Entries tagged as openssl
addresssanitizer afl americanfuzzylop asan bufferoverflow c clang fuzzing gcc gentoo heartbleed linux memorysafety security useafterfree apache certificates cryptography datenschutz datensparsamkeit encryption grsecurity https itsecurity javascript karlsruhe letsencrypt mod_rewrite nginx ocsp ocspstapling php revocation serendipity sni ssl symlink tls userdir vortrag web web20 webhosting webmontag websecurity bash altushost base64 css freesoftware ircbot malware script shellbot shellshock vulnerability berserk bleichenbacher chrome firefox nss poodle gimp sunras ca cacert ccc certificate certificateauthority hash md5 privatekey rsa sha1 sha2 sha256 symantec transvalid x509 aiglx blog calendar come2linux compiz eff email english essen games ipv6 kubik ludwigsburg lug lugbk observatory openstreetmap planet rc2 schokokeks simplesharingextensions smime stadtmitte webinale wine xgl algorithm android browser cccamp11 cloudflare dell edellroot facebook maninthemiddle openleaks pss superfish taz updates windowsxp chromium crash diffiehellman forwardsecrecy keyexchange apt badkeys braunschweig bsideshn cccamp cccamp15 cmi crypto darmstadt deb debian deolalikar diploma diplomarbeit easterhegg enigma fedora fortigate fortinet gnupg gpg gsoc hannover http key keyserver leak libressl math milleniumproblems mitm modulobias mrmcd mrmcd101b nist openbsd openid openidconnect openpgp packagemanagement papierlos password pgp pnp privacy provablesecurity random revoke rpm rsapss schlüssel server sha512 signatures slides sso stuttgart talk thesis ubuntu unicode university utf-8 verschlüsselung wordpress abuse aok boranet botnet ddos etymologie lg ncable spam sprache virus aead aes cfb cms gajim jabber joomla otr owncloud rss update xmpp babelfish camera canon china chinese csrf gadgets gammu gnokii googletranslate gphoto josm journalist language mandarin media merkaartor mobile moodle nokia ptp russia russian s9y time translation travel universaltranslator writing xss clickjacking cve ffmpeg flash flv ftp ghost glibc gstreamer konqueror microsoft mozilla mplayer multimedia redhat video vlc xine xsa youtube zzuf 23c3 27c3 3d 3ddrucker adobe amusementpark asia ati backnang beijing berlin beryl bios blob bonn cellular chdk chemnitz cinderella cinelerra clt code codecs compizfusion composite compression console copyright creativecommons ddwrt desktop developingworld digitalcamera disney disneyland driver dvd eltorito evince exe fake film firmware france freeculture freewvs freiegesellschaft freifunk frequencies frequency froscon froscon2007 fsf fsfe gaia gargoyle gnome google googleearth graphics grub gsm hardware homebrew ibm ico icons icoutils iso itu ixus jugendumweltbewegung jukss kde königswusterhausen kpdf laptop lenovo lessig license lpi lpic lspci lsusb memdisk messe mobilephones movie musik nancy nessus nouveau nvidia ökologie okular olpc openbsc openbts openexpo opengl opensourceexpo openvas osmocombb pciids pdf phoronix poppler presse rapidprototyping rar realmedia realvideo reprap retrogames reverseengineering rmll router rv30 rv40 science sciencefiction sfd shijingshan siegburg simcity society softwarefreedomday sqlinjection stepmania sumatrapdf syslinux theory thesource theunarchiver thinkpad trip2011 tuxmas unar usbids videoediting wii wiibrew wiki windows windowsrefund wiretapping wos wos4 wrestool xorg clamav ac100 censorship developer freedomofspeech gebabbel gps gpsbabel idn iputils metacity mobiletrailexplorer notebook ping politics smartbook subnotebook toshiba x1carbon zensur adguard antivirus breach cookies crime freak heist kaspersky komodia netfiltersdk privdog protocolfilters samesite 1und1 4k artikel assembler augsburg augsburgerallgemeine bahn cardreader ccwn core coredump cpu cpufreq delilinux demoscene distribution dmidecode drm entropia esslingen fma86t frankreich freedesktop gatos gpn gpn5 gtk hacker harddisk hddtemp howto hp inkscape installparty iptables kgtk kubuntu lit07 lm_sensors luga macos mandriva memorystick metisse motherboard network omnibook overheatd overheating passwörter pcmagazin pcmcia programming proxy qt r300 radeon randr12 ricoh samsung sd sdricohcs segfault smart smartmontools sncf squid standards support t61 tv tvout usability usb vc-1 vista waiblingen webroot webserver win32codecs wlan wmv zeitung cbc gnutls luckythirteen padding factoring licenses mysmartgrid publicdomain rsaoaep 0days afra antivir auskunftsanspruch axfr azure barcamp bias bigbluebutton bodensee botnetz bsi bugbounty bundesdatenschutzgesetz bundestrojaner bundesverfassungsgericht busby bypass chcounter conflictofinterest cookie dingens distributions dns domain drupal eplus fileexfiltration firewall gallery git gobi hackerone hacking helma infoleak informationdisclosure internetscan jodconverter libreoffice mantis mephisto mpaa mrmcd100b mysql napster newspaper ntp ntpd onlinedurchsuchung panda passwordalert passwort pdo phishing python rand rhein salinecourier session sicherheit snallygaster sniffing squirrelmail staatsanwaltschaft stacktrace study subdomain tlsdate toendacms überwachung unicef vulnerabilities webapps wiesbaden zerodays zugangsdaten bugtracker github nextcloud content-security-policy csp
Thursday, July 20. 2017
How I tricked Symantec with a Fake Private Key
 Lately, some attention was drawn to a widespread problem with TLS certificates. Many people are accidentally publishing their private keys. Sometimes they are released as part of applications, in Github repositories or with common filenames on web servers.
Lately, some attention was drawn to a widespread problem with TLS certificates. Many people are accidentally publishing their private keys. Sometimes they are released as part of applications, in Github repositories or with common filenames on web servers.If a private key is compromised, a certificate authority is obliged to revoke it. The Baseline Requirements – a set of rules that browsers and certificate authorities agreed upon – regulate this and say that in such a case a certificate authority shall revoke the key within 24 hours (Section 4.9.1.1 in the current Baseline Requirements 1.4.8). These rules exist despite the fact that revocation has various problems and doesn’t work very well, but that’s another topic.
