Thursday, September 7. 2017
In Search of a Secure Time Source
Update: This blogpost was written before NTS was available, and the information is outdated. If you are looking for a modern solution, I recommend using software and a time server with Network Time Security, as specified in RFC 8915.
 All our computers and smartphones have an internal clock and need to know the current time. As configuring the time manually is annoying it's common to set the time via Internet services. What tends to get forgotten is that a reasonably accurate clock is often a crucial part of security features like certificate lifetimes or features with expiration times like HSTS. Thus the timesetting should be secure - but usually it isn't.
All our computers and smartphones have an internal clock and need to know the current time. As configuring the time manually is annoying it's common to set the time via Internet services. What tends to get forgotten is that a reasonably accurate clock is often a crucial part of security features like certificate lifetimes or features with expiration times like HSTS. Thus the timesetting should be secure - but usually it isn't.
I'd like my systems to have a secure time. So I'm looking for a timesetting tool that fullfils two requirements:
Although these seem like trivial requirements to my knowledge such a tool doesn't exist. These are relatively loose requirements. One might want to add:
Some people need a very accurate time source, for example for certain scientific use cases. But that's outside of my scope. For the vast majority of use cases a clock that is off by a few seconds doesn't matter. While it's certainly a good idea to consider rogue servers given the current state of things I'd be happy to have a solution where I simply trust a server from Google or any other major Internet entity.
So let's look at what we have:
NTP
The common way of setting the clock is the NTP protocol. NTP itself has no transport security built in. It's a plaintext protocol open to manipulation and man in the middle attacks.
There are two variants of "secure" NTP. "Autokey", an authenticated variant of NTP, is broken. There's also a symmetric authentication, but that is impractical for widespread use, as it would require to negotiate a pre-shared key with the time server in advance.
NTPsec and Ntimed
In response to some vulnerabilities in the reference implementation of NTP two projects started developing "more secure" variants of NTP. Ntimed - a rewrite by Poul-Henning Kamp - and NTPsec, a fork of the original NTP software. Ntimed hasn't seen any development for several years, NTPsec seems active. NTPsec had some controversies with the developers of the original NTP reference implementation and its main developer is - to put it mildly - a controversial character.
But none of that matters. Both projects don't implement a "secure" NTP. The "sec" in NTPsec refers to the security of the code, not to the security of the protocol itself. It's still just an implementation of the old, insecure NTP.
Network Time Security
There's a draft for a new secure variant of NTP - called Network Time Security. It adds authentication to NTP.
However it's just a draft and it seems stalled. It hasn't been updated for over a year. In any case: It's not widely implemented and thus it's currently not usable. If that changes it may be an option.
tlsdate
tlsdate is a hack abusing the timestamp of the TLS protocol. The TLS timestamp of a server can be used to set the system time. This doesn't provide high accuracy, as the timestamp is only given in seconds, but it's good enough.
I've used and advocated tlsdate for a while, but it has some problems. The timestamp in the TLS handshake doesn't really have any meaning within the protocol, so several implementers decided to replace it with a random value. Unfortunately that is also true for the default server hardcoded into tlsdate.
Some Linux distributions still ship a package with a default server that will send random timestamps. The result is that your system time is set to a random value. I reported this to Ubuntu a while ago. It never got fixed, however the latest Ubuntu version Zesty Zapis (17.04) doesn't ship tlsdate any more.
Given that Google has shipped tlsdate for some in ChromeOS time it seems unlikely that Google will send randomized timestamps any time soon. Thus if you use tlsdate with www.google.com it should work for now. But it's no future-proof solution.
TLS 1.3 removes the TLS timestamp, so this whole concept isn't future-proof. Alternatively it supports using an HTTPS timestamp. The development of tlsdate has stalled, it hasn't seen any updates lately. It doesn't build with the latest version of OpenSSL (1.1) So it likely will become unusable soon.
 OpenNTPD
OpenNTPD
The developers of OpenNTPD, the NTP daemon from OpenBSD, came up with a nice idea. NTP provides high accuracy, yet no security. Via HTTPS you can get a timestamp with low accuracy. So they combined the two: They use NTP to set the time, but they check whether the given time deviates significantly from an HTTPS host. So the HTTPS host provides safety boundaries for the NTP time.
