Monday, October 6. 2014
How to stop Bleeding Hearts and Shocking Shells
 The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.
The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.Heartbleed hit the news in April this year. A bug in OpenSSL that allowed to extract privat keys of encrypted connections. When a bug in Bash called Shellshock hit the news I was first hesistant to call it bigger than Heartbleed. But now I am pretty sure it is. While Heartbleed was big there were some things that alleviated the impact. It took some days till people found out how to practically extract private keys - and it still wasn't fast. And the most likely attack scenario - stealing a private key and pulling off a Man-in-the-Middle-attack - seemed something that'd still pose some difficulties to an attacker. It seemed that people who update their systems quickly (like me) weren't in any real danger.
Shellshock was different. It's astonishingly simple to use and real attacks started hours after it became public. If circumstances had been unfortunate there would've been a very real chance that my own servers could've been hit by it. I usually feel the IT stuff under my responsibility is pretty safe, so things like this scare me.
What OpenSSL and Bash have in common
Shortly after Heartbleed something became very obvious: The OpenSSL project wasn't in good shape. The software that pretty much everyone in the Internet uses to do encryption was run by a small number of underpaid people. People trying to contribute and submit patches were often ignored (I know that, I tried it). The truth about Bash looks even grimmer: It's a project mostly run by a single volunteer. And yet almost every large Internet company out there uses it. Apple installs it on every laptop. OpenSSL and Bash are crucial pieces of software and run on the majority of the servers that run the Internet. Yet they are very small projects backed by few people. Besides they are both quite old, you'll find tons of legacy code in them written more than a decade ago.
People like to rant about the code quality of software like OpenSSL and Bash. However I am not that concerned about these two projects. This is the upside of events like these: OpenSSL is probably much securer than it ever was and after the dust settles Bash will be a better piece of software. If you want to ask yourself where the next Heartbleed/Shellshock-alike bug will happen, ask this: What projects are there that are installed on almost every Linux system out there? And how many of them have a healthy community and received a good security audit lately?
Software installed on almost any Linux system
Let me propose a little experiment: Take your favorite Linux distribution, make a minimal installation without anything and look what's installed. These are the software projects you should worry about. To make things easier I did this for you. I took my own system of choice, Gentoo Linux, but the results wouldn't be very different on other distributions. The results are at at the bottom of this text. (I removed everything Gentoo-specific.) I admit this is oversimplifying things. Some of these provide more attack surface than others, we should probably worry more about the ones that are directly involved in providing network services.
After Heartbleed some people already asked questions like these. How could it happen that a project so essential to IT security is so underfunded? Some large companies acted and the result is the Core Infrastructure Initiative by the Linux Foundation, which already helped improving OpenSSL development. This is a great start and an example for an initiative of which we should have more. We should ask the large IT companies who are not part of that initiative what they are doing to improve overall Internet security.
Just to put this into perspective: A thorough security audit of a project like Bash would probably require a five figure number of dollars. For a small, volunteer driven project this is huge. For a company like Apple - the one that installed Bash on all their laptops - it's nearly nothing.
There's another recent development I find noteworthy. Google started Project Zero where they hired some of the brightest minds in IT security and gave them a single job: Search for security bugs. Not in Google's own software. In every piece of software out there. This is not merely an altruistic project. It makes sense for Google. They want the web to be a safer place - because the web is where they earn their money. I like that approach a lot and I have only one question to ask about it: Why doesn't every large IT company have a Project Zero?
Sparking interest
There's another aspect I want to talk about. After Heartbleed people started having a closer look at OpenSSL and found a number of small and one other quite severe issue. After Bash people instantly found more issues in the function parser and we now have six CVEs for Shellshock and friends. When a piece of software is affected by a severe security bug people start to look for more. I wonder what it'd take to have people looking at the projects that aren't in the spotlight.
I was brainstorming if we could have something like a "free software audit action day". A regular call where an important but neglected project is chosen and the security community is asked to have a look at it. This is just a vague idea for now, if you like it please leave a comment.
That's it. I refrain from having discussions whether bugs like Heartbleed or Shellshock disprove the "many eyes"-principle that free software advocates like to cite, because I think these discussions are a pointless waste of time. I'd like to discuss how to improve things. Let's start.
