Monday, February 23. 2015
Software Privdog worse than Superfish
 tl;dr There is a software called Privdog. It totally breaks HTTPS security in a similar way as Superfish.
tl;dr There is a software called Privdog. It totally breaks HTTPS security in a similar way as Superfish.In case you haven't heard it the past days an Adware called Superfish made headlines. It was preinstalled on Lenovo laptops and it is bad: It totally breaks the security of HTTPS connections. The story became bigger when it became clear that a lot of other software packages were using the same technology Komodia with the same security risk.
What Superfish and other tools do is that it intercepts encrypted HTTPS traffic to insert Advertising on webpages. It does so by breaking the HTTPS encryption with a Man-in-the-Middle-attack, which is possible because it installs its own certificate into the operating system.
A number of people gathered in a chatroom and we noted a thread on Hacker News where someone asked whether a tool called PrivDog is like Superfish. PrivDog's functionality is to replace advertising in web pages with it's own advertising "from trusted sources". That by itself already sounds weird even without any security issues.
A quick analysis shows that it doesn't have the same flaw as Superfish, but it has another one which arguably is even bigger. While Superfish used the same certificate and key on all hosts PrivDog recreates a key/cert on every installation. However here comes the big flaw: PrivDog will intercept every certificate and replace it with one signed by its root key. And that means also certificates that weren't valid in the first place. It will turn your Browser into one that just accepts every HTTPS certificate out there, whether it's been signed by a certificate authority or not. We're still trying to figure out the details, but it looks pretty bad. (with some trickery you can do something similar on Superfish/Komodia, too)
There are some things that are completely weird. When one surfs to a webpage that has a self-signed certificate (really self-signed, not signed by an unknown CA) it adds another self-signed cert with 512 bit RSA into the root certificate store of Windows. All other certs get replaced by 1024 bit RSA certs signed by a locally created PrivDog CA.
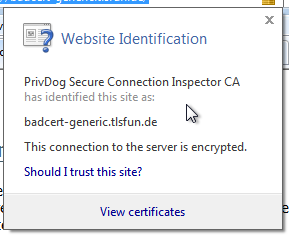 US-CERT writes: "Adtrustmedia PrivDog is promoted by the Comodo Group, which is an organization that offers SSL certificates and authentication solutions." A variant of PrivDog that is not affected by this issue is shipped with products produced by Comodo (see below). This makes this case especially interesting because Comodo itself is a certificate authority (they had issues before). As ACLU technologist Christopher Soghoian points out on Twitter the founder of PrivDog is the CEO of Comodo. (See this blog post.)
US-CERT writes: "Adtrustmedia PrivDog is promoted by the Comodo Group, which is an organization that offers SSL certificates and authentication solutions." A variant of PrivDog that is not affected by this issue is shipped with products produced by Comodo (see below). This makes this case especially interesting because Comodo itself is a certificate authority (they had issues before). As ACLU technologist Christopher Soghoian points out on Twitter the founder of PrivDog is the CEO of Comodo. (See this blog post.)We will try to collect information on this and other simliar software in a Wiki on Github. Discussions also happen on irc.ringoflightning.net #kekmodia.)
Thanks to Filippo, slipstream / raylee and others for all the analysis that has happened on this issue.
Update/Clarification: The dangerous TLS interception behaviour is part of the latest version of PrivDog 3.0.96.0, which can be downloaded from the PrivDog webpage. Comodo Internet Security bundles an earlier version of PrivDog that works with a browser extension, so it is not directly vulnerable to this threat. According to online sources PrivDog 3.0.96.0 was released in December 2014 and changed the TLS interception technology.
Update 2: Privdog published an Advisory.
Tuesday, November 4. 2014
Dancing protocols, POODLEs and other tales from TLS

The latest SSL attack was called POODLE. Image source
{kind=link}
.
I think it is crucial to understand what led to these vulnerabilities. I find POODLE and BERserk so interesting because these two vulnerabilities were both unnecessary and could've been avoided by intelligent design choices. Okay, let's start by investigating what went wrong.
The mess with CBC
POODLE (Padding Oracle On Downgraded Legacy Encryption) is a weakness in the CBC block mode and the padding of the old SSL protocol. If you've followed previous stories about SSL/TLS vulnerabilities this shouldn't be news. There have been a whole number of CBC-related vulnerabilities, most notably the Padding oracle (2003), the BEAST attack (2011) and the Lucky Thirteen attack (2013) (Lucky Thirteen is kind of my favorite, because it was already more or less mentioned in the TLS 1.2 standard). The POODLE attack builds on ideas already used in previous attacks.
CBC is a so-called block mode. For now it should be enough to understand that we have two kinds of ciphers we use to authenticate and encrypt connections – block ciphers and stream ciphers. Block ciphers need a block mode to operate. There's nothing necessarily wrong with CBC, it's the way CBC is used in SSL/TLS that causes problems. There are two weaknesses in it: Early versions (before TLS 1.1) use a so-called implicit Initialization Vector (IV) and they use a method called MAC-then-Encrypt (used up until the very latest TLS 1.2, but there's a new extension to fix it) which turned out to be quite fragile when it comes to security. The CBC details would be a topic on their own and I won't go into the details now. The long-term goal should be to get rid of all these (old-style) CBC modes, however that won't be possible for quite some time due to compatibility reasons. As most of these problems have been known since 2003 it's about time.
The evil Protocol Dance
The interesting question with POODLE is: Why does a security issue in an ancient protocol like SSLv3 bother us at all? SSL was developed by Netscape in the mid 90s, it has two public versions: SSLv2 and SSLv3. In 1999 (15 years ago) the old SSL was deprecated and replaced with TLS 1.0 standardized by the IETF. Now people still used SSLv3 up until very recently mostly for compatibility reasons. But even that in itself isn't the problem. SSL/TLS has a mechanism to safely choose the best protocol available. In a nutshell it works like this:
a) A client (e. g. a browser) connects to a server and may say something like "I want to connect with TLS 1.2“
b) The server may answer "No, sorry, I don't understand TLS 1.2, can you please connect with TLS 1.0?“
c) The client says "Ok, let's connect with TLS 1.0“
The point here is: Even if both server and client support the ancient SSLv3, they'd usually not use it. But this is the idealized world of standards. Now welcome to the real world, where things like this happen:
a) A client (e. g. a browser) connects to a server and may say something like "I want to connect with TLS 1.2“
b) The server thinks "Oh, TLS 1.2, never heard of that. What should I do? I better say nothing at all...“
c) The browser thinks "Ok, server doesn't answer, maybe we should try something else. Hey, server, I want to connect with TLS 1.1“
d) The browser will retry all SSL versions down to SSLv3 till it can connect.