I reported various key compromises to certificate authorities recently and while not all of them reacted in time, they eventually revoked all certificates belonging to the private keys. I wondered however how thorough they actually check the key compromises. Obviously one would expect that they cryptographically verify that an exposed private key really is the private key belonging to a certificate.
I registered two test domains at a provider that would allow me to hide my identity and not show up in the whois information. I then ordered test certificates from Symantec (via their brand RapidSSL) and Comodo. These are the biggest certificate authorities and they both offer short term test certificates for free. I then tried to trick them into revoking those certificates with a fake private key.
Forging a private key
To understand this we need to get a bit into the details of RSA keys. In essence a cryptographic key is just a set of numbers. For RSA a public key consists of a modulus (usually named N) and a public exponent (usually called e). You don’t have to understand their mathematical meaning, just keep in mind: They’re nothing more than numbers.
An RSA private key is also just numbers, but more of them. If you have heard any introductory RSA descriptions you may know that a private key consists of a private exponent (called d), but in practice it’s a bit more. Private keys usually contain the full public key (N, e), the private exponent (d) and several other values that are redundant, but they are useful to speed up certain things. But just keep in mind that a public key consists of two numbers and a private key is a public key plus some additional numbers. A certificate ultimately is just a public key with some additional information (like the host name that says for which web page it’s valid) signed by a certificate authority.
A naive check whether a private key belongs to a certificate could be done by extracting the public key parts of both the certificate and the private key for comparison. However it is quite obvious that this isn’t secure. An attacker could construct a private key that contains the public key of an existing certificate and the private key parts of some other, bogus key. Obviously such a fake key couldn’t be used and would only produce errors, but it would survive such a naive check.
I created such fake keys for both domains and uploaded them to Pastebin. If you want to create such fake keys on your own here’s a script. To make my report less suspicious I searched Pastebin for real, compromised private keys belonging to certificates. This again shows how problematic the leakage of private keys is: I easily found seven private keys for Comodo certificates and three for Symantec certificates, plus several more for other certificate authorities, which I also reported. These additional keys allowed me to make my report to Symantec and Comodo less suspicious: I could hide my fake key report within other legitimate reports about a key compromise.
Symantec revoked a certificate based on a forged private key
 Comodo didn’t fall for it. They answered me that there is something wrong with this key. Symantec however answered me that they revoked all certificates – including the one with the fake private key.
Comodo didn’t fall for it. They answered me that there is something wrong with this key. Symantec however answered me that they revoked all certificates – including the one with the fake private key.No harm was done here, because the certificate was only issued for my own test domain. But I could’ve also fake private keys of other peoples' certificates. Very likely Symantec would have revoked them as well, causing downtimes for those sites. I even could’ve easily created a fake key belonging to Symantec’s own certificate.
The communication by Symantec with the domain owner was far from ideal. I first got a mail that they were unable to process my order. Then I got another mail about a “cancellation request”. They didn’t explain what really happened and that the revocation happened due to a key uploaded on Pastebin.
I then informed Symantec about the invalid key (from my “real” identity), claiming that I just noted there’s something wrong with it. At that point they should’ve been aware that they revoked the certificate in error. Then I contacted the support with my “domain owner” identity and asked why the certificate was revoked. The answer: “I wanted to inform you that your FreeSSL certificate was cancelled as during a log check it was determined that the private key was compromised.”
To summarize: Symantec never told the domain owner that the certificate was revoked due to a key leaked on Pastebin. I assume in all the other cases they also didn’t inform their customers. Thus they may have experienced a certificate revocation, but don’t know why. So they can’t learn and can’t improve their processes to make sure this doesn’t happen again. Also, Symantec still insisted to the domain owner that the key was compromised even after I already had informed them that the key was faulty.
How to check if a private key belongs to a certificate?
 In case you wonder how you properly check whether a private key belongs to a certificate you may of course resort to a Google search. And this was fascinating – and scary – to me: I searched Google for “check if private key matches certificate”. I got plenty of instructions. Almost all of them were wrong. The first result is a page from SSLShopper. They recommend to compare the MD5 hash of the modulus. That they use MD5 is not the problem here, the problem is that this is a naive check only comparing parts of the public key. They even provide a form to check this. (That they ask you to put your private key into a form is a different issue on its own, but at least they have a warning about this and recommend to check locally.)
In case you wonder how you properly check whether a private key belongs to a certificate you may of course resort to a Google search. And this was fascinating – and scary – to me: I searched Google for “check if private key matches certificate”. I got plenty of instructions. Almost all of them were wrong. The first result is a page from SSLShopper. They recommend to compare the MD5 hash of the modulus. That they use MD5 is not the problem here, the problem is that this is a naive check only comparing parts of the public key. They even provide a form to check this. (That they ask you to put your private key into a form is a different issue on its own, but at least they have a warning about this and recommend to check locally.)Furthermore we get the same wrong instructions from the University of Wisconsin, Comodo (good that their engineers were smart enough not to rely on their own documentation), tbs internet (“SSL expert since 1996”), ShellHacks, IBM and RapidSSL (aka Symantec). A post on Stackexchange is the only result that actually mentions a proper check for RSA keys. Two more Stackexchange posts are not related to RSA, I haven’t checked their solutions in detail.
Going to Google results page two among some unrelated links we find more wrong instructions and tools from Symantec (Update 2020: Link offline), SSL247 (“Symantec Specialist Partner Website Security” - they learned from the best) and some private blog. A documentation by Aspera (belonging to IBM) at least mentions that you can check the private key, but in an unrelated section of the document. Also we get more tools that ask you to upload your private key and then not properly check it from SSLChecker.com, the SSL Store (Symantec “Website Security Platinum Partner”), GlobeSSL (“in SSL we trust”) and - well - RapidSSL.
Documented Security Vulnerability in OpenSSL
So if people google for instructions they’ll almost inevitably end up with non-working instructions or tools. But what about other options? Let’s say we want to automate this and have a tool that verifies whether a certificate matches a private key using OpenSSL. We may end up finding that OpenSSL has a function
x509_check_private_key() that can be used to “check the consistency of a private key with the public key in an X509 certificate or certificate request”. Sounds like exactly what we need, right?Well, until you read the full docs and find out that it has a BUGS section: “The check_private_key functions don't check if k itself is indeed a private key or not. It merely compares the public materials (e.g. exponent and modulus of an RSA key) and/or key parameters (e.g. EC params of an EC key) of a key pair.”