This would be really nice, if there wasn't a catch: This feature depends on an API only provided by LibreSSL, the OpenBSD fork of OpenSSL. So it's not available on most common Linux systems. (Also why doesn't the OpenNTPD web page support HTTPS?)
Roughtime
Roughtime is a Google project. It fetches the time from multiple servers and uses some fancy cryptography to make sure that malicious servers get detected. If a roughtime server sends a bad time then the client gets a cryptographic proof of the malicious behavior, making it possible to blame and shame rogue servers. Roughtime doesn't provide the high accuracy that NTP provides.
From a security perspective it's the nicest of all solutions. However it fails the availability test. Google provides two reference implementations in C++ and in Go, but it's not packaged for any major Linux distribution. Google has an unfortunate tendency to use unusual dependencies and arcane build systems nobody else uses, so packaging it comes with some challenges.
One line bash script beats all existing solutions
As you can see none of the currently available solutions is really feasible and none fulfils the two mild requirements of authenticity and availability.
This is frustrating given that it's a really simple problem. In fact, it's so simple that you can solve it with a single line bash script:
This line sends an HTTPS request to Google, fetches the date header from the response and passes that to the date command line utility.
It provides authenticity via TLS. If the current system time is far off then this fails, as the TLS connection relies on the validity period of the current certificate. Google currently uses certificates with a validity of around three months. The accuracy is only in seconds, so it doesn't qualify for high accuracy requirements. There's no protection against a rogue Google server providing a wrong time.
Another potential security concern may be that Google might attack the parser of the date setting tool by serving a malformed date string. However I ran american fuzzy lop against it and it looks robust.
While this certainly isn't as accurate as NTP or as secure as roughtime, it's better than everything else that's available. I put this together in a slightly more advanced bash script called httpstime.
All our computers and smartphones have an internal clock and need to know the current time. As configuring the time manually is annoying it's common to set the time via Internet services. What tends to get forgotten is that a reasonably accurate clock is often a crucial part of security features like certificate lifetimes or features with expiration times like HSTS. Thus the timesetting should be secure - but usually it isn't.I'd like my systems to have a secure time. So I'm looking for a timesetting tool that fullfils two requirements:
- It provides authenticity of the time and is not vulnerable to man in the middle attacks.
- It is widely available on common Linux systems.
Although these seem like trivial requirements to my knowledge such a tool doesn't exist. These are relatively loose requirements. One might want to add:
- The timesetting needs to provide a good accuracy.
- The timesetting needs to be protected against malicious time servers.
Some people need a very accurate time source, for example for certain scientific use cases. But that's outside of my scope. For the vast majority of use cases a clock that is off by a few seconds doesn't matter. While it's certainly a good idea to consider rogue servers given the current state of things I'd be happy to have a solution where I simply trust a server from Google or any other major Internet entity.
So let's look at what we have:
NTP
The common way of setting the clock is the NTP protocol. NTP itself has no transport security built in. It's a plaintext protocol open to manipulation and man in the middle attacks.
There are two variants of "secure" NTP. "Autokey", an authenticated variant of NTP, is broken. There's also a symmetric authentication, but that is impractical for widespread use, as it would require to negotiate a pre-shared key with the time server in advance.
NTPsec and Ntimed
In response to some vulnerabilities in the reference implementation of NTP two projects started developing "more secure" variants of NTP. Ntimed - a rewrite by Poul-Henning Kamp - and NTPsec, a fork of the original NTP software. Ntimed hasn't seen any development for several years, NTPsec seems active. NTPsec had some controversies with the developers of the original NTP reference implementation and its main developer is - to put it mildly - a controversial character.
But none of that matters. Both projects don't implement a "secure" NTP. The "sec" in NTPsec refers to the security of the code, not to the security of the protocol itself. It's still just an implementation of the old, insecure NTP.
Network Time Security
There's a draft for a new secure variant of NTP - called Network Time Security. It adds authentication to NTP.