The Protocol Dance is a Dance with the Devil. Image source
I first encountered the Protocol Dance back in 2008. Back then I already used a technology called SNI (Server Name Indication) that allows to have multiple websites with multiple certificates on a single IP address. I regularly got complains from people who saw the wrong certificates on those SNI webpages. A bug report to Firefox and some analysis revealed the reason: The protocol downgrades don't just happen when servers don't answer to new protocol requests, they also can happen on faulty or weak internet connections. SSLv3 does not support SNI, so when a downgrade to SSLv3 happens you get the wrong certificate. This was quite frustrating: A compatibility feature that was purely there to support broken hardware caused my completely legit setup to fail every now and then.
But the more severe problem is this: The Protocol Dance will allow an attacker to force downgrades to older (less secure) protocols. He just has to stop connection attempts with the more secure protocols. And this is why the POODLE attack was an issue after all: The problem was not backwards compatibility. The problem was attacker-controlled backwards compatibility.
The idea that the Protocol Dance might be a security issue wasn't completely new either. At the Black Hat conference this year Antoine Delignat-Lavaud presented a variant of an attack he calls "Virtual Host Confusion“ where he relied on downgrading connections to force SSLv3 connections.
"Whoever breaks it first“ - principle
The Protocol Dance is an example for something that I feel is an unwritten rule of browser development today: Browser vendors don't want things to break – even if the breakage is the fault of someone else. So they add all kinds of compatibility technologies that are purely there to support broken hardware. The idea is: When someone introduced broken hardware at some point – and it worked because the brokenness wasn't triggered at that point – the broken stuff is allowed to stay and all others have to deal with it.
To avoid the Protocol Dance a new feature is now on its way: It's called SCSV and the idea is that the Protocol Dance is stopped if both the server and the client support this new protocol feature. I'm extremely uncomfortable with that solution because it just adds another layer of duct tape and increases the complexity of TLS which already is much too complex.
There's another recent example which is very similar: At some point people found out that BIG-IP load balancers by the company F5 had trouble with TLS connection attempts larger than 255 bytes. However it was later revealed that connection attempts bigger than 512 bytes also succeed. So a padding extension was invented and it's now widespread behaviour of TLS implementations to avoid connection attempts between 256 and 511 bytes. To make matters completely insane: It was later found out that there is other broken hardware – SMTP servers by Ironport – that breaks when the handshake is larger than 511 bytes.
I have a principle when it comes to fixing things: Fix it where its broken. But the browser world works differently. It works with the „whoever breaks it first defines the new standard of brokenness“-principle. This is partly due to an unhealthy competition between browsers. Unfortunately they often don't compete very well on the security level. What you'll constantly hear is that browsers can't break any webpages because that will lead to people moving to other browsers.
I'm not sure if I entirely buy this kind of reasoning. For a couple of months the support for the ftp protocol in Chrome / Chromium is broken. I'm no fan of plain, unencrypted ftp and its only legit use case – unauthenticated file download – can just as easily be fulfilled with unencrypted http, but there are a number of live ftp servers that implement a legit and working protocol. I like Chromium and it's my everyday browser, but for a while the broken ftp support was the most prevalent reason I tend to start Firefox. This little episode makes it hard for me to believe that they can't break connections to some (broken) ancient SSL servers. (I just noted that the very latest version of Chromium has fixed ftp support again.)
BERserk, small exponents and PKCS #1 1.5

We have a problem with weak keys. Image source
{kind=link}
BERserk is actually a variant of a quite old vulnerability (you may begin to see a pattern here): The Bleichenbacher attack on RSA first presented at Crypto 2006. Now here things get confusing, because the cryptographer Daniel Bleichenbacher found two independent vulnerabilities in RSA. One in the RSA encryption in 1998 and one in RSA signatures in 2006, for convenience I'll call them BB98 (encryption) and BB06 (signatures). Both of these vulnerabilities expose faulty implementations of the old RSA standard PKCS #1 1.5. And both are what I like to call "zombie vulnerabilities“. They keep coming back, no matter how often you try to fix them. In April the BB98 vulnerability was re-discovered in the code of Java and it was silently fixed in OpenSSL some time last year.
But BERserk is about the other one: BB06. BERserk exposes the fact that inside the RSA function an algorithm identifier for the used hash function is embedded and its encoded with BER. BER is part of ASN.1. I could tell horror stories about ASN.1, but I'll spare you that for now, maybe this is a topic for another blog entry. It's enough to know that it's a complicated format and this is what bites us here: With some trickery in the BER encoding one can add further data into the RSA function – and this allows in certain situations to create forged signatures.
One thing should be made clear: Both the original BB06 attack and BERserk are flaws in the implementation of PKCS #1 1.5. If you do everything correct then you're fine. These attacks exploit the relatively simple structure of the old PKCS standard and they only work when RSA is done with a very small exponent. RSA public keys consist of two large numbers. The modulus N (which is a product of two large primes) and the exponent.
In his presentation at Crypto 2006 Daniel Bleichenbacher already proposed what would have prevented this attack: Just don't use RSA keys with very small exponents like three. This advice also went into various recommendations (e. g. by NIST) and today almost everyone uses 65537 (the reason for this number is that due to its binary structure calculations with it are reasonably fast).
There's just one problem: A small number of keys are still there that use the exponent e=3. And six of them are used by root certificates installed in every browser. These root certificates are the trust anchor of TLS (which in itself is a problem, but that's another story). Here's our problem: As long as there is one single root certificate with e=3 with such an attack you can create as many fake certificates as you want. If we had deprecated e=3 keys BERserk would've been mostly a non-issue.
There is one more aspect of this story: What's this PKCS #1 1.5 thing anyway? It's an old standard for RSA encryption and signatures. I want to quote Adam Langley on the PKCS standards here: "In a modern light, they are all completely terrible. If you wanted something that was plausible enough to be widely implemented but complex enough to ensure that cryptography would forever be hamstrung by implementation bugs, you would be hard pressed to do better."
Now there's a successor to the PKCS #1 1.5 standard: PKCS #1 2.1, which is based on technologies called PSS (Probabilistic Signature Scheme) and OAEP (Optimal Asymmetric Encryption Padding). It's from 2002 and in many aspects it's much better. I am kind of a fan here, because I wrote my thesis about this. There's just one problem: Although already standardized 2002 people still prefer to use the much weaker old PKCS #1 1.5. TLS doesn't have any way to use the newer PKCS #1 2.1 and even the current drafts for TLS 1.3 stick to the older - and weaker - variant.
