is this: We have powerful tools freely available that are capable of finding bugs like Heartbleed. We should use them and look for the other Heartbleeds that are still lingering in our software. Take a look at the Fuzzing Project if you're interested in further fuzzing work. There are beginner tutorials that I wrote with the idea in mind to show people that fuzzing is an easy way to find bugs and improve software quality.
I already used my sample application to fuzz the latest OpenSSL code. Nothing was found yet, but of course this could be further tweaked by trying different protocol versions, extensions and other variations in the handshake.
I also wrote a German article about this finding for the IT news webpage Golem.de.
Update:
I want to point out some feedback I got that I think is noteworthy.
On Twitter it was mentioned that Codenomicon actually found Heartbleed via fuzzing. There's a Youtube video from Codenomicon's Antti Karjalainen explaining the details. However the way they did this was quite different, they built a protocol specific fuzzer. The remarkable feature of afl is that it is very powerful without knowing anything specific about the used protocol. Also it should be noted that Heartbleed was found twice, the first one was Neel Mehta from Google.
Kostya Serebryany mailed me that he was able to replicate my findings with his own fuzzer which is part of LLVM, and it was even faster.
In the comments Michele Spagnuolo mentions that by compiling OpenSSL with -DOPENSSL_TLS_SECURITY_LEVEL=0 one can use very short and insecure RSA keys even in the latest version. Of course this shouldn't be done in production, but it is helpful for fuzzing and other testing efforts.
Monday, October 6. 2014
How to stop Bleeding Hearts and Shocking Shells
 The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.
The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.Heartbleed hit the news in April this year. A bug in OpenSSL that allowed to extract privat keys of encrypted connections. When a bug in Bash called Shellshock hit the news I was first hesistant to call it bigger than Heartbleed. But now I am pretty sure it is. While Heartbleed was big there were some things that alleviated the impact. It took some days till people found out how to practically extract private keys - and it still wasn't fast. And the most likely attack scenario - stealing a private key and pulling off a Man-in-the-Middle-attack - seemed something that'd still pose some difficulties to an attacker. It seemed that people who update their systems quickly (like me) weren't in any real danger.
Shellshock was different. It's astonishingly simple to use and real attacks started hours after it became public. If circumstances had been unfortunate there would've been a very real chance that my own servers could've been hit by it. I usually feel the IT stuff under my responsibility is pretty safe, so things like this scare me.
What OpenSSL and Bash have in common
Shortly after Heartbleed something became very obvious: The OpenSSL project wasn't in good shape. The software that pretty much everyone in the Internet uses to do encryption was run by a small number of underpaid people. People trying to contribute and submit patches were often ignored (I know that, I tried it). The truth about Bash looks even grimmer: It's a project mostly run by a single volunteer. And yet almost every large Internet company out there uses it. Apple installs it on every laptop. OpenSSL and Bash are crucial pieces of software and run on the majority of the servers that run the Internet. Yet they are very small projects backed by few people. Besides they are both quite old, you'll find tons of legacy code in them written more than a decade ago.
People like to rant about the code quality of software like OpenSSL and Bash. However I am not that concerned about these two projects. This is the upside of events like these: OpenSSL is probably much securer than it ever was and after the dust settles Bash will be a better piece of software. If you want to ask yourself where the next Heartbleed/Shellshock-alike bug will happen, ask this: What projects are there that are installed on almost every Linux system out there? And how many of them have a healthy community and received a good security audit lately?
Software installed on almost any Linux system
Let me propose a little experiment: Take your favorite Linux distribution, make a minimal installation without anything and look what's installed. These are the software projects you should worry about. To make things easier I did this for you. I took my own system of choice, Gentoo Linux, but the results wouldn't be very different on other distributions. The results are at at the bottom of this text. (I removed everything Gentoo-specific.) I admit this is oversimplifying things. Some of these provide more attack surface than others, we should probably worry more about the ones that are directly involved in providing network services.
After Heartbleed some people already asked questions like these. How could it happen that a project so essential to IT security is so underfunded? Some large companies acted and the result is the Core Infrastructure Initiative by the Linux Foundation, which already helped improving OpenSSL development. This is a great start and an example for an initiative of which we should have more. We should ask the large IT companies who are not part of that initiative what they are doing to improve overall Internet security.
Just to put this into perspective: A thorough security audit of a project like Bash would probably require a five figure number of dollars. For a small, volunteer driven project this is huge. For a company like Apple - the one that installed Bash on all their laptops - it's nearly nothing.
There's another recent development I find noteworthy. Google started Project Zero where they hired some of the brightest minds in IT security and gave them a single job: Search for security bugs. Not in Google's own software. In every piece of software out there. This is not merely an altruistic project. It makes sense for Google. They want the web to be a safer place - because the web is where they earn their money. I like that approach a lot and I have only one question to ask about it: Why doesn't every large IT company have a Project Zero?
Sparking interest
There's another aspect I want to talk about. After Heartbleed people started having a closer look at OpenSSL and found a number of small and one other quite severe issue. After Bash people instantly found more issues in the function parser and we now have six CVEs for Shellshock and friends. When a piece of software is affected by a severe security bug people start to look for more. I wonder what it'd take to have people looking at the projects that aren't in the spotlight.
I was brainstorming if we could have something like a "free software audit action day". A regular call where an important but neglected project is chosen and the security community is asked to have a look at it. This is just a vague idea for now, if you like it please leave a comment.
That's it. I refrain from having discussions whether bugs like Heartbleed or Shellshock disprove the "many eyes"-principle that free software advocates like to cite, because I think these discussions are a pointless waste of time. I'd like to discuss how to improve things. Let's start.
Here's the promised list of Gentoo packages in the standard installation:
bzip2
gzip
tar
unzip
xz-utils
nano
ca-certificates
mime-types
pax-utils
bash
build-docbook-catalog
docbook-xml-dtd
docbook-xsl-stylesheets
openjade
opensp
po4a
sgml-common
perl
python
elfutils
expat
glib
gmp
libffi
libgcrypt
libgpg-error
libpcre
libpipeline
libxml2
libxslt
mpc
mpfr
openssl
popt
Locale-gettext
SGMLSpm
TermReadKey
Text-CharWidth
Text-WrapI18N
XML-Parser
gperf
gtk-doc-am
intltool
pkgconfig
iputils
netifrc
openssh
rsync
wget
acl
attr
baselayout
busybox
coreutils
debianutils
diffutils
file
findutils
gawk
grep
groff
help2man
hwids
kbd
kmod
less
man-db
man-pages
man-pages-posix
net-tools
sed
shadow
sysvinit
tcp-wrappers
texinfo
util-linux
which
pambase
autoconf
automake
binutils
bison
flex
gcc
gettext
gnuconfig
libtool
m4
make
patch
e2fsprogs
udev
linux-headers
cracklib
db
e2fsprogs-libs
gdbm
glibc
libcap
ncurses
pam
readline
timezone-data
zlib
procps
psmisc
shared-mime-info