However it's just a draft and it seems stalled. It hasn't been updated for over a year. In any case: It's not widely implemented and thus it's currently not usable. If that changes it may be an option.
tlsdate
tlsdate is a hack abusing the timestamp of the TLS protocol. The TLS timestamp of a server can be used to set the system time. This doesn't provide high accuracy, as the timestamp is only given in seconds, but it's good enough.
I've used and advocated tlsdate for a while, but it has some problems. The timestamp in the TLS handshake doesn't really have any meaning within the protocol, so several implementers decided to replace it with a random value. Unfortunately that is also true for the default server hardcoded into tlsdate.
Some Linux distributions still ship a package with a default server that will send random timestamps. The result is that your system time is set to a random value. I reported this to Ubuntu a while ago. It never got fixed, however the latest Ubuntu version Zesty Zapis (17.04) doesn't ship tlsdate any more.
Given that Google has shipped tlsdate for some in ChromeOS time it seems unlikely that Google will send randomized timestamps any time soon. Thus if you use tlsdate with www.google.com it should work for now. But it's no future-proof solution.
TLS 1.3 removes the TLS timestamp, so this whole concept isn't future-proof. Alternatively it supports using an HTTPS timestamp. The development of tlsdate has stalled, it hasn't seen any updates lately. It doesn't build with the latest version of OpenSSL (1.1) So it likely will become unusable soon.
OpenNTPDThe developers of OpenNTPD, the NTP daemon from OpenBSD, came up with a nice idea. NTP provides high accuracy, yet no security. Via HTTPS you can get a timestamp with low accuracy. So they combined the two: They use NTP to set the time, but they check whether the given time deviates significantly from an HTTPS host. So the HTTPS host provides safety boundaries for the NTP time.
This would be really nice, if there wasn't a catch: This feature depends on an API only provided by LibreSSL, the OpenBSD fork of OpenSSL. So it's not available on most common Linux systems. (Also why doesn't the OpenNTPD web page support HTTPS?)
Roughtime
Roughtime is a Google project. It fetches the time from multiple servers and uses some fancy cryptography to make sure that malicious servers get detected. If a roughtime server sends a bad time then the client gets a cryptographic proof of the malicious behavior, making it possible to blame and shame rogue servers. Roughtime doesn't provide the high accuracy that NTP provides.
From a security perspective it's the nicest of all solutions. However it fails the availability test. Google provides two reference implementations in C++ and in Go, but it's not packaged for any major Linux distribution. Google has an unfortunate tendency to use unusual dependencies and arcane build systems nobody else uses, so packaging it comes with some challenges.
One line bash script beats all existing solutions
As you can see none of the currently available solutions is really feasible and none fulfils the two mild requirements of authenticity and availability.
This is frustrating given that it's a really simple problem. In fact, it's so simple that you can solve it with a single line bash script:
date -s "$(curl -sI https://www.google.com/|grep -i 'date:'|sed -e 's/^.ate: //g')"This line sends an HTTPS request to Google, fetches the date header from the response and passes that to the date command line utility.
It provides authenticity via TLS. If the current system time is far off then this fails, as the TLS connection relies on the validity period of the current certificate. Google currently uses certificates with a validity of around three months. The accuracy is only in seconds, so it doesn't qualify for high accuracy requirements. There's no protection against a rogue Google server providing a wrong time.
Another potential security concern may be that Google might attack the parser of the date setting tool by serving a malformed date string. However I ran american fuzzy lop against it and it looks robust.
While this certainly isn't as accurate as NTP or as secure as roughtime, it's better than everything else that's available. I put this together in a slightly more advanced bash script called httpstime.
Tuesday, September 5. 2017
Abandoned Domain Takeover as a Web Security Risk
In the modern web it's extremely common to include thirdparty content on web pages. Youtube videos, social media buttons, ads, statistic tools, CDNs for fonts and common javascript files - there are plenty of good and many not so good reasons for this. What is often forgotten is that including other peoples content means giving other people control over your webpage. This is obviously particularly risky if it involves javascript, as this gives a third party full code execution rights in the context of your webpage.
I recently helped a person whose Wordpress blog had a problem: The layout looked broken. The cause was that the theme used a font from a web host - and that host was down. This was easy to fix. I was able to extract the font file from the Internet Archive and store a copy locally. But it made me thinking: What happens if you include third party content on your webpage and the service from which you're including it disappears?