Here's the promised list of Gentoo packages in the standard installation:
bzip2
gzip
tar
unzip
xz-utils
nano
ca-certificates
mime-types
pax-utils
bash
build-docbook-catalog
docbook-xml-dtd
docbook-xsl-stylesheets
openjade
opensp
po4a
sgml-common
perl
python
elfutils
expat
glib
gmp
libffi
libgcrypt
libgpg-error
libpcre
libpipeline
libxml2
libxslt
mpc
mpfr
openssl
popt
Locale-gettext
SGMLSpm
TermReadKey
Text-CharWidth
Text-WrapI18N
XML-Parser
gperf
gtk-doc-am
intltool
pkgconfig
iputils
netifrc
openssh
rsync
wget
acl
attr
baselayout
busybox
coreutils
debianutils
diffutils
file
findutils
gawk
grep
groff
help2man
hwids
kbd
kmod
less
man-db
man-pages
man-pages-posix
net-tools
sed
shadow
sysvinit
tcp-wrappers
texinfo
util-linux
which
pambase
autoconf
automake
binutils
bison
flex
gcc
gettext
gnuconfig
libtool
m4
make
patch
e2fsprogs
udev
linux-headers
cracklib
db
e2fsprogs-libs
gdbm
glibc
libcap
ncurses
pam
readline
timezone-data
zlib
procps
psmisc
shared-mime-info
Friday, October 3. 2014
New laptop Lenovo Thinkpad X1 Carbon 20A7
 While I got along well with my Thinkpad T61 laptop, for quite some time I had the plan to get a new one soon. It wasn't an easy decision and I looked in detail at the models available in recent months. I finally decided to buy one of Lenovo's Thinkpad X1 Carbon laptops in its 2014 edition. The X1 Carbon was introduced in 2012, however a completely new variant which is very different from the first one was released early 2014. To distinguish it from other models it is the 20A7 model.
While I got along well with my Thinkpad T61 laptop, for quite some time I had the plan to get a new one soon. It wasn't an easy decision and I looked in detail at the models available in recent months. I finally decided to buy one of Lenovo's Thinkpad X1 Carbon laptops in its 2014 edition. The X1 Carbon was introduced in 2012, however a completely new variant which is very different from the first one was released early 2014. To distinguish it from other models it is the 20A7 model.Judging from the first days of use I think I made the right decision. I hadn't seen the device before I bought it because it seems rarely shops keep this device in stock. I assume this is due to the relatively high price.
I was a bit worried because Lenovo made some unusual decisions for the keyboard, however having used it for a few days I don't feel that it has any severe downsides. The most unusual thing about it is that it doesn't have normal F1-F12 keys, instead it has what Lenovo calls an adaptive keyboard: A touch sensitive line which can display different kinds of keys. The idea is that different applications can have their own set of special keys there. However, just letting them display the normal F-keys works well and not having "real" keys there doesn't feel like a big disadvantage. Beside that Lenovo removed the Caps lock and placed Pos1/End there, which is a bit unusual but also nothing I worried about. I also hadn't seen any pictures of the German keyboard before I bought the device. The ^/°-key is not where it's used to be (small downside), but the </>/| key is where it belongs(big plus, many laptop vendors get that wrong).
Good things:
* Lightweight, Ultrabook, no unnecessary stuff like CD/DVD drive
* High resolution (2560x1440)
* Hardware is up-to-date (Haswell chipset)
Downsides:
* Due to ultrabook / integrated design easy changing battery, ram or HD
* No SD card reader
* Have some trouble getting used to the touchpad (however there are lots of possibilities to configure it, I assume by playing with it that'll get better)
It used to be the case that people wrote docs how to get all the hardware in a laptop running on Linux which I did my previous laptops. These days this usually boils down to "run a recent Linux distribution with the latest kernels and xorg packages and most things will be fine". However I thought having a central place where I collect relevant information would be nice so I created one again. As usual I'm running Gentoo Linux.
For people who plan to run Linux without a dual boot it may be worth mentioning that there seem to be troublesome errors in earlier versions of the BIOS and the SSD firmware. You may want to update them before removing Windows. On my device they were already up-to-date.
Monday, September 29. 2014
Responsibility in running Internet infrastructure
Monday, September 22. 2014
Mehr als 15 Cent
Friday, September 19. 2014
Some experience with Content Security Policy
 I recently started playing around with Content Security Policy (CSP). CSP is a very neat feature and a good example how to get IT security right.