What to do
I would take bets that POODLE wasn't the last TLS/CBC-issue we saw and that BERserk wasn't the last variant of the BB06-attack. Basically, I think there are a number of things TLS implementers could do to prevent further similar attacks:
* The Protocol Dance should die. Don't put another layer of duct tape around it (SCSV), just get rid of it. It will break a small number of already broken devices, but that is a reasonable price for avoiding the next protocol downgrade attack scenario. Backwards compatibility shouldn't compromise security.
* More generally, I think the working around for broken devices has to stop. Replace the „whoever broke it first“ paradigm with a „fix it where its broken“ paradigm. That also means I think the padding extension should be scraped.
* Keys with weak choices need to be deprecated at some point. In a long process browsers removed most certificates with short 1024 bit keys. They're working hard on deprecating signatures with the weak SHA1 algorithm. I think e=3 RSA keys should be next on the list for deprecation.
* At some point we should deprecate the weak CBC modes. This is probably the trickiest part, because up until very recently TLS 1.0 was all that most major browsers supported. The only way to avoid them is either using the GCM mode of TLS 1.2 (most browsers just got support for that in recent months) or using a very new extension that's rarely used at all today.
* If we have better technologies we should start using them. PKCS #1 2.1 is clearly superior to PKCS #1 1.5, at least if new standards get written people should switch to it.
Update: I just read that Mozilla Firefox devs disabled the protocol dance in their latest nightly build. Let's hope others follow.
Saturday, July 12. 2014
LibreSSL on Gentoo
Yesterday and today I played around with it on Gentoo Linux. I was able to replace my system's OpenSSL completely with LibreSSL and with few exceptions was able to successfully rebuild all packages using OpenSSL.
After getting this running on my own system I installed it on a test server. The Webpage tlsfun.de runs on that server. The functionality changes are limited, the only thing visible from the outside is the support for the experimental, not yet standardized ChaCha20-Poly1305 cipher suites, which is a nice thing.
A warning ahead: This is experimental, in no way stable or supported and if you try any of this you do it at your own risk. Please report any bugs you have with my overlay to me or leave a comment and don't disturb anyone else (from Gentoo or LibreSSL) with it. If you want to try it, you can get a portage overlay in a subversion repository. You can check it out with this command:
svn co https://svn.hboeck.de/libressl-overlay/
git clone https://github.com/gentoo/libressl.git
This is what I had to do to get things running:
LibreSSL itself
First of all the Gentoo tree contains a lot of packages that directly depend on openssl, so I couldn't just replace that. The correct solution to handle such issues would be to create a virtual package and change all packages depending directly on openssl to depend on the virtual. This is already discussed in the appropriate Gentoo bug, but this would mean patching hundreds of packages so I skipped it and worked around it by leaving a fake openssl package in place that itself depends on libressl.
LibreSSL deprecates some APIs from OpenSSL. The first thing that stopped me was that various programs use the functions RAND_egd() and RAND_egd_bytes(). I didn't know until yesterday what egd is. It stands for Entropy Gathering Daemon and is a tool written in perl meant to replace the functionality of /dev/(u)random on non-Linux-systems. The LibreSSL-developers consider it insecure and after having read what it is I have to agree. However, the removal of those functions causes many packages not to build, upon them wget, python and ruby. My workaround was to add two dummy functions that just return -1, which is the error code if the Entropy Gathering Daemon is not available. So the API still behaves like expected. I also posted the patch upstream, but the LibreSSL devs don't like it. So on the long term it's probably better to fix applications to stop trying to use egd, but for now these dummy functions make it easier for me to build my system.
The second issue popping up was that the libcrypto.so from libressl contains an undefined main() function symbol which causes linking problems with a couple of applications (subversion, xorg-server, hexchat). According to upstream this undefined symbol is intended and most likely these are bugs in the applications having linking problems. However, for now it was easier for me to patch the symbol out instead of fixing all the apps. Like the egd issue on the long term fixing the applications is better.
The third issue was that LibreSSL doesn't ship pkg-config (.pc) files, some apps use them to get the correct compilation flags. I grabbed the ones from openssl and adjusted them accordingly.
OpenSSH
This was the most interesting issue from all of them.
To understand this you have to understand how both LibreSSL and OpenSSH are developed. They are both from OpenBSD and they use some functions that are only available there. To allow them to be built on other systems they release portable versions which ship the missing OpenBSD-only-functions. One of them is arc4random().
Both LibreSSL and OpenSSH ship their compatibility version of arc4random(). The one from OpenSSH calls RAND_bytes(), which is a function from OpenSSL. The RAND_bytes() function from LibreSSL however calls arc4random(). Due to the linking order OpenSSH uses its own arc4random(). So what we have here is a nice recursion. arc4random() and RAND_bytes() try to call each other. The result is a segfault.
I fixed it by using the LibreSSL arc4random.c file for OpenSSH. I had to copy another function called arc4random_stir() from OpenSSH's arc4random.c and the header file thread_private.h. Surprisingly, this seems to work flawlessly.
Net-SSLeay
This package contains the perl bindings for openssl. The problem is a check for the openssl version string that expected the name OpenSSL and a version number with three numbers and a letter (like 1.0.1h). LibreSSL prints the version 2.0. I just hardcoded the OpenSSL version numer, which is not a real fix, but it works for now.
SpamAssassin
SpamAssassin's code for spamc requires SSLv2 functions to be available. SSLv2 is heavily insecure and should not be used at all and therefore the LibreSSL devs have removed all SSLv2 function calls. Luckily, Debian had a patch to remove SSLv2 that I could use.
libesmtp / gwenhywfar
Some DES-related functions (DES is the old Data Encryption Standard) in OpenSSL are available in two forms: With uppercase DES_ and with lowercase des_. I can only guess that the des_ variants are for backwards compatibliity with some very old versions of OpenSSL. According to the docs the DES_ variants should be used. LibreSSL has removed the des_ variants.
For gwenhywfar I wrote a small patch and sent it upstream. For libesmtp all the code was in ntlm. After reading that ntlm is an ancient, proprietary Microsoft authentication protocol I decided that I don't need that anyway so I just added --disable-ntlm to the ebuild.
Dovecot
In Dovecot two issues popped up. LibreSSL removed the SSL Compression functionality (which is good, because since the CRIME attack we know it's not secure). Dovecot's configure script checks for it, but the check doesn't work. It checks for a function that LibreSSL keeps as a stub. For now I just disabled the check in the configure script. The solution is probably to remove all remaining stub functions. The configure script could probably also be changed to work in any case.
The second issue was that the Dovecot code has some #ifdef clauses that check the openssl version number for the ECDH auto functionality that has been added in OpenSSL 1.0.2 beta versions. As the LibreSSL version number 2.0 is higher than 1.0.2 it thinks it is newer and tries to enable it, but the code is not present in LibreSSL. I changed the #ifdefs to check for the actual functionality by checking a constant defined by the ECDH auto code.