I think this is a security vulnerability in OpenSSL (discussion with OpenSSL here). And that doesn’t change just because it’s a documented security vulnerability. Notably there are downstream consumers of this function that failed to copy that part of the documentation, see for example the corresponding PHP function (the limitation is however mentioned in a comment by a user).
So how do you really check whether a private key matches a certificate?
Ultimately there are two reliable ways to check whether a private key belongs to a certificate. One way is to check whether the various values of the private key are consistent and then check whether the public key matches. For example a private key contains values p and q that are the prime factors of the public modulus N. If you multiply them and compare them to N you can be sure that you have a legitimate private key. It’s one of the core properties of RSA that it’s secure based on the assumption that it’s not feasible to calculate p and q from N.
You can use OpenSSL to check the consistency of a private key:
openssl rsa -in [privatekey] -checkFor my forged keys it will tell you:
RSA key error: n does not equal p qYou can then compare the public key, for example by calculating the so-called SPKI SHA256 hash:
openssl pkey -in [privatekey] -pubout -outform der | sha256sumopenssl x509 -in [certificate] -pubkey |openssl pkey -pubin -pubout -outform der | sha256sumAnother way is to sign a message with the private key and then verify it with the public key. You could do it like this:
openssl x509 -in [certificate] -noout -pubkey > pubkey.pemdd if=/dev/urandom of=rnd bs=32 count=1openssl rsautl -sign -pkcs -inkey [privatekey] -in rnd -out sigopenssl rsautl -verify -pkcs -pubin -inkey pubkey.pem -in sig -out checkcmp rnd checkrm rnd check sig pubkey.pemIf cmp produces no output then the signature matches.
As this is all quite complex due to OpenSSLs arcane command line interface I have put this all together in a script. You can pass a certificate and a private key, both in ASCII/PEM format, and it will do both checks.
Summary
Symantec did a major blunder by revoking a certificate based on completely forged evidence. There’s hardly any excuse for this and it indicates that they operate a certificate authority without a proper understanding of the cryptographic background.
Apart from that the problem of checking whether a private key and certificate match seems to be largely documented wrong. Plenty of erroneous guides and tools may cause others to fall for the same trap.
Update: Symantec answered with a blog post.
Tuesday, April 7. 2015
How Heartbleed could've been found
 tl;dr With a reasonably simple fuzzing setup I was able to rediscover the Heartbleed bug. This uses state-of-the-art fuzzing and memory protection technology (american fuzzy lop and Address Sanitizer), but it doesn't require any prior knowledge about specifics of the Heartbleed bug or the TLS Heartbeat extension. We can learn from this to find similar bugs in the future.
tl;dr With a reasonably simple fuzzing setup I was able to rediscover the Heartbleed bug. This uses state-of-the-art fuzzing and memory protection technology (american fuzzy lop and Address Sanitizer), but it doesn't require any prior knowledge about specifics of the Heartbleed bug or the TLS Heartbeat extension. We can learn from this to find similar bugs in the future.Exactly one year ago a bug in the OpenSSL library became public that is one of the most well-known security bug of all time: Heartbleed. It is a bug in the code of a TLS extension that up until then was rarely known by anybody. A read buffer overflow allowed an attacker to extract parts of the memory of every server using OpenSSL.
Can we find Heartbleed with fuzzing?
Heartbleed was introduced in OpenSSL 1.0.1, which was released in March 2012, two years earlier. Many people wondered how it could've been hidden there for so long. David A. Wheeler wrote an essay discussing how fuzzing and memory protection technologies could've detected Heartbleed. It covers many aspects in detail, but in the end he only offers speculation on whether or not fuzzing would have found Heartbleed. So I wanted to try it out.
Of course it is easy to find a bug if you know what you're looking for. As best as reasonably possible I tried not to use any specific information I had about Heartbleed. I created a setup that's reasonably simple and similar to what someone would also try it without knowing anything about the specifics of Heartbleed.
Heartbleed is a read buffer overflow. What that means is that an application is reading outside the boundaries of a buffer. For example, imagine an application has a space in memory that's 10 bytes long. If the software tries to read 20 bytes from that buffer, you have a read buffer overflow. It will read whatever is in the memory located after the 10 bytes. These bugs are fairly common and the basic concept of exploiting buffer overflows is pretty old. Just to give you an idea how old: Recently the Chaos Computer Club celebrated the 30th anniversary of a hack of the German BtX-System, an early online service. They used a buffer overflow that was in many aspects very similar to the Heartbleed bug. (It is actually disputed if this is really what happened, but it seems reasonably plausible to me.)
Fuzzing is a widely used strategy to find security issues and bugs in software. The basic idea is simple: Give the software lots of inputs with small errors and see what happens. If the software crashes you likely found a bug.
When buffer overflows happen an application doesn't always crash. Often it will just read (or write if it is a write overflow) to the memory that happens to be there. Whether it crashes depends on a lot of circumstances. Most of the time read overflows won't crash your application. That's also the case with Heartbleed. There are a couple of technologies that improve the detection of memory access errors like buffer overflows. An old and well-known one is the debugging tool Valgrind. However Valgrind slows down applications a lot (around 20 times slower), so it is not really well suited for fuzzing, where you want to run an application millions of times on different inputs.
Address Sanitizer finds more bug
A better tool for our purpose is Address Sanitizer. David A. Wheeler calls it “nothing short of amazing”, and I want to reiterate that. I think it should be a tool that every C/C++ software developer should know and should use for testing.
Address Sanitizer is part of the C compiler and has been included into the two most common compilers in the free software world, gcc and llvm. To use Address Sanitizer one has to recompile the software with the command line parameter -fsanitize=address . It slows down applications, but only by a relatively small amount. According to their own numbers an application using Address Sanitizer is around 1.8 times slower. This makes it feasible for fuzzing tasks.
For the fuzzing itself a tool that recently gained a lot of popularity is american fuzzy lop (afl). This was developed by Michal Zalewski from the Google security team, who is also known by his nick name lcamtuf. As far as I'm aware the approach of afl is unique. It adds instructions to an application during the compilation that allow the fuzzer to detect new code paths while running the fuzzing tasks. If a new interesting code path is found then the sample that created this code path is used as the starting point for further fuzzing.
Currently afl only uses file inputs and cannot directly fuzz network input. OpenSSL has a command line tool that allows all kinds of file inputs, so you can use it for example to fuzz the certificate parser. But this approach does not allow us to directly fuzz the TLS connection, because that only happens on the network layer. By fuzzing various file inputs I recently found two issues in OpenSSL, but both had been found by Brian Carpenter before, who at the same time was also fuzzing OpenSSL.