I recently started playing around with Content Security Policy (CSP). CSP is a very neat feature and a good example how to get IT security right.The main reason CSP exists are cross site scripting vulnerabilities (XSS). Every time a malicious attacker is able to somehow inject JavaScript or other executable code into your webpage this is called an XSS. XSS vulnerabilities are amongst the most common vulnerabilities in web applications.
CSP fixes XSS for good
The approach to fix XSS in the past was to educate web developers that they need to filter or properly escape their input. The problem with this approach is that it doesn't work. Even large websites like Amazon or Ebay don't get this right. The problem, simply stated, is that there are just too many places in a complex web application to create XSS vulnerabilities. Fixing them one at a time doesn't scale.
CSP tries to fix this in a much more generic way: How can we prevent XSS from happening at all? The way to do this is that the web server is sending a header which defines where JavaScript and other content (images, objects etc.) is allowed to come from. If used correctly CSP can prevent XSS completely. The problem with CSP is that it's hard to add to an already existing project, because if you want CSP to be really secure you have to forbid inline JavaScript. That often requires large re-engineering of existing code. Preferrably CSP should be part of the development process right from the beginning. If you start a web project keep that in mind and educate your developers to use restrictive CSP before they write any code. Starting a new web page without CSP these days is irresponsible.
To play around with it I added a CSP header to my personal webpage. This was a simple target, because it's a very simple webpage. I'm essentially sure that my webpage is XSS free because it doesn't use any untrusted input, I mainly wanted to have an easy target to do some testing. I also tried to add CSP to this blog, but this turned out to be much more complicated.
For my personal webpage this is what I did (PHP code):
header("Content-Security-Policy:default-src 'none';img-src 'self';style-src 'self';report-uri /c/");
The default policy is to accept nothing. The only things I use on my webpage are images and stylesheets and they all are located on the same webspace as the webpage itself, so I allow these two things.
This is an extremely simple CSP policy. To give you an idea how a more realistic policy looks like this is the one from Github:
Content-Security-Policy: default-src *; script-src assets-cdn.github.com www.google-analytics.com collector-cdn.github.com; object-src assets-cdn.github.com; style-src 'self' 'unsafe-inline' 'unsafe-eval' assets-cdn.github.com; img-src 'self' data: assets-cdn.github.com identicons.github.com www.google-analytics.com collector.githubapp.com *.githubusercontent.com *.gravatar.com *.wp.com; media-src 'none'; frame-src 'self' render.githubusercontent.com gist.github.com www.youtube.com player.vimeo.com checkout.paypal.com; font-src assets-cdn.github.com; connect-src 'self' ghconduit.com:25035 live.github.com uploads.github.com s3.amazonaws.com
Reporting feature
You may have noticed in my CSP header line that there's a "report-uri" command at the end. The idea is that whenever a browser blocks something by CSP it is able to report this to the webpage owner. Why should we do this? Because we still want to fix XSS issues (there are browsers with little or no CSP support (I'm looking at you Internet Explorer) and we want to know if our policy breaks anything that is supposed to work. The way this works is that a json file with details is sent via a POST request to the URL given.
While this sounds really neat in theory, in practise I found it to be quite disappointing. As I said above I'm almost certain my webpage has no XSS issues, so I shouldn't get any reports at all. However I get lots of them and they are all false positives. The problem are browser extensions that execute things inside a webpage's context. Sometimes you can spot them (when source-file starts with "chrome-extension" or "safari-extension"), sometimes you can't (source-file will only say "data"). Sometimes this is triggered not by single extensions but by combinations of different ones (I found out that a combination of HTTPS everywhere and Adblock for Chrome triggered a CSP warning). I'm not sure how to handle this and if this is something that should be reported as a bug either to the browser vendors or the extension developers.
Conclusion
If you start a web project use CSP. If you have a web page that needs extra security use CSP (my bank doesn't - does yours?). CSP reporting is neat, but it's usefulness is limited due to too many false positives.
Then there's the bigger picture of IT security in general. Fixing single security bugs doesn't work. Why? XSS is as old as JavaScript (1995) and it's still a huge problem. An example for a simliar technology are prepared statements for SQL. If you use them you won't have SQL injections. SQL injections are the second most prevalent web security problem after XSS. By using CSP and prepared statements you eliminate the two biggest issues in web security. Sounds like a good idea to me.