Apache httpd
The Apache http compilation complained about a missing ENGINE_CTRL_CHIL_SET_FORKCHECK. I have no idea what it does, but I found a patch to fix the issue, so I didn't investigate it further.
Further reading:
Someone else tried to get things running on Sabotage Linux.
Update: I've abandoned my own libressl overlay, a LibreSSL overlay by various Gentoo developers is now maintained at GitHub.
Wednesday, June 18. 2014
Should science journalists read the studies they write about?
Today I had a little twitter conversation which made me think about the responsibilities a science journalist has. It all started with a quote from Ivan Oransky (who is the editor of Retraction Watch) who said reporting on a study without reading it is 'journalist malpractice'. The source of this is another person who probably just heard him saying that, so I'm not sure what his exact words were.
Admittedly my first thought was: "He is right, too many journalists report about things they don't understand." My second thought was: "If he is right then I am probably guilty of 'journalist malpractice'." So I gave it a second thought and I probably won't agree with the statement any more.
I had a quick look at articles I wrote in the past and I have identified the last ten ones that more or less were coverages of a scientific piece of work. I have marked the ones I actually read with a [Y] and the ones I didn't read with a [N]. I've linked the appropriate scientific works and my articles (all in German). I must admit that I defined "read" widely, meaning that I haven't neccesarrily read the whole study/article in detail, I sometimes have just tried to parse the important parts for me.
Now the first thing that comes to mind is that I seem to have become lazier recently in reading studies. I hope this isn't the case and I hoestly think this is mostly coincidence. Now let's get into some details: The first example (the Turing Test) is interesting because it seems there is no scientific publication at all, just a press release. This probably tells you something about the quality of that "research", but while I read the press release I haven't even bothered to check if there is a scientific publication I could read.
The second example becomes interesting. I understand enough to know what a "quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic" actually is and I think I also understand what it means, but there's just no way I could understand the paper itself. This is complex mathematics. I seriously doubt that any journalist who covered this work actually read it. If there is I'd like to meet that person. I'm also very sure that the people who wrote the press release overselling this research have neither read this paper nor understood its implications.
I think this example gets to the point why I would disagree with the very general statement that a journalist should've read every scientific piece he writes about: It's sometimes so specialized that it's basically impossible. And I don't think this is an out of the line example. Just think about the Higgs Boson: Certainly this is something we want journalists to write about. But I'm pretty sure there are very few - if any - journalists who are able to read the scientific publications that are the basis of this discovery.
Some quick notes on the others: Number 4 was part of a 200-page-thesis and the press release was already pretty detailed and technically, I think it was legitimate to not read the original source in that case. Number 5 is somewhat similar to 2, because it is about an algorithm that includes complex math. Number 8 is not really a scientific paper, it is merely a news item on the Nature webpage. In the above list, the only case where I think maybe I should've read the scientific paper and I didn't is the Cochrane-Review on Tamiflu.
Conclusion: Don't get me wrong. I certainly welcome the idea that science journalists should have a look into the original scientific papers they write about more often - and this doesn't exclude myself. However, as shown above I doubt that this works in all cases.
Admittedly my first thought was: "He is right, too many journalists report about things they don't understand." My second thought was: "If he is right then I am probably guilty of 'journalist malpractice'." So I gave it a second thought and I probably won't agree with the statement any more.
I had a quick look at articles I wrote in the past and I have identified the last ten ones that more or less were coverages of a scientific piece of work. I have marked the ones I actually read with a [Y] and the ones I didn't read with a [N]. I've linked the appropriate scientific works and my articles (all in German). I must admit that I defined "read" widely, meaning that I haven't neccesarrily read the whole study/article in detail, I sometimes have just tried to parse the important parts for me.
- [X] Supposedly successful Turing Test taz, 2014-06-13
- [N]A quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic, Golem.de, 2014-05-17
- [N] Neuraminidase inhibitors for preventing and treating influenza in healthy adults and children (Cochrane-Review on Tamiflu), Neues Deutschland, 2014-04-26)
- [N] 20 Years of SSL/TLS Research: An Analysis of the Internet's Security Foundation, Golem.de, 2014-04-17
- [N] DRAFT FIPS 202 - SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions, Golem, 2014-04-05
- [Y] Using Frankencerts for Automated Adversarial Testing of Certificate Validation in SSL/TLS Implementations, Golem.de, 2014-04-04
- [Y] On the Practical Exploitability of Dual EC in TLS Implementations, Golem.de, 2014-04-01
- [Y] Publishers withdraw more than 120 gibberish papers, Golem.de, 2014-02-27
- [Y] Completeness of Reporting of Patient-Relevant Clinical Trial Outcomes: Comparison of Unpublished Clinical Study Reports with Publicly Available Data, taz, 2013-10-18
- [Y] Factoring RSA keys from certified smart cards: Coppersmith in the wild, Golem.de, 2013-09-17
Now the first thing that comes to mind is that I seem to have become lazier recently in reading studies. I hope this isn't the case and I hoestly think this is mostly coincidence. Now let's get into some details: The first example (the Turing Test) is interesting because it seems there is no scientific publication at all, just a press release. This probably tells you something about the quality of that "research", but while I read the press release I haven't even bothered to check if there is a scientific publication I could read.
The second example becomes interesting. I understand enough to know what a "quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic" actually is and I think I also understand what it means, but there's just no way I could understand the paper itself. This is complex mathematics. I seriously doubt that any journalist who covered this work actually read it. If there is I'd like to meet that person. I'm also very sure that the people who wrote the press release overselling this research have neither read this paper nor understood its implications.
I think this example gets to the point why I would disagree with the very general statement that a journalist should've read every scientific piece he writes about: It's sometimes so specialized that it's basically impossible. And I don't think this is an out of the line example. Just think about the Higgs Boson: Certainly this is something we want journalists to write about. But I'm pretty sure there are very few - if any - journalists who are able to read the scientific publications that are the basis of this discovery.
Some quick notes on the others: Number 4 was part of a 200-page-thesis and the press release was already pretty detailed and technically, I think it was legitimate to not read the original source in that case. Number 5 is somewhat similar to 2, because it is about an algorithm that includes complex math. Number 8 is not really a scientific paper, it is merely a news item on the Nature webpage. In the above list, the only case where I think maybe I should've read the scientific paper and I didn't is the Cochrane-Review on Tamiflu.
Conclusion: Don't get me wrong. I certainly welcome the idea that science journalists should have a look into the original scientific papers they write about more often - and this doesn't exclude myself. However, as shown above I doubt that this works in all cases.