Let OpenSSL talk to itself
So to fuzz the TLS network connection I had to create a workaround. I wrote a small application that creates two instances of OpenSSL that talk to each other. This application doesn't do any real networking, it is just passing buffers back and forth and thus doing a TLS handshake between a server and a client. Each message packet is written down to a file. It will result in six files, but the last two are just empty, because at that point the handshake is finished and no more data is transmitted. So we have four files that contain actual data from a TLS handshake. If you want to dig into this, a good description of a TLS handshake is provided by the developers of OCaml-TLS and MirageOS.
Then I added the possibility of switching out parts of the handshake messages by files I pass on the command line. By calling my test application selftls with a number and a filename a handshake message gets replaced by this file. So to test just the first part of the server handshake I'd call the test application, take the output file packed-1 and pass it back again to the application by running selftls 1 packet-1. Now we have all the pieces we need to use american fuzzy lop and fuzz the TLS handshake.
I compiled OpenSSL 1.0.1f, the last version that was vulnerable to Heartbleed, with american fuzzy lop. This can be done by calling ./config and then replacing gcc in the Makefile with afl-gcc. Also we want to use Address Sanitizer, to do so we have to set the environment variable AFL_USE_ASAN to 1.
There are some issues when using Address Sanitizer with american fuzzy lop. Address Sanitizer needs a lot of virtual memory (many Terabytes). American fuzzy lop limits the amount of memory an application may use. It is not trivially possible to only limit the real amount of memory an application uses and not the virtual amount, therefore american fuzzy lop cannot handle this flawlessly. Different solutions for this problem have been proposed and are currently developed. I usually go with the simplest solution: I just disable the memory limit of afl (parameter -m -1). This poses a small risk: A fuzzed input may lead an application to a state where it will use all available memory and thereby will cause other applications on the same system to malfuction. Based on my experience this is very rare, so I usually just ignore that potential problem.
After having compiled OpenSSL 1.0.1f we have two files libssl.a and libcrypto.a. These are static versions of OpenSSL and we will use them for our test application. We now also use the afl-gcc to compile our test application:
AFL_USE_ASAN=1 afl-gcc selftls.c -o selftls libssl.a libcrypto.a -ldl
Now we run the application. It needs a dummy certificate. I have put one in the repo. To make things faster I'm using a 512 bit RSA key. This is completely insecure, but as we don't want any security here – we just want to find bugs – this is fine, because a smaller key makes things faster. However if you want to try fuzzing the latest OpenSSL development code you need to create a larger key, because it'll refuse to accept such small keys.
The application will give us six packet files, however the last two will be empty. We only want to fuzz the very first step of the handshake, so we're interested in the first packet. We will create an input directory for american fuzzy lop called in and place packet-1 in it. Then we can run our fuzzing job:
afl-fuzz -i in -o out -m -1 -t 5000 ./selftls 1 @@
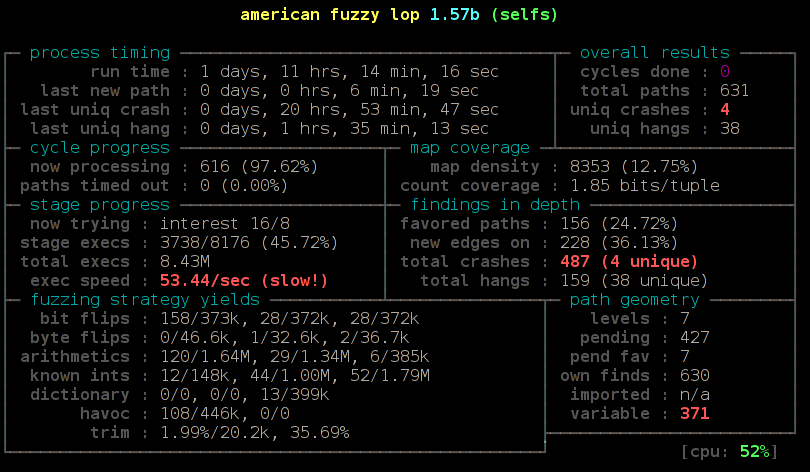
We pass the input and output directory, disable the memory limit and increase the timeout value, because TLS handshakes are slower than common fuzzing tasks. On my test machine around 6 hours later afl found the first crash. Now we can manually pass our output to the test application and will get a stack trace by Address Sanitizer:
==2268==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x629000013748 at pc 0x7f228f5f0cfa bp 0x7fffe8dbd590 sp 0x7fffe8dbcd38
READ of size 32768 at 0x629000013748 thread T0
#0 0x7f228f5f0cf9 (/usr/lib/gcc/x86_64-pc-linux-gnu/4.9.2/libasan.so.1+0x2fcf9)
#1 0x43d075 in memcpy /usr/include/bits/string3.h:51
#2 0x43d075 in tls1_process_heartbeat /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/t1_lib.c:2586
#3 0x50e498 in ssl3_read_bytes /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_pkt.c:1092
#4 0x51895c in ssl3_get_message /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_both.c:457
#5 0x4ad90b in ssl3_get_client_hello /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_srvr.c:941
#6 0x4c831a in ssl3_accept /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_srvr.c:357
#7 0x412431 in main /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/selfs.c:85
#8 0x7f228f03ff9f in __libc_start_main (/lib64/libc.so.6+0x1ff9f)
#9 0x4252a1 (/data/openssl/openssl-handshake/openssl-1.0.1f-nobreakrng-afl-asan-fuzz/selfs+0x4252a1)
0x629000013748 is located 0 bytes to the right of 17736-byte region [0x62900000f200,0x629000013748)
allocated by thread T0 here:
#0 0x7f228f6186f7 in malloc (/usr/lib/gcc/x86_64-pc-linux-gnu/4.9.2/libasan.so.1+0x576f7)
#1 0x57f026 in CRYPTO_malloc /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/crypto/mem.c:308
We can see here that the crash is a heap buffer overflow doing an invalid read access of around 32 Kilobytes in the function tls1_process_heartbeat(). It is the Heartbleed bug. We found it.
I want to mention a couple of things that I found out while trying this. I did some things that I thought were necessary, but later it turned out that they weren't. After Heartbleed broke the news a number of reports stated that Heartbleed was partly the fault of OpenSSL's memory management. A mail by Theo De Raadt claiming that OpenSSL has “exploit mitigation countermeasures” was widely quoted. I was aware of that, so I first tried to compile OpenSSL without its own memory management. That can be done by calling ./config with the option no-buf-freelist.