Buffer overflows where first documented 1972 and they still are the source of many security issues. Fixing them for good is trickier but it is also possible.
Tuesday, August 5. 2014
Las Vegas

My hotel looks like a Disneyland castle - just much larger.
Las Vegas is probably a place I would've never visited on its own. I consider myself a rationalist person and therefore I see gambling mostly as an illogical pursuit. In the end your chances of winning are minimal because otherwise the business wouldn't work. I hadn't imagined how huge the casino business in Las Vegas is. Large parts of the city are just one large casino after another - and it doesn't stop there, because a couple of cities around Vegas literally are made of casinos.
Beside seeing some of the usual tourist attractions (Hoover Dam, Lake Mead), I spend the last couple of days also finding out that there are some interesting solar energy projects nearby. Also a large Star Trek convention> was happening the past days where I attended on the last day.

A Nintendo test cardrige at A Gamer's Paradise
Pictures from Las Vegas
Pictures from A Gamer's Paradise
Pictures from Pinball Hall of Fame
Saturday, July 12. 2014
LibreSSL on Gentoo
Yesterday and today I played around with it on Gentoo Linux. I was able to replace my system's OpenSSL completely with LibreSSL and with few exceptions was able to successfully rebuild all packages using OpenSSL.
After getting this running on my own system I installed it on a test server. The Webpage tlsfun.de runs on that server. The functionality changes are limited, the only thing visible from the outside is the support for the experimental, not yet standardized ChaCha20-Poly1305 cipher suites, which is a nice thing.
A warning ahead: This is experimental, in no way stable or supported and if you try any of this you do it at your own risk. Please report any bugs you have with my overlay to me or leave a comment and don't disturb anyone else (from Gentoo or LibreSSL) with it. If you want to try it, you can get a portage overlay in a subversion repository. You can check it out with this command:
svn co https://svn.hboeck.de/libressl-overlay/
git clone https://github.com/gentoo/libressl.git
This is what I had to do to get things running:
LibreSSL itself
First of all the Gentoo tree contains a lot of packages that directly depend on openssl, so I couldn't just replace that. The correct solution to handle such issues would be to create a virtual package and change all packages depending directly on openssl to depend on the virtual. This is already discussed in the appropriate Gentoo bug, but this would mean patching hundreds of packages so I skipped it and worked around it by leaving a fake openssl package in place that itself depends on libressl.
LibreSSL deprecates some APIs from OpenSSL. The first thing that stopped me was that various programs use the functions RAND_egd() and RAND_egd_bytes(). I didn't know until yesterday what egd is. It stands for Entropy Gathering Daemon and is a tool written in perl meant to replace the functionality of /dev/(u)random on non-Linux-systems. The LibreSSL-developers consider it insecure and after having read what it is I have to agree. However, the removal of those functions causes many packages not to build, upon them wget, python and ruby. My workaround was to add two dummy functions that just return -1, which is the error code if the Entropy Gathering Daemon is not available. So the API still behaves like expected. I also posted the patch upstream, but the LibreSSL devs don't like it. So on the long term it's probably better to fix applications to stop trying to use egd, but for now these dummy functions make it easier for me to build my system.
The second issue popping up was that the libcrypto.so from libressl contains an undefined main() function symbol which causes linking problems with a couple of applications (subversion, xorg-server, hexchat). According to upstream this undefined symbol is intended and most likely these are bugs in the applications having linking problems. However, for now it was easier for me to patch the symbol out instead of fixing all the apps. Like the egd issue on the long term fixing the applications is better.
The third issue was that LibreSSL doesn't ship pkg-config (.pc) files, some apps use them to get the correct compilation flags. I grabbed the ones from openssl and adjusted them accordingly.
OpenSSH
This was the most interesting issue from all of them.
To understand this you have to understand how both LibreSSL and OpenSSH are developed. They are both from OpenBSD and they use some functions that are only available there. To allow them to be built on other systems they release portable versions which ship the missing OpenBSD-only-functions. One of them is arc4random().