Sunday, June 15. 2014
Slides from cryptography workshop for web developers
Friday, June 6. 2014
Enabling encryption by default and using HTTPS only
 I recently switched my personal web page and my blog to deliver content exclusively encrypted via HTTPS. I want to take this opportunity to give some facts about enabling TLS encryption by default and problems you may face.
I recently switched my personal web page and my blog to deliver content exclusively encrypted via HTTPS. I want to take this opportunity to give some facts about enabling TLS encryption by default and problems you may face.First of all the non-problems: Enabling HTTPS by default is almost never a significant performance problem. If people tell me that they can not possibly enable HTTPS due to performance reasons the first thing I ask is if they believe this or if they have real benchmark data showing this. If you don't believe me on that, I can quote Adam Langley from Google here: "In January this year (2010), Gmail switched to using HTTPS for everything by default. Previously it had been introduced as an option, but now all of our users use HTTPS to secure their email between their browsers and Google, all the time. In order to do this we had to deploy no additional machines and no special hardware. On our production frontend machines, SSL/TLS accounts for less than 1% of the CPU load, less than 10KB of memory per connection and less than 2% of network overhead."
Enabling HTTPS may cause a number of compatibility issues you may not instantly think about. First of all, we know that IPs in the IPv4 space are limited and expensive these days, so many people probably can't afford having a distinct IP for their web page. The solution to that is a TLS extension called SNI (Server Name Indication) which allows to have different certificates for different domain names on the same IP. It works in all major browsers and has been working for quite some time. The only major browser you'll face these days that doesn't support SNI is the Android 2.x browser.
There are some subtle issues with SNI. One is that browsers have fallback modes if they cannot connect via TLS and that may lead to a connection downgrade to SSLv3. And that ancient protocol doesn't support extensions and thus no SNI. So you may have irregular certificate errors if you are on a bad connection. A solution to that on the server side is to just disable SSLv3. It will make SNI much more reliable.
I don't really have a clear picture how many browsers will fail with SNI. There are probably a number of embedded devices out there like smart TVs with browsers or things alike that have problems. If you have any experiences feel free to post them in the comments.
The first issue I only noticed after I switched to HTTPS: I had an application called RSS Graffiti set up to automatically post all articles I write to a facebook fan page. After changing to HTTPS only it silently stopped working. Re-adding my feed didn't work. I now found a similar service called dlvr.it that I now use to post my RSS feed to facebook. I can only assume that this is a glimpse of a much bigger problem: There are probably tons of applications and online services out there not prepared for an encrypted Internet. If we want more people to deploy encryption by default we need to find these issues, document them and hopefully put enough pressure on their developers to fix them.
Another yet unfixed issue is the Yandex Bot. Yandex is a search engine and although you may never have heard of it it's probably one of the few companies in this area that can claim to be a serious competitor to Google. The reason you may not know it is that it's mostly operating in Russian language. Depending on who your page visitors are this may matter more or less.
The Yandex Bot speaks SSL but according to the Qualys SSL test it only supports the ancient SSLv3. So you have a choice between three possibilities: Don't enable HTTPS by default, enable HTTPS with a shitty configuration supporting ancient technology that will cause trouble for SNI or enable HTTPS with a sane configuration and get no traffic from the leading Russian search engine. None of them sounds very good to me.
Another issue is third party content. For security reasons today's browsers block all active HTTP content (CSS, JavaScript etc.) on HTTPS webpages. This isn't much of a problem for me, but it's a problem for webpages that rely on advertising because from what I hear most advertisement providers don't support HTTPS yet (Google being a laudable exception here). This is the main reason you won't see many news webpages enforcing HTTPS. However, I still have passive third party HTTP content on my blog. That's why you'll probably see a yellow warning sign in front of the URL in some browsers.
Tuesday, April 29. 2014
Incomplete Certificate Chains and Transvalid Certificates
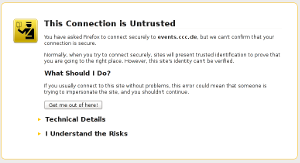 A number of people seem to be confused how to correctly install certificate chains for TLS servers. This happens quite often on HTTPS sites and to avoid having to explain things again and again I thought I'd write up something so I can refer to it. A few days ago flattr.com had a missing certificate chain (fixed now after I reported it) and various pages from the Chaos Computer Club have no certificate chain (not the main page, but several subdomains like events.ccc.de and frab.cccv.de). I've tried countless times to tell someone, but the problem persists. Maybe someone in charge will read this and fix it.
A number of people seem to be confused how to correctly install certificate chains for TLS servers. This happens quite often on HTTPS sites and to avoid having to explain things again and again I thought I'd write up something so I can refer to it. A few days ago flattr.com had a missing certificate chain (fixed now after I reported it) and various pages from the Chaos Computer Club have no certificate chain (not the main page, but several subdomains like events.ccc.de and frab.cccv.de). I've tried countless times to tell someone, but the problem persists. Maybe someone in charge will read this and fix it.Web browsers ship a list of certificate authorities (CAs) that are allowed to issue certificates for HTTPS websites. The whole system is inherently problematic, but right now that's not the point I want to talk about. Most of the time, people don't get their certificate from one of the root CAs but instead from a subordinate CA. Every CA is allowed to have unlimited numbers of sub CAs.
The correct way of delivering a certificate issued by a sub CA is to deliver both the host certificate and the certificate of the sub CA. This is neccesarry so the browser can check the complete chain from the root to the host. For example if you buy your certificate from RapidSSL then the RapidSSL cert is not in the browser. However, the RapidSSL certificate is signed by GeoTrust and that is in your browser. So if your HTTPS website delivers both its own certificate by RapidSSL and the RapidSSL certificate, the browser can validate the whole chain.
However, and here comes the tricky part: If you forget to deliver the chain certificate you often won't notice. The reason is that browsers cache chain certificates. In our example above if a user first visits a website with a certificate from RapidSSL and the correct chain the browser will already know the RapidSSL certificate. If the user then surfs to a page where the chain is missing the browser will still consider the certificate as valid. Such certificates with missing chain have been called transvalid, I think the term was first used by the EFF for their SSL Observatory.
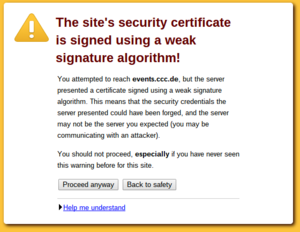
Chromium with bogus error message on a transvalid certificate
So how can you check if you have a transvalid certificate? One way is to use a fresh browser installation without anything cached. If you then surf to a page with a transvalid certificate, you'll get an error message (however, as we've just seen, not neccessarily a meaningful one). An easier way is to use the SSL Test from Qualys. It has a line "Chain issues" and if it shows "None" you're fine. If it shows "Incomplete" then your certificate is most likely transvalid. If it shows anything else you have other things to look after (a common issues is that people unneccesarily send the root certificate, which doesn't cause issues but may make things slower). The Qualys test test will tell you all kinds of other things about your TLS configuration. If it tells you something is insecure you should probably look after that, too.