But it turns out although OpenSSL uses its own memory management that doesn't defeat Address Sanitizer. I could replicate my fuzzing finding with OpenSSL compiled with its default options. Although it does its own allocation management, it will still do a call to the system's normal malloc() function for every new memory allocation. A blog post by Chris Rohlf digs into the details of the OpenSSL memory allocator.
Breaking random numbers for deterministic behaviour
When fuzzing the TLS handshake american fuzzy lop will report a red number counting variable runs of the application. The reason for that is that a TLS handshake uses random numbers to create the master secret that's later used to derive cryptographic keys. Also the RSA functions will use random numbers. I wrote a patch to OpenSSL to deliberately break the random number generator and let it only output ones (it didn't work with zeros, because OpenSSL will wait for non-zero random numbers in the RSA function).
During my tests this had no noticeable impact on the time it took afl to find Heartbleed. Still I think it is a good idea to remove nondeterministic behavior when fuzzing cryptographic applications. Later in the handshake there are also timestamps used, this can be circumvented with libfaketime, but for the initial handshake processing that I fuzzed to find Heartbleed that doesn't matter.
Conclusion
You may ask now what the point of all this is. Of course we already know where Heartbleed is, it has been patched, fixes have been deployed and it is mostly history. It's been analyzed thoroughly.
The question has been asked if Heartbleed could've been found by fuzzing. I'm confident to say the answer is yes. One thing I should mention here however: American fuzzy lop was already available back then, but it was barely known. It only received major attention later in 2014, after Michal Zalewski used it to find two variants of the Shellshock bug. Earlier versions of afl were much less handy to use, e. g. they didn't have 64 bit support out of the box. I remember that I failed to use an earlier version of afl with Address Sanitizer, it was only possible after a couple of issues were fixed. A lot of other things have been improved in afl, so at the time Heartbleed was found american fuzzy lop probably wasn't in a state that would've allowed to find it in an easy, straightforward way.
I think the takeaway message is this: We have powerful tools freely available that are capable of finding bugs like Heartbleed. We should use them and look for the other Heartbleeds that are still lingering in our software. Take a look at the Fuzzing Project if you're interested in further fuzzing work. There are beginner tutorials that I wrote with the idea in mind to show people that fuzzing is an easy way to find bugs and improve software quality.
I already used my sample application to fuzz the latest OpenSSL code. Nothing was found yet, but of course this could be further tweaked by trying different protocol versions, extensions and other variations in the handshake.
I also wrote a German article about this finding for the IT news webpage Golem.de.
Update:
I want to point out some feedback I got that I think is noteworthy.
On Twitter it was mentioned that Codenomicon actually found Heartbleed via fuzzing. There's a Youtube video from Codenomicon's Antti Karjalainen explaining the details. However the way they did this was quite different, they built a protocol specific fuzzer. The remarkable feature of afl is that it is very powerful without knowing anything specific about the used protocol. Also it should be noted that Heartbleed was found twice, the first one was Neel Mehta from Google.
Kostya Serebryany mailed me that he was able to replicate my findings with his own fuzzer which is part of LLVM, and it was even faster.
In the comments Michele Spagnuolo mentions that by compiling OpenSSL with -DOPENSSL_TLS_SECURITY_LEVEL=0 one can use very short and insecure RSA keys even in the latest version. Of course this shouldn't be done in production, but it is helpful for fuzzing and other testing efforts.
Tuesday, November 4. 2014
Dancing protocols, POODLEs and other tales from TLS

The latest SSL attack was called POODLE. Image source
{kind=link}
.
I think it is crucial to understand what led to these vulnerabilities. I find POODLE and BERserk so interesting because these two vulnerabilities were both unnecessary and could've been avoided by intelligent design choices. Okay, let's start by investigating what went wrong.
The mess with CBC
POODLE (Padding Oracle On Downgraded Legacy Encryption) is a weakness in the CBC block mode and the padding of the old SSL protocol. If you've followed previous stories about SSL/TLS vulnerabilities this shouldn't be news. There have been a whole number of CBC-related vulnerabilities, most notably the Padding oracle (2003), the BEAST attack (2011) and the Lucky Thirteen attack (2013) (Lucky Thirteen is kind of my favorite, because it was already more or less mentioned in the TLS 1.2 standard). The POODLE attack builds on ideas already used in previous attacks.
CBC is a so-called block mode. For now it should be enough to understand that we have two kinds of ciphers we use to authenticate and encrypt connections – block ciphers and stream ciphers. Block ciphers need a block mode to operate. There's nothing necessarily wrong with CBC, it's the way CBC is used in SSL/TLS that causes problems. There are two weaknesses in it: Early versions (before TLS 1.1) use a so-called implicit Initialization Vector (IV) and they use a method called MAC-then-Encrypt (used up until the very latest TLS 1.2, but there's a new extension to fix it) which turned out to be quite fragile when it comes to security. The CBC details would be a topic on their own and I won't go into the details now. The long-term goal should be to get rid of all these (old-style) CBC modes, however that won't be possible for quite some time due to compatibility reasons. As most of these problems have been known since 2003 it's about time.
The evil Protocol Dance
The interesting question with POODLE is: Why does a security issue in an ancient protocol like SSLv3 bother us at all? SSL was developed by Netscape in the mid 90s, it has two public versions: SSLv2 and SSLv3. In 1999 (15 years ago) the old SSL was deprecated and replaced with TLS 1.0 standardized by the IETF. Now people still used SSLv3 up until very recently mostly for compatibility reasons. But even that in itself isn't the problem. SSL/TLS has a mechanism to safely choose the best protocol available. In a nutshell it works like this:
a) A client (e. g. a browser) connects to a server and may say something like "I want to connect with TLS 1.2“
b) The server may answer "No, sorry, I don't understand TLS 1.2, can you please connect with TLS 1.0?“
c) The client says "Ok, let's connect with TLS 1.0“
The point here is: Even if both server and client support the ancient SSLv3, they'd usually not use it. But this is the idealized world of standards. Now welcome to the real world, where things like this happen:
a) A client (e. g. a browser) connects to a server and may say something like "I want to connect with TLS 1.2“
b) The server thinks "Oh, TLS 1.2, never heard of that. What should I do? I better say nothing at all...“
c) The browser thinks "Ok, server doesn't answer, maybe we should try something else. Hey, server, I want to connect with TLS 1.1“
d) The browser will retry all SSL versions down to SSLv3 till it can connect.