Both LibreSSL and OpenSSH ship their compatibility version of arc4random(). The one from OpenSSH calls RAND_bytes(), which is a function from OpenSSL. The RAND_bytes() function from LibreSSL however calls arc4random(). Due to the linking order OpenSSH uses its own arc4random(). So what we have here is a nice recursion. arc4random() and RAND_bytes() try to call each other. The result is a segfault.
I fixed it by using the LibreSSL arc4random.c file for OpenSSH. I had to copy another function called arc4random_stir() from OpenSSH's arc4random.c and the header file thread_private.h. Surprisingly, this seems to work flawlessly.
Net-SSLeay
This package contains the perl bindings for openssl. The problem is a check for the openssl version string that expected the name OpenSSL and a version number with three numbers and a letter (like 1.0.1h). LibreSSL prints the version 2.0. I just hardcoded the OpenSSL version numer, which is not a real fix, but it works for now.
SpamAssassin
SpamAssassin's code for spamc requires SSLv2 functions to be available. SSLv2 is heavily insecure and should not be used at all and therefore the LibreSSL devs have removed all SSLv2 function calls. Luckily, Debian had a patch to remove SSLv2 that I could use.
libesmtp / gwenhywfar
Some DES-related functions (DES is the old Data Encryption Standard) in OpenSSL are available in two forms: With uppercase DES_ and with lowercase des_. I can only guess that the des_ variants are for backwards compatibliity with some very old versions of OpenSSL. According to the docs the DES_ variants should be used. LibreSSL has removed the des_ variants.
For gwenhywfar I wrote a small patch and sent it upstream. For libesmtp all the code was in ntlm. After reading that ntlm is an ancient, proprietary Microsoft authentication protocol I decided that I don't need that anyway so I just added --disable-ntlm to the ebuild.
Dovecot
In Dovecot two issues popped up. LibreSSL removed the SSL Compression functionality (which is good, because since the CRIME attack we know it's not secure). Dovecot's configure script checks for it, but the check doesn't work. It checks for a function that LibreSSL keeps as a stub. For now I just disabled the check in the configure script. The solution is probably to remove all remaining stub functions. The configure script could probably also be changed to work in any case.
The second issue was that the Dovecot code has some #ifdef clauses that check the openssl version number for the ECDH auto functionality that has been added in OpenSSL 1.0.2 beta versions. As the LibreSSL version number 2.0 is higher than 1.0.2 it thinks it is newer and tries to enable it, but the code is not present in LibreSSL. I changed the #ifdefs to check for the actual functionality by checking a constant defined by the ECDH auto code.
Apache httpd
The Apache http compilation complained about a missing ENGINE_CTRL_CHIL_SET_FORKCHECK. I have no idea what it does, but I found a patch to fix the issue, so I didn't investigate it further.
Further reading:
Someone else tried to get things running on Sabotage Linux.
Update: I've abandoned my own libressl overlay, a LibreSSL overlay by various Gentoo developers is now maintained at GitHub.
Wednesday, June 18. 2014
Should science journalists read the studies they write about?
Today I had a little twitter conversation which made me think about the responsibilities a science journalist has. It all started with a quote from Ivan Oransky (who is the editor of Retraction Watch) who said reporting on a study without reading it is 'journalist malpractice'. The source of this is another person who probably just heard him saying that, so I'm not sure what his exact words were.
Admittedly my first thought was: "He is right, too many journalists report about things they don't understand." My second thought was: "If he is right then I am probably guilty of 'journalist malpractice'." So I gave it a second thought and I probably won't agree with the statement any more.
I had a quick look at articles I wrote in the past and I have identified the last ten ones that more or less were coverages of a scientific piece of work. I have marked the ones I actually read with a [Y] and the ones I didn't read with a [N]. I've linked the appropriate scientific works and my articles (all in German). I must admit that I defined "read" widely, meaning that I haven't neccesarrily read the whole study/article in detail, I sometimes have just tried to parse the important parts for me.
Now the first thing that comes to mind is that I seem to have become lazier recently in reading studies. I hope this isn't the case and I hoestly think this is mostly coincidence. Now let's get into some details: The first example (the Turing Test) is interesting because it seems there is no scientific publication at all, just a press release. This probably tells you something about the quality of that "research", but while I read the press release I haven't even bothered to check if there is a scientific publication I could read.