Thursday, April 24. 2014
Easterhegg talk on TLS
 Last weekend I was at the Easterhegg in Stuttgart, an event organized by the Chaos Computer Club. I had a talk with the title "How broken is TLS?"
Last weekend I was at the Easterhegg in Stuttgart, an event organized by the Chaos Computer Club. I had a talk with the title "How broken is TLS?"This was quite a lucky topic. I submitted the talk back in January, so I had no idea that the Heartbleed bug would turn up and raise the interest that much. However, it also made me rework large parts of the talk, because after Heartbleed I though I had to get a much broader view on the issues. The slides are here as PDF, here as LaTeX and here on Slideshare.
There's also a video recording here (media.ccc.de) and also on Youtube.
I also had a short lightning talk with some thoughs on paperless life, however it's only in German. Slides are here (PDF), here (LaTeX) and here (Slideshare). (It seems there is no video recording, if it appears later I'll add the link.)
Thursday, March 6. 2014
Diffie Hellman and TLS with nonsense parameters
tl;dr A very short key exchange crashes Chromium/Chrome. Other browsers accept parameters for a Diffie Hellman key exchange that are completely nonsense. In combination with recently found TLS problems this could be a security risk.
People who tried to access the webpage https://demo.cmrg.net/ recently with a current version of the Chrome browser or its free pendant Chromium have experienced that it causes a crash in the Browser. On Tuesday this was noted on the oss-security mailing list. The news spread quickly and gave this test page some attention. But the page was originally not set up to crash browsers. According to a thread on LWN.net it was set up in November 2013 to test extremely short parameters for a key exchange with Diffie Hellman. Diffie Hellman can be used in the TLS protocol to establish a connection with perfect forward secrecy.
For a key exchange with Diffie Hellman a server needs two parameters, those are transmitted to the client on a connection attempt: A large prime and a so-called generator. The size of the prime defines the security of the algorithm. Usually, primes with 1024 bit are used today, although this is not very secure. Mostly the Apache web server is responsible for this, because before the very latest version 2.4.7 it was not able to use longer primes for key exchanges.
The test page mentioned above tries a connection with 16 bit - extremely short - and it seems it has caught a serious bug in chromium. We had a look how other browsers handle short or nonsense key exchange parameters.
Mozilla Firefox rejects connections with very short primes like 256 bit or shorter, but connections with 512 and 768 bit were possible. This is completely insecure today. When the Chromium crash is prevented with a patch that is available it has the same behavior. Both browsers use the NSS library that blocks connections with very short primes.
The test with the Internet Explorer was a bit difficult because usually the Microsoft browser doesn't support Diffie Hellman key exchanges. It is only possible if the server certificate uses a DSA key with a length of 1024 bit. DSA keys for TLS connections are extremely rare, most certificate authorities only support RSA keys and certificates with 1024 bit usually aren't issued at all today. But we found that CAcert, a free certificate authority that is not included in mainstream browsers, still allows DSA certificates with 1024 bit. The Internet Explorer allowed only connections with primes of 512 bit or larger. Interestingly, Microsoft's browser also rejects connections with 2048 and 4096 bit. So it seems Microsoft doesn't accept too much security. But in practice this is mostly irrelevant, with common RSA certificates the Internet Explorer only allows key exchange with elliptic curves.
Opera is stricter than other browsers with short primes. Connections below 1024 bit produce a warning and the user is asked if he really wants to connect. Other browsers should probably also reject such short primes. There are no legitimate reasons for a key exchange with less than 1024 bit.
The behavior of Safari on MacOS and Konqueror on Linux was interesting. Both browsers accepted almost any kind of nonsense parameters. Very short primes like 17 were accepted. Even with 15 as a "prime" a connection was possible.
No browser checks if the transmitted prime is really a prime. A test connection with 1024 bit which used a prime parameter that was non-prime was possible with all browsers. The reason is probably that testing a prime is not trivial. To test large primes the Miller-Rabin test is used. It doesn't provide a strict mathematical proof for primality, only a very high probability, but in practice this is good enough. A Miller-Rabin test with 1024 bit is very fast, but with 4096 bit it can take seconds on slow CPUs. For a HTTPS connection an often unacceptable delay.
At first it seems that it is irrelevant if browsers accept insecure parameters for a key exchange. Usually this does not happen. The only way this could happen is a malicious server, but that would mean that the server itself is not trustworthy. The transmitted data is not secure anyway in this case because the server could send it to third parties completely unencrypted.
But in connection with client certificates insecure parameters can be a problem. Some days ago a research team found some possibilities for attacks against the TLS protocol. In these attacks a malicious server could pretend to another server that it has the certificate of a user connecting to the malicious server. The authors of this so-called Triple Handshake attack mention one variant that uses insecure Diffie Hellman parameters. Client certificates are rarely used, so in most scenarios this does not matter. The authors suggest that TLS could use standardized parameters for a Diffie Hellman key exchange. Then a server could check quickly if the parameters are known - and would be sure that they are real primes. Future research may show if insecure parameters matter in other scenarios.
The crash problems in Chromium show that in the past software wasn't very well tested with nonsense parameters in cryptographic protocols. Similar tests for other protocols could reveal further problems.
The mentioned tests for browsers are available at the URL https://dh.tlsfun.de/.
This text is mostly a translation of a German article I wrote for the online magazine Golem.de.
People who tried to access the webpage https://demo.cmrg.net/ recently with a current version of the Chrome browser or its free pendant Chromium have experienced that it causes a crash in the Browser. On Tuesday this was noted on the oss-security mailing list. The news spread quickly and gave this test page some attention. But the page was originally not set up to crash browsers. According to a thread on LWN.net it was set up in November 2013 to test extremely short parameters for a key exchange with Diffie Hellman. Diffie Hellman can be used in the TLS protocol to establish a connection with perfect forward secrecy.
For a key exchange with Diffie Hellman a server needs two parameters, those are transmitted to the client on a connection attempt: A large prime and a so-called generator. The size of the prime defines the security of the algorithm. Usually, primes with 1024 bit are used today, although this is not very secure. Mostly the Apache web server is responsible for this, because before the very latest version 2.4.7 it was not able to use longer primes for key exchanges.