I put together a simple script that would check webpages for HTML tags with the src attribute. If the src attribute points to an external host it checks if the host name actually can be resolved to an IP address. I ran that check on the Alexa Top 1 Million list. It gave me some interesting results. (This methodology has some limits, as it won't discover indirect src references or includes within javascript code, but it should be good enough to get a rough picture.)
Yahoo! Web Analytics was shut down in 2012, yet in 2017 Flickr still tried to use it
The webpage of Flickr included a script from Yahoo! Web Analytics. If you don't know Yahoo Analytics - that may be because it's been shut down in 2012. Although Flickr is a Yahoo! company it seems they haven't noted for quite a while. (The code is gone now, likely because I mentioned it on Twitter.) This example has no security impact as the domain still belongs to Yahoo. But it likely caused an unnecessary slowdown of page loads over many years.
Going through the list of domains I saw plenty of the things you'd expect: Typos, broken URLs, references to localhost and subdomains no longer in use. Sometimes I saw weird stuff, like references to javascript from browser extensions. My best explanation is that someone had a plugin installed that would inject those into pages and then created a copy of the page with the browser which later endet up being used as the real webpage.
I looked for abandoned domain names that might be worth registering. There weren't many. In most cases the invalid domains were hosts that didn't resolve, but that still belonged to someone. I found a few, but they were only used by one or two hosts.
Takeover of unregistered Azure subdomain
But then I saw a couple of domains referencing a javascript from a non-resolving host called piwiklionshare.azurewebsites.net. This is a subdomain from Microsoft's cloud service Azure. Conveniently Azure allows creating test accounts for free, so I was able to grab this subdomain without any costs.
Doing so allowed me to look at the HTTP log files and see what web pages included code from that subdomain. All of them were local newspapers from the US. 20 of them belonged to two adjacent IP addresses, indicating that they were all managed by the same company. I was able to contact them. While I never received any answer, shortly afterwards the code was gone from all those pages.
 However the page with most hits was not so easy to contact. It was also a newspaper, the Saline Courier. I tried contacting them directly, their chief editor and their second chief editor. No answer.
However the page with most hits was not so easy to contact. It was also a newspaper, the Saline Courier. I tried contacting them directly, their chief editor and their second chief editor. No answer.
After a while I wondered what I could do. Ultimately at some point Microsoft wouldn't let me host that subdomain any longer for free. I didn't want to risk that others could grab that subdomain, but at the same time I obviously also didn't want to pay in order to keep some web page safe whose owners didn't even bother to read my e-mails.
But of course I had another way of contacting them: I could execute Javascript on their web page and use that for some friendly defacement. After some contemplating whether that would be a legitimate thing to do I decided to go for it. I changed the background color to some flashy pink and send them a message. The page remained usable, but it was a message hard to ignore.
With some trouble on the way - first they broke their CSS, then they showed a PHP error message, then they reverted to the page with the defacement. But in the end they managed to remove the code.
There are still a couple of other pages that include that Javascript. Most of them however look like broken test webpages. The only legitimately looking webpage that still embeds that code is the Columbia Missourian. However they don't embed it on the start page, only on the error reporting form they have for every article. It's been several weeks now, they don't seem to care.
What happens to abandoned domains?
There are reasons to believe that what I showed here is only the tip of the iceberg. In many cases when services discontinue their domains don't simply disappear. If the domain name is valuable then almost certainly someone will try to register it immediately after it becomes available.
Someone trying to abuse abandoned domains could watch out for services going ot of business or widely referenced domains becoming available. Just to name an example: I found a couple of hosts referencing subdomains of compete.com. If you go to their web page, you can learn that the company Compete has discontinued its service in 2016. How long will they keep their domain? And what will happen with it afterwards? Whoever gets the domain can hijack all the web pages that still include javascript from it.
Be sure to know what you include
There are some obvious takeaways from this. If you include other peoples code on your web page then you should know what that means: You give them permission to execute whatever they want on your web page. This means you need to wonder how much you can trust them.