The Protocol Dance is a Dance with the Devil. Image source
I first encountered the Protocol Dance back in 2008. Back then I already used a technology called SNI (Server Name Indication) that allows to have multiple websites with multiple certificates on a single IP address. I regularly got complains from people who saw the wrong certificates on those SNI webpages. A bug report to Firefox and some analysis revealed the reason: The protocol downgrades don't just happen when servers don't answer to new protocol requests, they also can happen on faulty or weak internet connections. SSLv3 does not support SNI, so when a downgrade to SSLv3 happens you get the wrong certificate. This was quite frustrating: A compatibility feature that was purely there to support broken hardware caused my completely legit setup to fail every now and then.
But the more severe problem is this: The Protocol Dance will allow an attacker to force downgrades to older (less secure) protocols. He just has to stop connection attempts with the more secure protocols. And this is why the POODLE attack was an issue after all: The problem was not backwards compatibility. The problem was attacker-controlled backwards compatibility.
The idea that the Protocol Dance might be a security issue wasn't completely new either. At the Black Hat conference this year Antoine Delignat-Lavaud presented a variant of an attack he calls "Virtual Host Confusion“ where he relied on downgrading connections to force SSLv3 connections.
"Whoever breaks it first“ - principle
The Protocol Dance is an example for something that I feel is an unwritten rule of browser development today: Browser vendors don't want things to break – even if the breakage is the fault of someone else. So they add all kinds of compatibility technologies that are purely there to support broken hardware. The idea is: When someone introduced broken hardware at some point – and it worked because the brokenness wasn't triggered at that point – the broken stuff is allowed to stay and all others have to deal with it.
To avoid the Protocol Dance a new feature is now on its way: It's called SCSV and the idea is that the Protocol Dance is stopped if both the server and the client support this new protocol feature. I'm extremely uncomfortable with that solution because it just adds another layer of duct tape and increases the complexity of TLS which already is much too complex.
There's another recent example which is very similar: At some point people found out that BIG-IP load balancers by the company F5 had trouble with TLS connection attempts larger than 255 bytes. However it was later revealed that connection attempts bigger than 512 bytes also succeed. So a padding extension was invented and it's now widespread behaviour of TLS implementations to avoid connection attempts between 256 and 511 bytes. To make matters completely insane: It was later found out that there is other broken hardware – SMTP servers by Ironport – that breaks when the handshake is larger than 511 bytes.
I have a principle when it comes to fixing things: Fix it where its broken. But the browser world works differently. It works with the „whoever breaks it first defines the new standard of brokenness“-principle. This is partly due to an unhealthy competition between browsers. Unfortunately they often don't compete very well on the security level. What you'll constantly hear is that browsers can't break any webpages because that will lead to people moving to other browsers.
I'm not sure if I entirely buy this kind of reasoning. For a couple of months the support for the ftp protocol in Chrome / Chromium is broken. I'm no fan of plain, unencrypted ftp and its only legit use case – unauthenticated file download – can just as easily be fulfilled with unencrypted http, but there are a number of live ftp servers that implement a legit and working protocol. I like Chromium and it's my everyday browser, but for a while the broken ftp support was the most prevalent reason I tend to start Firefox. This little episode makes it hard for me to believe that they can't break connections to some (broken) ancient SSL servers. (I just noted that the very latest version of Chromium has fixed ftp support again.)
BERserk, small exponents and PKCS #1 1.5

We have a problem with weak keys. Image source
{kind=link}
BERserk is actually a variant of a quite old vulnerability (you may begin to see a pattern here): The Bleichenbacher attack on RSA first presented at Crypto 2006. Now here things get confusing, because the cryptographer Daniel Bleichenbacher found two independent vulnerabilities in RSA. One in the RSA encryption in 1998 and one in RSA signatures in 2006, for convenience I'll call them BB98 (encryption) and BB06 (signatures). Both of these vulnerabilities expose faulty implementations of the old RSA standard PKCS #1 1.5. And both are what I like to call "zombie vulnerabilities“. They keep coming back, no matter how often you try to fix them. In April the BB98 vulnerability was re-discovered in the code of Java and it was silently fixed in OpenSSL some time last year.
But BERserk is about the other one: BB06. BERserk exposes the fact that inside the RSA function an algorithm identifier for the used hash function is embedded and its encoded with BER. BER is part of ASN.1. I could tell horror stories about ASN.1, but I'll spare you that for now, maybe this is a topic for another blog entry. It's enough to know that it's a complicated format and this is what bites us here: With some trickery in the BER encoding one can add further data into the RSA function – and this allows in certain situations to create forged signatures.
One thing should be made clear: Both the original BB06 attack and BERserk are flaws in the implementation of PKCS #1 1.5. If you do everything correct then you're fine. These attacks exploit the relatively simple structure of the old PKCS standard and they only work when RSA is done with a very small exponent. RSA public keys consist of two large numbers. The modulus N (which is a product of two large primes) and the exponent.
In his presentation at Crypto 2006 Daniel Bleichenbacher already proposed what would have prevented this attack: Just don't use RSA keys with very small exponents like three. This advice also went into various recommendations (e. g. by NIST) and today almost everyone uses 65537 (the reason for this number is that due to its binary structure calculations with it are reasonably fast).
There's just one problem: A small number of keys are still there that use the exponent e=3. And six of them are used by root certificates installed in every browser. These root certificates are the trust anchor of TLS (which in itself is a problem, but that's another story). Here's our problem: As long as there is one single root certificate with e=3 with such an attack you can create as many fake certificates as you want. If we had deprecated e=3 keys BERserk would've been mostly a non-issue.
There is one more aspect of this story: What's this PKCS #1 1.5 thing anyway? It's an old standard for RSA encryption and signatures. I want to quote Adam Langley on the PKCS standards here: "In a modern light, they are all completely terrible. If you wanted something that was plausible enough to be widely implemented but complex enough to ensure that cryptography would forever be hamstrung by implementation bugs, you would be hard pressed to do better."
Now there's a successor to the PKCS #1 1.5 standard: PKCS #1 2.1, which is based on technologies called PSS (Probabilistic Signature Scheme) and OAEP (Optimal Asymmetric Encryption Padding). It's from 2002 and in many aspects it's much better. I am kind of a fan here, because I wrote my thesis about this. There's just one problem: Although already standardized 2002 people still prefer to use the much weaker old PKCS #1 1.5. TLS doesn't have any way to use the newer PKCS #1 2.1 and even the current drafts for TLS 1.3 stick to the older - and weaker - variant.