The second example becomes interesting. I understand enough to know what a "quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic" actually is and I think I also understand what it means, but there's just no way I could understand the paper itself. This is complex mathematics. I seriously doubt that any journalist who covered this work actually read it. If there is I'd like to meet that person. I'm also very sure that the people who wrote the press release overselling this research have neither read this paper nor understood its implications.
I think this example gets to the point why I would disagree with the very general statement that a journalist should've read every scientific piece he writes about: It's sometimes so specialized that it's basically impossible. And I don't think this is an out of the line example. Just think about the Higgs Boson: Certainly this is something we want journalists to write about. But I'm pretty sure there are very few - if any - journalists who are able to read the scientific publications that are the basis of this discovery.
Some quick notes on the others: Number 4 was part of a 200-page-thesis and the press release was already pretty detailed and technically, I think it was legitimate to not read the original source in that case. Number 5 is somewhat similar to 2, because it is about an algorithm that includes complex math. Number 8 is not really a scientific paper, it is merely a news item on the Nature webpage. In the above list, the only case where I think maybe I should've read the scientific paper and I didn't is the Cochrane-Review on Tamiflu.
Conclusion: Don't get me wrong. I certainly welcome the idea that science journalists should have a look into the original scientific papers they write about more often - and this doesn't exclude myself. However, as shown above I doubt that this works in all cases.
Admittedly my first thought was: "He is right, too many journalists report about things they don't understand." My second thought was: "If he is right then I am probably guilty of 'journalist malpractice'." So I gave it a second thought and I probably won't agree with the statement any more.
I had a quick look at articles I wrote in the past and I have identified the last ten ones that more or less were coverages of a scientific piece of work. I have marked the ones I actually read with a [Y] and the ones I didn't read with a [N]. I've linked the appropriate scientific works and my articles (all in German). I must admit that I defined "read" widely, meaning that I haven't neccesarrily read the whole study/article in detail, I sometimes have just tried to parse the important parts for me.
- [X] Supposedly successful Turing Test taz, 2014-06-13
- [N]A quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic, Golem.de, 2014-05-17
- [N] Neuraminidase inhibitors for preventing and treating influenza in healthy adults and children (Cochrane-Review on Tamiflu), Neues Deutschland, 2014-04-26)
- [N] 20 Years of SSL/TLS Research: An Analysis of the Internet's Security Foundation, Golem.de, 2014-04-17
- [N] DRAFT FIPS 202 - SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions, Golem, 2014-04-05
- [Y] Using Frankencerts for Automated Adversarial Testing of Certificate Validation in SSL/TLS Implementations, Golem.de, 2014-04-04
- [Y] On the Practical Exploitability of Dual EC in TLS Implementations, Golem.de, 2014-04-01
- [Y] Publishers withdraw more than 120 gibberish papers, Golem.de, 2014-02-27
- [Y] Completeness of Reporting of Patient-Relevant Clinical Trial Outcomes: Comparison of Unpublished Clinical Study Reports with Publicly Available Data, taz, 2013-10-18
- [Y] Factoring RSA keys from certified smart cards: Coppersmith in the wild, Golem.de, 2013-09-17
Now the first thing that comes to mind is that I seem to have become lazier recently in reading studies. I hope this isn't the case and I hoestly think this is mostly coincidence. Now let's get into some details: The first example (the Turing Test) is interesting because it seems there is no scientific publication at all, just a press release. This probably tells you something about the quality of that "research", but while I read the press release I haven't even bothered to check if there is a scientific publication I could read.
The second example becomes interesting. I understand enough to know what a "quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic" actually is and I think I also understand what it means, but there's just no way I could understand the paper itself. This is complex mathematics. I seriously doubt that any journalist who covered this work actually read it. If there is I'd like to meet that person. I'm also very sure that the people who wrote the press release overselling this research have neither read this paper nor understood its implications.
I think this example gets to the point why I would disagree with the very general statement that a journalist should've read every scientific piece he writes about: It's sometimes so specialized that it's basically impossible. And I don't think this is an out of the line example. Just think about the Higgs Boson: Certainly this is something we want journalists to write about. But I'm pretty sure there are very few - if any - journalists who are able to read the scientific publications that are the basis of this discovery.