At the very least you should be aware who is allowed to execute code on your web page. If they shut down their business or discontinue the service you have been using then you obviously should remove that code immediately. And if you include code from a web statistics service that you never look at anyway you may simply want to remove that as well.
I recently helped a person whose Wordpress blog had a problem: The layout looked broken. The cause was that the theme used a font from a web host - and that host was down. This was easy to fix. I was able to extract the font file from the Internet Archive and store a copy locally. But it made me thinking: What happens if you include third party content on your webpage and the service from which you're including it disappears?
I put together a simple script that would check webpages for HTML tags with the src attribute. If the src attribute points to an external host it checks if the host name actually can be resolved to an IP address. I ran that check on the Alexa Top 1 Million list. It gave me some interesting results. (This methodology has some limits, as it won't discover indirect src references or includes within javascript code, but it should be good enough to get a rough picture.)
Yahoo! Web Analytics was shut down in 2012, yet in 2017 Flickr still tried to use it
The webpage of Flickr included a script from Yahoo! Web Analytics. If you don't know Yahoo Analytics - that may be because it's been shut down in 2012. Although Flickr is a Yahoo! company it seems they haven't noted for quite a while. (The code is gone now, likely because I mentioned it on Twitter.) This example has no security impact as the domain still belongs to Yahoo. But it likely caused an unnecessary slowdown of page loads over many years.
Going through the list of domains I saw plenty of the things you'd expect: Typos, broken URLs, references to localhost and subdomains no longer in use. Sometimes I saw weird stuff, like references to javascript from browser extensions. My best explanation is that someone had a plugin installed that would inject those into pages and then created a copy of the page with the browser which later endet up being used as the real webpage.
I looked for abandoned domain names that might be worth registering. There weren't many. In most cases the invalid domains were hosts that didn't resolve, but that still belonged to someone. I found a few, but they were only used by one or two hosts.
Takeover of unregistered Azure subdomain
But then I saw a couple of domains referencing a javascript from a non-resolving host called piwiklionshare.azurewebsites.net. This is a subdomain from Microsoft's cloud service Azure. Conveniently Azure allows creating test accounts for free, so I was able to grab this subdomain without any costs.
Doing so allowed me to look at the HTTP log files and see what web pages included code from that subdomain. All of them were local newspapers from the US. 20 of them belonged to two adjacent IP addresses, indicating that they were all managed by the same company. I was able to contact them. While I never received any answer, shortly afterwards the code was gone from all those pages.
