Wednesday, June 18. 2014
Should science journalists read the studies they write about?
Today I had a little twitter conversation which made me think about the responsibilities a science journalist has. It all started with a quote from Ivan Oransky (who is the editor of Retraction Watch) who said reporting on a study without reading it is 'journalist malpractice'. The source of this is another person who probably just heard him saying that, so I'm not sure what his exact words were.
Admittedly my first thought was: "He is right, too many journalists report about things they don't understand." My second thought was: "If he is right then I am probably guilty of 'journalist malpractice'." So I gave it a second thought and I probably won't agree with the statement any more.
I had a quick look at articles I wrote in the past and I have identified the last ten ones that more or less were coverages of a scientific piece of work. I have marked the ones I actually read with a [Y] and the ones I didn't read with a [N]. I've linked the appropriate scientific works and my articles (all in German). I must admit that I defined "read" widely, meaning that I haven't neccesarrily read the whole study/article in detail, I sometimes have just tried to parse the important parts for me.
Now the first thing that comes to mind is that I seem to have become lazier recently in reading studies. I hope this isn't the case and I hoestly think this is mostly coincidence. Now let's get into some details: The first example (the Turing Test) is interesting because it seems there is no scientific publication at all, just a press release. This probably tells you something about the quality of that "research", but while I read the press release I haven't even bothered to check if there is a scientific publication I could read.
The second example becomes interesting. I understand enough to know what a "quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic" actually is and I think I also understand what it means, but there's just no way I could understand the paper itself. This is complex mathematics. I seriously doubt that any journalist who covered this work actually read it. If there is I'd like to meet that person. I'm also very sure that the people who wrote the press release overselling this research have neither read this paper nor understood its implications.
I think this example gets to the point why I would disagree with the very general statement that a journalist should've read every scientific piece he writes about: It's sometimes so specialized that it's basically impossible. And I don't think this is an out of the line example. Just think about the Higgs Boson: Certainly this is something we want journalists to write about. But I'm pretty sure there are very few - if any - journalists who are able to read the scientific publications that are the basis of this discovery.
Some quick notes on the others: Number 4 was part of a 200-page-thesis and the press release was already pretty detailed and technically, I think it was legitimate to not read the original source in that case. Number 5 is somewhat similar to 2, because it is about an algorithm that includes complex math. Number 8 is not really a scientific paper, it is merely a news item on the Nature webpage. In the above list, the only case where I think maybe I should've read the scientific paper and I didn't is the Cochrane-Review on Tamiflu.
Conclusion: Don't get me wrong. I certainly welcome the idea that science journalists should have a look into the original scientific papers they write about more often - and this doesn't exclude myself. However, as shown above I doubt that this works in all cases.
Admittedly my first thought was: "He is right, too many journalists report about things they don't understand." My second thought was: "If he is right then I am probably guilty of 'journalist malpractice'." So I gave it a second thought and I probably won't agree with the statement any more.
I had a quick look at articles I wrote in the past and I have identified the last ten ones that more or less were coverages of a scientific piece of work. I have marked the ones I actually read with a [Y] and the ones I didn't read with a [N]. I've linked the appropriate scientific works and my articles (all in German). I must admit that I defined "read" widely, meaning that I haven't neccesarrily read the whole study/article in detail, I sometimes have just tried to parse the important parts for me.
- [X] Supposedly successful Turing Test taz, 2014-06-13
- [N]A quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic, Golem.de, 2014-05-17
- [N] Neuraminidase inhibitors for preventing and treating influenza in healthy adults and children (Cochrane-Review on Tamiflu), Neues Deutschland, 2014-04-26)
- [N] 20 Years of SSL/TLS Research: An Analysis of the Internet's Security Foundation, Golem.de, 2014-04-17
- [N] DRAFT FIPS 202 - SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions, Golem, 2014-04-05
- [Y] Using Frankencerts for Automated Adversarial Testing of Certificate Validation in SSL/TLS Implementations, Golem.de, 2014-04-04
- [Y] On the Practical Exploitability of Dual EC in TLS Implementations, Golem.de, 2014-04-01
- [Y] Publishers withdraw more than 120 gibberish papers, Golem.de, 2014-02-27
- [Y] Completeness of Reporting of Patient-Relevant Clinical Trial Outcomes: Comparison of Unpublished Clinical Study Reports with Publicly Available Data, taz, 2013-10-18
- [Y] Factoring RSA keys from certified smart cards: Coppersmith in the wild, Golem.de, 2013-09-17
Now the first thing that comes to mind is that I seem to have become lazier recently in reading studies. I hope this isn't the case and I hoestly think this is mostly coincidence. Now let's get into some details: The first example (the Turing Test) is interesting because it seems there is no scientific publication at all, just a press release. This probably tells you something about the quality of that "research", but while I read the press release I haven't even bothered to check if there is a scientific publication I could read.
The second example becomes interesting. I understand enough to know what a "quasi-polynomial algorithm for discrete logarithm in finite fields of small characteristic" actually is and I think I also understand what it means, but there's just no way I could understand the paper itself. This is complex mathematics. I seriously doubt that any journalist who covered this work actually read it. If there is I'd like to meet that person. I'm also very sure that the people who wrote the press release overselling this research have neither read this paper nor understood its implications.