Some quick notes on the others: Number 4 was part of a 200-page-thesis and the press release was already pretty detailed and technically, I think it was legitimate to not read the original source in that case. Number 5 is somewhat similar to 2, because it is about an algorithm that includes complex math. Number 8 is not really a scientific paper, it is merely a news item on the Nature webpage. In the above list, the only case where I think maybe I should've read the scientific paper and I didn't is the Cochrane-Review on Tamiflu.
Conclusion: Don't get me wrong. I certainly welcome the idea that science journalists should have a look into the original scientific papers they write about more often - and this doesn't exclude myself. However, as shown above I doubt that this works in all cases.
Sunday, June 15. 2014
Slides from cryptography workshop for web developers
Friday, June 6. 2014
Enabling encryption by default and using HTTPS only
 I recently switched my personal web page and my blog to deliver content exclusively encrypted via HTTPS. I want to take this opportunity to give some facts about enabling TLS encryption by default and problems you may face.
I recently switched my personal web page and my blog to deliver content exclusively encrypted via HTTPS. I want to take this opportunity to give some facts about enabling TLS encryption by default and problems you may face.First of all the non-problems: Enabling HTTPS by default is almost never a significant performance problem. If people tell me that they can not possibly enable HTTPS due to performance reasons the first thing I ask is if they believe this or if they have real benchmark data showing this. If you don't believe me on that, I can quote Adam Langley from Google here: "In January this year (2010), Gmail switched to using HTTPS for everything by default. Previously it had been introduced as an option, but now all of our users use HTTPS to secure their email between their browsers and Google, all the time. In order to do this we had to deploy no additional machines and no special hardware. On our production frontend machines, SSL/TLS accounts for less than 1% of the CPU load, less than 10KB of memory per connection and less than 2% of network overhead."
Enabling HTTPS may cause a number of compatibility issues you may not instantly think about. First of all, we know that IPs in the IPv4 space are limited and expensive these days, so many people probably can't afford having a distinct IP for their web page. The solution to that is a TLS extension called SNI (Server Name Indication) which allows to have different certificates for different domain names on the same IP. It works in all major browsers and has been working for quite some time. The only major browser you'll face these days that doesn't support SNI is the Android 2.x browser.
There are some subtle issues with SNI. One is that browsers have fallback modes if they cannot connect via TLS and that may lead to a connection downgrade to SSLv3. And that ancient protocol doesn't support extensions and thus no SNI. So you may have irregular certificate errors if you are on a bad connection. A solution to that on the server side is to just disable SSLv3. It will make SNI much more reliable.
I don't really have a clear picture how many browsers will fail with SNI. There are probably a number of embedded devices out there like smart TVs with browsers or things alike that have problems. If you have any experiences feel free to post them in the comments.
The first issue I only noticed after I switched to HTTPS: I had an application called RSS Graffiti set up to automatically post all articles I write to a facebook fan page. After changing to HTTPS only it silently stopped working. Re-adding my feed didn't work. I now found a similar service called dlvr.it that I now use to post my RSS feed to facebook. I can only assume that this is a glimpse of a much bigger problem: There are probably tons of applications and online services out there not prepared for an encrypted Internet. If we want more people to deploy encryption by default we need to find these issues, document them and hopefully put enough pressure on their developers to fix them.
Another yet unfixed issue is the Yandex Bot. Yandex is a search engine and although you may never have heard of it it's probably one of the few companies in this area that can claim to be a serious competitor to Google. The reason you may not know it is that it's mostly operating in Russian language. Depending on who your page visitors are this may matter more or less.
The Yandex Bot speaks SSL but according to the Qualys SSL test it only supports the ancient SSLv3. So you have a choice between three possibilities: Don't enable HTTPS by default, enable HTTPS with a shitty configuration supporting ancient technology that will cause trouble for SNI or enable HTTPS with a sane configuration and get no traffic from the leading Russian search engine. None of them sounds very good to me.
Another issue is third party content. For security reasons today's browsers block all active HTTP content (CSS, JavaScript etc.) on HTTPS webpages. This isn't much of a problem for me, but it's a problem for webpages that rely on advertising because from what I hear most advertisement providers don't support HTTPS yet (Google being a laudable exception here). This is the main reason you won't see many news webpages enforcing HTTPS. However, I still have passive third party HTTP content on my blog. That's why you'll probably see a yellow warning sign in front of the URL in some browsers.