The test page mentioned above tries a connection with 16 bit - extremely short - and it seems it has caught a serious bug in chromium. We had a look how other browsers handle short or nonsense key exchange parameters.
Mozilla Firefox rejects connections with very short primes like 256 bit or shorter, but connections with 512 and 768 bit were possible. This is completely insecure today. When the Chromium crash is prevented with a patch that is available it has the same behavior. Both browsers use the NSS library that blocks connections with very short primes.
The test with the Internet Explorer was a bit difficult because usually the Microsoft browser doesn't support Diffie Hellman key exchanges. It is only possible if the server certificate uses a DSA key with a length of 1024 bit. DSA keys for TLS connections are extremely rare, most certificate authorities only support RSA keys and certificates with 1024 bit usually aren't issued at all today. But we found that CAcert, a free certificate authority that is not included in mainstream browsers, still allows DSA certificates with 1024 bit. The Internet Explorer allowed only connections with primes of 512 bit or larger. Interestingly, Microsoft's browser also rejects connections with 2048 and 4096 bit. So it seems Microsoft doesn't accept too much security. But in practice this is mostly irrelevant, with common RSA certificates the Internet Explorer only allows key exchange with elliptic curves.
Opera is stricter than other browsers with short primes. Connections below 1024 bit produce a warning and the user is asked if he really wants to connect. Other browsers should probably also reject such short primes. There are no legitimate reasons for a key exchange with less than 1024 bit.
The behavior of Safari on MacOS and Konqueror on Linux was interesting. Both browsers accepted almost any kind of nonsense parameters. Very short primes like 17 were accepted. Even with 15 as a "prime" a connection was possible.
No browser checks if the transmitted prime is really a prime. A test connection with 1024 bit which used a prime parameter that was non-prime was possible with all browsers. The reason is probably that testing a prime is not trivial. To test large primes the Miller-Rabin test is used. It doesn't provide a strict mathematical proof for primality, only a very high probability, but in practice this is good enough. A Miller-Rabin test with 1024 bit is very fast, but with 4096 bit it can take seconds on slow CPUs. For a HTTPS connection an often unacceptable delay.
At first it seems that it is irrelevant if browsers accept insecure parameters for a key exchange. Usually this does not happen. The only way this could happen is a malicious server, but that would mean that the server itself is not trustworthy. The transmitted data is not secure anyway in this case because the server could send it to third parties completely unencrypted.
But in connection with client certificates insecure parameters can be a problem. Some days ago a research team found some possibilities for attacks against the TLS protocol. In these attacks a malicious server could pretend to another server that it has the certificate of a user connecting to the malicious server. The authors of this so-called Triple Handshake attack mention one variant that uses insecure Diffie Hellman parameters. Client certificates are rarely used, so in most scenarios this does not matter. The authors suggest that TLS could use standardized parameters for a Diffie Hellman key exchange. Then a server could check quickly if the parameters are known - and would be sure that they are real primes. Future research may show if insecure parameters matter in other scenarios.
The crash problems in Chromium show that in the past software wasn't very well tested with nonsense parameters in cryptographic protocols. Similar tests for other protocols could reveal further problems.
The mentioned tests for browsers are available at the URL https://dh.tlsfun.de/.
This text is mostly a translation of a German article I wrote for the online magazine Golem.de.
Saturday, January 26. 2013
Explain hard stuff with the 1000 most common words #UPGOERFIVE
Saturday, January 19. 2013
How to configure your HTTPS server
Wednesday, October 17. 2012
Das Ärgernis GEMA
 Über die GEMA könnte man viel schreiben und sich viel ärgern, etwa jedes zweite mal, wenn man auf ein Youtube-Video klickt und erzählt bekommt, dass dieses Video "in Deinem Land nicht verfügbar" ist. Ein besonders krasses Ärgernis ist aber die sogenannte GEMA-Vermutung. Sie bewirkt letztendlich, dass die GEMA Geld für Musiker kassieren kann, die überhaupt nicht bei ihr Mitglied sind.
Über die GEMA könnte man viel schreiben und sich viel ärgern, etwa jedes zweite mal, wenn man auf ein Youtube-Video klickt und erzählt bekommt, dass dieses Video "in Deinem Land nicht verfügbar" ist. Ein besonders krasses Ärgernis ist aber die sogenannte GEMA-Vermutung. Sie bewirkt letztendlich, dass die GEMA Geld für Musiker kassieren kann, die überhaupt nicht bei ihr Mitglied sind.Wie funktioniert das? Grob gesagt sagt die GEMA-Vermutung folgendes: Man geht davon aus, dass fast alle Musik von der GEMA vertreten wird und somit im Zweifel immer angenommen wird, dass die GEMA Ansprüche auf Zahlungen hat. Konkret: Wer ein Konzert ausrichten, eine CD produzieren oder sonst etwas mit Musik machen will, muss damit rechnen, von der GEMA behelligt zu werden - und zwar auch dann, wenn die betroffenen Künstler nicht bei der GEMA Mitglied sind. Denn beweisen muss man das selbst. Das führt zu absurden Situationen: Das Landgericht Mannheim forderte etwa, dass alle Musiker, die in der Freiburger KTS über mehrere Jahre aufgetreten sind, als Zeugen persönlich vor Gericht erscheinen sollten. Eine schriftliche Erklärung der Musiker reichte nicht aus. Kürzlich Schlagzeilen machte ein Fall, in dem die Musikpiraten an die GEMA zahlen sollten, weil auf einem von ihnen veröffentlichten Sampler ein Musiker vertreten war, der mit einem Pseudonym auftrat und seinen bürgerlichen Namen nicht nennen wollte. Auch hier bekam die GEMA recht.
Die GEMA-Vermutung ist in der heutigen Zeit völlig absurd. Eingeführt wurde sie, als tatsächlich noch davon ausgegangen werden konnte, dass die Mehrzahl der erfolgreicheren Künstler in ihr Mitlgied waren. Heute gibt es aber zahllose Musiker und Künstler, die andere Wege gehen, die auf Creative Commons-Lizenzen setzen und die mit der GEMA nichts am Hut haben.
Warum schreibe ich das alles? Weil gerade beim Bundestag eine Petition gegen die GEMA-Vermutung läuft - die ihr bitte alle SOFORT unterstützen solltet. Denn sie läuft nur noch bis heute abend und braucht noch gut 10.000 Unterstützer, damit es zu einer Anhörung kommt.
Thursday, October 27. 2011
Verteidigung meiner Diplomarbeit
 Die Verteidigung meiner Diplomarbeit über RSA-PSS an der HU Berlin wird am 10. November stattfinden. Die Veranstaltung ist öffentlich (17:00 Uhr s. t., Rudower Chausee 25, Campus Berlin-Adlershof, Raum 3'113). Achtung: Termin und Ort verschoben.