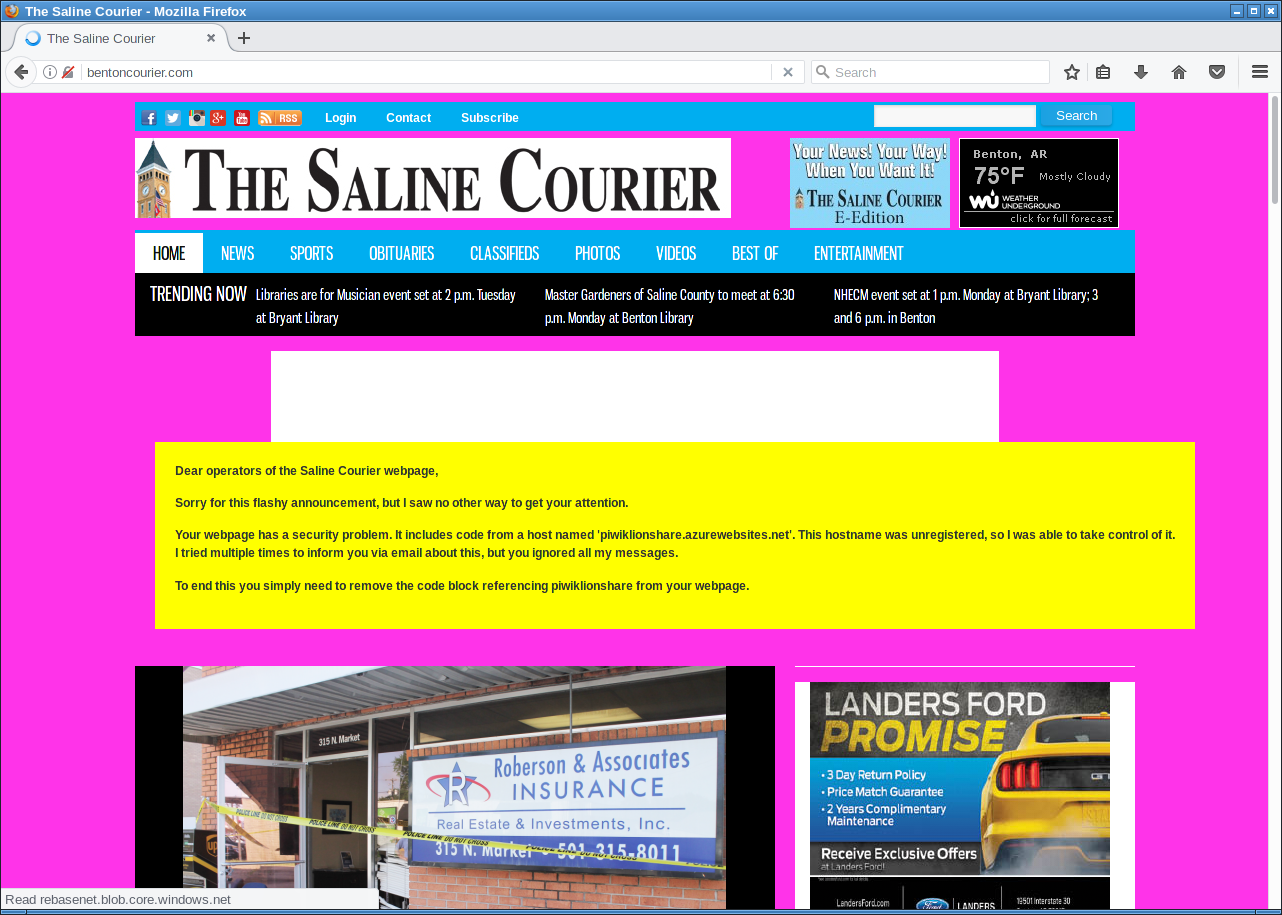
"Friendly defacement" of the Saline Courier.
After a while I wondered what I could do. Ultimately at some point Microsoft wouldn't let me host that subdomain any longer for free. I didn't want to risk that others could grab that subdomain, but at the same time I obviously also didn't want to pay in order to keep some web page safe whose owners didn't even bother to read my e-mails.
But of course I had another way of contacting them: I could execute Javascript on their web page and use that for some friendly defacement. After some contemplating whether that would be a legitimate thing to do I decided to go for it. I changed the background color to some flashy pink and send them a message. The page remained usable, but it was a message hard to ignore.
With some trouble on the way - first they broke their CSS, then they showed a PHP error message, then they reverted to the page with the defacement. But in the end they managed to remove the code.
There are still a couple of other pages that include that Javascript. Most of them however look like broken test webpages. The only legitimately looking webpage that still embeds that code is the Columbia Missourian. However they don't embed it on the start page, only on the error reporting form they have for every article. It's been several weeks now, they don't seem to care.
What happens to abandoned domains?
There are reasons to believe that what I showed here is only the tip of the iceberg. In many cases when services discontinue their domains don't simply disappear. If the domain name is valuable then almost certainly someone will try to register it immediately after it becomes available.
Someone trying to abuse abandoned domains could watch out for services going ot of business or widely referenced domains becoming available. Just to name an example: I found a couple of hosts referencing subdomains of compete.com. If you go to their web page, you can learn that the company Compete has discontinued its service in 2016. How long will they keep their domain? And what will happen with it afterwards? Whoever gets the domain can hijack all the web pages that still include javascript from it.
Be sure to know what you include
There are some obvious takeaways from this. If you include other peoples code on your web page then you should know what that means: You give them permission to execute whatever they want on your web page. This means you need to wonder how much you can trust them.
At the very least you should be aware who is allowed to execute code on your web page. If they shut down their business or discontinue the service you have been using then you obviously should remove that code immediately. And if you include code from a web statistics service that you never look at anyway you may simply want to remove that as well.