Tuesday, April 29. 2014
Incomplete Certificate Chains and Transvalid Certificates
 A number of people seem to be confused how to correctly install certificate chains for TLS servers. This happens quite often on HTTPS sites and to avoid having to explain things again and again I thought I'd write up something so I can refer to it. A few days ago flattr.com had a missing certificate chain (fixed now after I reported it) and various pages from the Chaos Computer Club have no certificate chain (not the main page, but several subdomains like events.ccc.de and frab.cccv.de). I've tried countless times to tell someone, but the problem persists. Maybe someone in charge will read this and fix it.
A number of people seem to be confused how to correctly install certificate chains for TLS servers. This happens quite often on HTTPS sites and to avoid having to explain things again and again I thought I'd write up something so I can refer to it. A few days ago flattr.com had a missing certificate chain (fixed now after I reported it) and various pages from the Chaos Computer Club have no certificate chain (not the main page, but several subdomains like events.ccc.de and frab.cccv.de). I've tried countless times to tell someone, but the problem persists. Maybe someone in charge will read this and fix it.Web browsers ship a list of certificate authorities (CAs) that are allowed to issue certificates for HTTPS websites. The whole system is inherently problematic, but right now that's not the point I want to talk about. Most of the time, people don't get their certificate from one of the root CAs but instead from a subordinate CA. Every CA is allowed to have unlimited numbers of sub CAs.
The correct way of delivering a certificate issued by a sub CA is to deliver both the host certificate and the certificate of the sub CA. This is neccesarry so the browser can check the complete chain from the root to the host. For example if you buy your certificate from RapidSSL then the RapidSSL cert is not in the browser. However, the RapidSSL certificate is signed by GeoTrust and that is in your browser. So if your HTTPS website delivers both its own certificate by RapidSSL and the RapidSSL certificate, the browser can validate the whole chain.
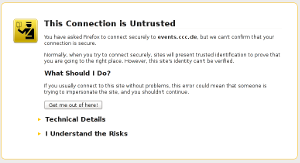
However, and here comes the tricky part: If you forget to deliver the chain certificate you often won't notice. The reason is that browsers cache chain certificates. In our example above if a user first visits a website with a certificate from RapidSSL and the correct chain the browser will already know the RapidSSL certificate. If the user then surfs to a page where the chain is missing the browser will still consider the certificate as valid. Such certificates with missing chain have been called transvalid, I think the term was first used by the EFF for their SSL Observatory.
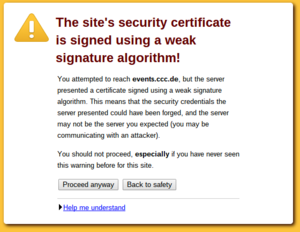
Chromium with bogus error message on a transvalid certificate
So how can you check if you have a transvalid certificate? One way is to use a fresh browser installation without anything cached. If you then surf to a page with a transvalid certificate, you'll get an error message (however, as we've just seen, not neccessarily a meaningful one). An easier way is to use the SSL Test from Qualys. It has a line "Chain issues" and if it shows "None" you're fine. If it shows "Incomplete" then your certificate is most likely transvalid. If it shows anything else you have other things to look after (a common issues is that people unneccesarily send the root certificate, which doesn't cause issues but may make things slower). The Qualys test test will tell you all kinds of other things about your TLS configuration. If it tells you something is insecure you should probably look after that, too.
Thursday, April 24. 2014
Easterhegg talk on TLS
 Last weekend I was at the Easterhegg in Stuttgart, an event organized by the Chaos Computer Club. I had a talk with the title "How broken is TLS?"
Last weekend I was at the Easterhegg in Stuttgart, an event organized by the Chaos Computer Club. I had a talk with the title "How broken is TLS?"This was quite a lucky topic. I submitted the talk back in January, so I had no idea that the Heartbleed bug would turn up and raise the interest that much. However, it also made me rework large parts of the talk, because after Heartbleed I though I had to get a much broader view on the issues. The slides are here as PDF, here as LaTeX and here on Slideshare.
There's also a video recording here (media.ccc.de) and also on Youtube.
I also had a short lightning talk with some thoughs on paperless life, however it's only in German. Slides are here (PDF), here (LaTeX) and here (Slideshare). (It seems there is no video recording, if it appears later I'll add the link.)