I think this example gets to the point why I would disagree with the very general statement that a journalist should've read every scientific piece he writes about: It's sometimes so specialized that it's basically impossible. And I don't think this is an out of the line example. Just think about the Higgs Boson: Certainly this is something we want journalists to write about. But I'm pretty sure there are very few - if any - journalists who are able to read the scientific publications that are the basis of this discovery.
Some quick notes on the others: Number 4 was part of a 200-page-thesis and the press release was already pretty detailed and technically, I think it was legitimate to not read the original source in that case. Number 5 is somewhat similar to 2, because it is about an algorithm that includes complex math. Number 8 is not really a scientific paper, it is merely a news item on the Nature webpage. In the above list, the only case where I think maybe I should've read the scientific paper and I didn't is the Cochrane-Review on Tamiflu.
Conclusion: Don't get me wrong. I certainly welcome the idea that science journalists should have a look into the original scientific papers they write about more often - and this doesn't exclude myself. However, as shown above I doubt that this works in all cases.
Sunday, June 15. 2014
Slides from cryptography workshop for web developers
Friday, June 6. 2014
Enabling encryption by default and using HTTPS only
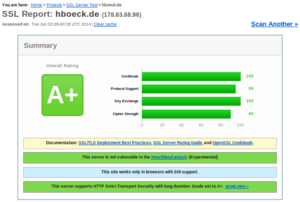 I recently switched my personal web page and my blog to deliver content exclusively encrypted via HTTPS. I want to take this opportunity to give some facts about enabling TLS encryption by default and problems you may face.
I recently switched my personal web page and my blog to deliver content exclusively encrypted via HTTPS. I want to take this opportunity to give some facts about enabling TLS encryption by default and problems you may face.First of all the non-problems: Enabling HTTPS by default is almost never a significant performance problem. If people tell me that they can not possibly enable HTTPS due to performance reasons the first thing I ask is if they believe this or if they have real benchmark data showing this. If you don't believe me on that, I can quote Adam Langley from Google here: "In January this year (2010), Gmail switched to using HTTPS for everything by default. Previously it had been introduced as an option, but now all of our users use HTTPS to secure their email between their browsers and Google, all the time. In order to do this we had to deploy no additional machines and no special hardware. On our production frontend machines, SSL/TLS accounts for less than 1% of the CPU load, less than 10KB of memory per connection and less than 2% of network overhead."
Enabling HTTPS may cause a number of compatibility issues you may not instantly think about. First of all, we know that IPs in the IPv4 space are limited and expensive these days, so many people probably can't afford having a distinct IP for their web page. The solution to that is a TLS extension called SNI (Server Name Indication) which allows to have different certificates for different domain names on the same IP. It works in all major browsers and has been working for quite some time. The only major browser you'll face these days that doesn't support SNI is the Android 2.x browser.
There are some subtle issues with SNI. One is that browsers have fallback modes if they cannot connect via TLS and that may lead to a connection downgrade to SSLv3. And that ancient protocol doesn't support extensions and thus no SNI. So you may have irregular certificate errors if you are on a bad connection. A solution to that on the server side is to just disable SSLv3. It will make SNI much more reliable.
I don't really have a clear picture how many browsers will fail with SNI. There are probably a number of embedded devices out there like smart TVs with browsers or things alike that have problems. If you have any experiences feel free to post them in the comments.
The first issue I only noticed after I switched to HTTPS: I had an application called RSS Graffiti set up to automatically post all articles I write to a facebook fan page. After changing to HTTPS only it silently stopped working. Re-adding my feed didn't work. I now found a similar service called dlvr.it that I now use to post my RSS feed to facebook. I can only assume that this is a glimpse of a much bigger problem: There are probably tons of applications and online services out there not prepared for an encrypted Internet. If we want more people to deploy encryption by default we need to find these issues, document them and hopefully put enough pressure on their developers to fix them.
Another yet unfixed issue is the Yandex Bot. Yandex is a search engine and although you may never have heard of it it's probably one of the few companies in this area that can claim to be a serious competitor to Google. The reason you may not know it is that it's mostly operating in Russian language. Depending on who your page visitors are this may matter more or less.
The Yandex Bot speaks SSL but according to the Qualys SSL test it only supports the ancient SSLv3. So you have a choice between three possibilities: Don't enable HTTPS by default, enable HTTPS with a shitty configuration supporting ancient technology that will cause trouble for SNI or enable HTTPS with a sane configuration and get no traffic from the leading Russian search engine. None of them sounds very good to me.
Another issue is third party content. For security reasons today's browsers block all active HTTP content (CSS, JavaScript etc.) on HTTPS webpages. This isn't much of a problem for me, but it's a problem for webpages that rely on advertising because from what I hear most advertisement providers don't support HTTPS yet (Google being a laudable exception here). This is the main reason you won't see many news webpages enforcing HTTPS. However, I still have passive third party HTTP content on my blog. That's why you'll probably see a yellow warning sign in front of the URL in some browsers.