What to do
I would take bets that POODLE wasn't the last TLS/CBC-issue we saw and that BERserk wasn't the last variant of the BB06-attack. Basically, I think there are a number of things TLS implementers could do to prevent further similar attacks:
* The Protocol Dance should die. Don't put another layer of duct tape around it (SCSV), just get rid of it. It will break a small number of already broken devices, but that is a reasonable price for avoiding the next protocol downgrade attack scenario. Backwards compatibility shouldn't compromise security.
* More generally, I think the working around for broken devices has to stop. Replace the „whoever broke it first“ paradigm with a „fix it where its broken“ paradigm. That also means I think the padding extension should be scraped.
* Keys with weak choices need to be deprecated at some point. In a long process browsers removed most certificates with short 1024 bit keys. They're working hard on deprecating signatures with the weak SHA1 algorithm. I think e=3 RSA keys should be next on the list for deprecation.
* At some point we should deprecate the weak CBC modes. This is probably the trickiest part, because up until very recently TLS 1.0 was all that most major browsers supported. The only way to avoid them is either using the GCM mode of TLS 1.2 (most browsers just got support for that in recent months) or using a very new extension that's rarely used at all today.
* If we have better technologies we should start using them. PKCS #1 2.1 is clearly superior to PKCS #1 1.5, at least if new standards get written people should switch to it.
Update: I just read that Mozilla Firefox devs disabled the protocol dance in their latest nightly build. Let's hope others follow.
Monday, October 6. 2014
How to stop Bleeding Hearts and Shocking Shells
 The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.
The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.Heartbleed hit the news in April this year. A bug in OpenSSL that allowed to extract privat keys of encrypted connections. When a bug in Bash called Shellshock hit the news I was first hesistant to call it bigger than Heartbleed. But now I am pretty sure it is. While Heartbleed was big there were some things that alleviated the impact. It took some days till people found out how to practically extract private keys - and it still wasn't fast. And the most likely attack scenario - stealing a private key and pulling off a Man-in-the-Middle-attack - seemed something that'd still pose some difficulties to an attacker. It seemed that people who update their systems quickly (like me) weren't in any real danger.
Shellshock was different. It's astonishingly simple to use and real attacks started hours after it became public. If circumstances had been unfortunate there would've been a very real chance that my own servers could've been hit by it. I usually feel the IT stuff under my responsibility is pretty safe, so things like this scare me.
What OpenSSL and Bash have in common
Shortly after Heartbleed something became very obvious: The OpenSSL project wasn't in good shape. The software that pretty much everyone in the Internet uses to do encryption was run by a small number of underpaid people. People trying to contribute and submit patches were often ignored (I know that, I tried it). The truth about Bash looks even grimmer: It's a project mostly run by a single volunteer. And yet almost every large Internet company out there uses it. Apple installs it on every laptop. OpenSSL and Bash are crucial pieces of software and run on the majority of the servers that run the Internet. Yet they are very small projects backed by few people. Besides they are both quite old, you'll find tons of legacy code in them written more than a decade ago.
People like to rant about the code quality of software like OpenSSL and Bash. However I am not that concerned about these two projects. This is the upside of events like these: OpenSSL is probably much securer than it ever was and after the dust settles Bash will be a better piece of software. If you want to ask yourself where the next Heartbleed/Shellshock-alike bug will happen, ask this: What projects are there that are installed on almost every Linux system out there? And how many of them have a healthy community and received a good security audit lately?
Software installed on almost any Linux system
Let me propose a little experiment: Take your favorite Linux distribution, make a minimal installation without anything and look what's installed. These are the software projects you should worry about. To make things easier I did this for you. I took my own system of choice, Gentoo Linux, but the results wouldn't be very different on other distributions. The results are at at the bottom of this text. (I removed everything Gentoo-specific.) I admit this is oversimplifying things. Some of these provide more attack surface than others, we should probably worry more about the ones that are directly involved in providing network services.
After Heartbleed some people already asked questions like these. How could it happen that a project so essential to IT security is so underfunded? Some large companies acted and the result is the Core Infrastructure Initiative by the Linux Foundation, which already helped improving OpenSSL development. This is a great start and an example for an initiative of which we should have more. We should ask the large IT companies who are not part of that initiative what they are doing to improve overall Internet security.
Just to put this into perspective: A thorough security audit of a project like Bash would probably require a five figure number of dollars. For a small, volunteer driven project this is huge. For a company like Apple - the one that installed Bash on all their laptops - it's nearly nothing.
There's another recent development I find noteworthy. Google started Project Zero where they hired some of the brightest minds in IT security and gave them a single job: Search for security bugs. Not in Google's own software. In every piece of software out there. This is not merely an altruistic project. It makes sense for Google. They want the web to be a safer place - because the web is where they earn their money. I like that approach a lot and I have only one question to ask about it: Why doesn't every large IT company have a Project Zero?
Sparking interest
There's another aspect I want to talk about. After Heartbleed people started having a closer look at OpenSSL and found a number of small and one other quite severe issue. After Bash people instantly found more issues in the function parser and we now have six CVEs for Shellshock and friends. When a piece of software is affected by a severe security bug people start to look for more. I wonder what it'd take to have people looking at the projects that aren't in the spotlight.
I was brainstorming if we could have something like a "free software audit action day". A regular call where an important but neglected project is chosen and the security community is asked to have a look at it. This is just a vague idea for now, if you like it please leave a comment.
That's it. I refrain from having discussions whether bugs like Heartbleed or Shellshock disprove the "many eyes"-principle that free software advocates like to cite, because I think these discussions are a pointless waste of time. I'd like to discuss how to improve things. Let's start.