Die Verteidigung meiner Diplomarbeit über RSA-PSS an der HU Berlin wird am 10. November stattfinden. Die Veranstaltung ist öffentlich (17:00 Uhr s. t., Rudower Chausee 25, Campus Berlin-Adlershof, Raum 3'113). Achtung: Termin und Ort verschoben.Hier die Ankündigung:
Das Verschlüsselungs- und Signaturverfahren RSA ist das mit Abstand am häufigsten eingesetzte Public Key-Verfahren. RSA kann nicht in seiner ursprünglichen Form eingesetzt werden, da hierbei massive Sicherheitsprobleme auftreten. Zur Vorverarbeitung ist ein sogenanntes Padding notwendig. Bislang wird hierfür meist eine simple Hash-Funktion eingesetzt. Schon 1996 stellten Mihir Bellare und Philipp Rogaway für Signaturen ein verbessertes Verfahren mit dem Namen "Probabilistic Signature Scheme" (PSS) vor. Es garantiert unter bestimmten Annahmen "beweisbare" Sicherheit.
In der Diplomarbeit wurde untersucht, welche Vorteile RSA-PSS gegenüber früheren Verfahren bietet und inwieweit RSA-PSS in verbreiteten Protokollen bereits zum Einsatz kommt. Weiterhin wurde eine Implementierung des Verfahrens für X.509-Zertifikate für die nss-Bibliothek erstellt. nss wird unter anderem von Mozilla Firefox und Google Chrome eingesetzt.
Friday, August 12. 2011
OpenLeaks doing strange things with SSL
 OpenLeaks is a planned platform like WikiLeaks, founded by ex-Wikileaks member Daniel Domscheit-Berg. It's been announced a while back and a beta is currently presented in cooperation with the newspaper taz during the Chaos Communication Camp (where I am right now).
OpenLeaks is a planned platform like WikiLeaks, founded by ex-Wikileaks member Daniel Domscheit-Berg. It's been announced a while back and a beta is currently presented in cooperation with the newspaper taz during the Chaos Communication Camp (where I am right now).I had a short look and found some things noteworthy:
The page is SSL-only, any connection attempt with http will be forwarded to https. When I opened the page in firefox, I got a message that the certificate is not valid. That's obviously bad, although most people probably won't see this message.
What is wrong here is that an intermediate certificate is missing - we have a so-called transvalid certificate (the term "transvalid" has been used for it by the EFF SSL Observatory project). Firefox includes the root certificate from Go Daddy, but the certificate is signed by another certificate which itself is signed by the root certificate. To make this work, one has to ship the so-called intermediate certificate when opening an SSL connection.
The reason why most people won't see this warning and why it probably went unnoticed is that browsers remember intermediate certificates. If someone ever was on a webpage which uses the Go Daddy intermediate certificate, he won't see this warning. I saw it because I usually don't use Firefox and it had a rather fresh configuration.
There was another thing that bothered me: On top of the page, there's a line "Before submitting anything verify that the fingerprints of the SSL certificate match!" followed by a SHA-1 certificate fingerprint. Beside the fact that it's english on a german page, this is a rather ridiculous suggestion. Checking a fingerprint of an SSL connection against one you got through exactly that SSL connection is bogus. Checking a certificate fingerprint doesn't make any sense if you got it through a connection that was secured with that certificate. If checking a fingerprint should make sense, it has to come through a different channel. Beside that, nowhere is explained how a user should do that and what a fingerprint is at all. I doubt that this is of any help for the targetted audience by a whistleblower platform - it will probably only confuse people.
Both issues give me the impression that the people who designed OpenLeaks don't really know how SSL works - and that's not a good sign.
Saturday, July 30. 2011
Using EFF SSL Observatory to find weak keys in CAcert

(c) EFF, Creative Commons by
I did some checks on the all_certs table selecting the certificates from cacert. I found out that there were 143 valid certificates with 512 bit. That is completely insecure and breakable by a home computer today. I also found that the majority of certificates still has 1024 bit, which by today's standards should be considered harmful - there have been no public breaks yet, but it's expected that it's possible to build an RSA-1024 cracker for an attacker with enough money.
I did the following query on the database:
SELECT RSA_Modulus_Bits, count(*) FROM all_certs WHERE `Validity:Not After datetime` > '2010-03-08' AND ( `Issuer` like '%CAcert.org%' OR `Issuer` like '%cacert.org') GROUP BY `RSA_Modulus_Bits` ORDER BY count(*);
+------------------+----------+
| RSA_Modulus_Bits | count(*) |
+------------------+----------+
[...]
| 512 | 143 |
| 4096 | 632 |
| 2048 | 3716 |
| 1024 | 5790 |
+------------------+----------+
Now, what further checks can we do? I checked for the RSA exponent. I found two certificates in the database with exponent 3. RSA with low exponent is also considered insecure, although one has to state that this is not a serious issue. RSA with low exponents is not insecure by itself, but it can create vulnerabilities in combination with other issues (if you're interested in details, read my diploma thesis).
I have not checked the CAcert database for the Debian SSL vulnerability, as that would've been non-trivial. There were scripts shipped with the SSL Observatory data, but I found them not easy to use, so I skipped that part.
My suggestions to cacert were to revoke all certificates with serious issues (like the 512 bit certificates). Also, I suggested that new certificates with insecure settings like RSA below 2048 bits or a low exponent should not be allowed. CAcert did most of this. By now, all 512 bit certificates should be revoked and it is impossible to create new ones below 1024 bit or with low exponents. It is however still possible to create 1024 bit certificates, which is due to a limitation in the client certificate creation script for the Internet Explorer. They say they're working on this and plan to prevent 1024 bit certificates in the future. They also told me that they've checked for the Debian SSL bug.
I've reported the issue on the 11th March and got a reply on the same day - that's pretty okay, one slight thing still: There was no security contact with a PGP key listed on the webpage (but I got a PGP-encrypted contact once I asked for it). That's not good, I expect especially from a security project that I can contact them for security issues with encrypted mail. One can also argue if four months is a bit long to fix such an issue, but as it was far away from being trivial, this can be apologized.
I'd say that I'm quite satisfied with the reactions of CAcert. I always got fast replies to questions I had and the issues were resolved in a proper way. I have other points of criticism on the security of CAcert, the issue that bothers me most is that they still use SHA-1 and refuse to switch to a more secure hashing algorithm like SHA-512, although all major browsers have support for this since a long time.
I want to encourage others to do further tests on CAcert. I'd like to see CAcert being an authority that does better than the commercial ones. The database from the observatory is a treasure and should be used by projects like CAcert to improve their security.