Here's the promised list of Gentoo packages in the standard installation:
bzip2
gzip
tar
unzip
xz-utils
nano
ca-certificates
mime-types
pax-utils
bash
build-docbook-catalog
docbook-xml-dtd
docbook-xsl-stylesheets
openjade
opensp
po4a
sgml-common
perl
python
elfutils
expat
glib
gmp
libffi
libgcrypt
libgpg-error
libpcre
libpipeline
libxml2
libxslt
mpc
mpfr
openssl
popt
Locale-gettext
SGMLSpm
TermReadKey
Text-CharWidth
Text-WrapI18N
XML-Parser
gperf
gtk-doc-am
intltool
pkgconfig
iputils
netifrc
openssh
rsync
wget
acl
attr
baselayout
busybox
coreutils
debianutils
diffutils
file
findutils
gawk
grep
groff
help2man
hwids
kbd
kmod
less
man-db
man-pages
man-pages-posix
net-tools
sed
shadow
sysvinit
tcp-wrappers
texinfo
util-linux
which
pambase
autoconf
automake
binutils
bison
flex
gcc
gettext
gnuconfig
libtool
m4
make
patch
e2fsprogs
udev
linux-headers
cracklib
db
e2fsprogs-libs
gdbm
glibc
libcap
ncurses
pam
readline
timezone-data
zlib
procps
psmisc
shared-mime-info
Saturday, July 12. 2014
LibreSSL on Gentoo
Yesterday and today I played around with it on Gentoo Linux. I was able to replace my system's OpenSSL completely with LibreSSL and with few exceptions was able to successfully rebuild all packages using OpenSSL.
After getting this running on my own system I installed it on a test server. The Webpage tlsfun.de runs on that server. The functionality changes are limited, the only thing visible from the outside is the support for the experimental, not yet standardized ChaCha20-Poly1305 cipher suites, which is a nice thing.
A warning ahead: This is experimental, in no way stable or supported and if you try any of this you do it at your own risk. Please report any bugs you have with my overlay to me or leave a comment and don't disturb anyone else (from Gentoo or LibreSSL) with it. If you want to try it, you can get a portage overlay in a subversion repository. You can check it out with this command:
svn co https://svn.hboeck.de/libressl-overlay/
git clone https://github.com/gentoo/libressl.git
This is what I had to do to get things running:
LibreSSL itself
First of all the Gentoo tree contains a lot of packages that directly depend on openssl, so I couldn't just replace that. The correct solution to handle such issues would be to create a virtual package and change all packages depending directly on openssl to depend on the virtual. This is already discussed in the appropriate Gentoo bug, but this would mean patching hundreds of packages so I skipped it and worked around it by leaving a fake openssl package in place that itself depends on libressl.
LibreSSL deprecates some APIs from OpenSSL. The first thing that stopped me was that various programs use the functions RAND_egd() and RAND_egd_bytes(). I didn't know until yesterday what egd is. It stands for Entropy Gathering Daemon and is a tool written in perl meant to replace the functionality of /dev/(u)random on non-Linux-systems. The LibreSSL-developers consider it insecure and after having read what it is I have to agree. However, the removal of those functions causes many packages not to build, upon them wget, python and ruby. My workaround was to add two dummy functions that just return -1, which is the error code if the Entropy Gathering Daemon is not available. So the API still behaves like expected. I also posted the patch upstream, but the LibreSSL devs don't like it. So on the long term it's probably better to fix applications to stop trying to use egd, but for now these dummy functions make it easier for me to build my system.
The second issue popping up was that the libcrypto.so from libressl contains an undefined main() function symbol which causes linking problems with a couple of applications (subversion, xorg-server, hexchat). According to upstream this undefined symbol is intended and most likely these are bugs in the applications having linking problems. However, for now it was easier for me to patch the symbol out instead of fixing all the apps. Like the egd issue on the long term fixing the applications is better.
The third issue was that LibreSSL doesn't ship pkg-config (.pc) files, some apps use them to get the correct compilation flags. I grabbed the ones from openssl and adjusted them accordingly.
OpenSSH
This was the most interesting issue from all of them.
To understand this you have to understand how both LibreSSL and OpenSSH are developed. They are both from OpenBSD and they use some functions that are only available there. To allow them to be built on other systems they release portable versions which ship the missing OpenBSD-only-functions. One of them is arc4random().
Both LibreSSL and OpenSSH ship their compatibility version of arc4random(). The one from OpenSSH calls RAND_bytes(), which is a function from OpenSSL. The RAND_bytes() function from LibreSSL however calls arc4random(). Due to the linking order OpenSSH uses its own arc4random(). So what we have here is a nice recursion. arc4random() and RAND_bytes() try to call each other. The result is a segfault.
I fixed it by using the LibreSSL arc4random.c file for OpenSSH. I had to copy another function called arc4random_stir() from OpenSSH's arc4random.c and the header file thread_private.h. Surprisingly, this seems to work flawlessly.
Net-SSLeay
This package contains the perl bindings for openssl. The problem is a check for the openssl version string that expected the name OpenSSL and a version number with three numbers and a letter (like 1.0.1h). LibreSSL prints the version 2.0. I just hardcoded the OpenSSL version numer, which is not a real fix, but it works for now.
SpamAssassin
SpamAssassin's code for spamc requires SSLv2 functions to be available. SSLv2 is heavily insecure and should not be used at all and therefore the LibreSSL devs have removed all SSLv2 function calls. Luckily, Debian had a patch to remove SSLv2 that I could use.
libesmtp / gwenhywfar
Some DES-related functions (DES is the old Data Encryption Standard) in OpenSSL are available in two forms: With uppercase DES_ and with lowercase des_. I can only guess that the des_ variants are for backwards compatibliity with some very old versions of OpenSSL. According to the docs the DES_ variants should be used. LibreSSL has removed the des_ variants.
For gwenhywfar I wrote a small patch and sent it upstream. For libesmtp all the code was in ntlm. After reading that ntlm is an ancient, proprietary Microsoft authentication protocol I decided that I don't need that anyway so I just added --disable-ntlm to the ebuild.
Dovecot
In Dovecot two issues popped up. LibreSSL removed the SSL Compression functionality (which is good, because since the CRIME attack we know it's not secure). Dovecot's configure script checks for it, but the check doesn't work. It checks for a function that LibreSSL keeps as a stub. For now I just disabled the check in the configure script. The solution is probably to remove all remaining stub functions. The configure script could probably also be changed to work in any case.
The second issue was that the Dovecot code has some #ifdef clauses that check the openssl version number for the ECDH auto functionality that has been added in OpenSSL 1.0.2 beta versions. As the LibreSSL version number 2.0 is higher than 1.0.2 it thinks it is newer and tries to enable it, but the code is not present in LibreSSL. I changed the #ifdefs to check for the actual functionality by checking a constant defined by the ECDH auto code.
Apache httpd
The Apache http compilation complained about a missing ENGINE_CTRL_CHIL_SET_FORKCHECK. I have no idea what it does, but I found a patch to fix the issue, so I didn't investigate it further.
Further reading:
Someone else tried to get things running on Sabotage Linux.
Update: I've abandoned my own libressl overlay, a LibreSSL overlay by various Gentoo developers is now maintained at GitHub.